一、kube-scheduler 详解
1. kube-scheduler 调度概述
在 Kubernetes 中,调度是指将 Pod 放置到合适的 Node 节点上,然后对应 Node 上的 Kubelet 才能够运行这些 pod。
调度器通过 kubernetes 的 watch 机制来发现集群中新创建且尚未被调度到 Node 上的 Pod。调度器会将发现的每一个未调度的 Pod 调度到一个合适的 Node 上来运行。调度器会依据下文的调度原则来做出调度选择。
调度是容器编排的重要环节,需要经过严格的监控和控制,现实生产通常对调度有各类限制,譬如某些服务必须在业务独享的机器上运行,或者从灾备的角度考虑尽量把服务调度到不同机器,这些需求在Kubernetes集群依靠调度组件kube-scheduler满足。
kube-scheduler 是 Kubernetes 中的关键模块,扮演管家的角色遵从一套机制——为Pod提供调度服务,例如基于资源的公平调度、调度Pod到指定节点、或者通信频繁的Pod调度到同一节点等。容器调度本身是一件比较复杂的事,因为要确保以下几个目标:
- 公平性:在调度 Pod 时需要公平的进行决策,每个节点都有被分配资源的机会,调度器需要对不同节点的使用作出平衡决策。
- 资源高效利用:最大化群集所有资源的利用率,使有限的 CPU、内存等资源服务尽可能更多的 Pod。
- 效率问题:能快速的完成对大批量 Pod 的调度工作,在集群规模扩增的情况下,依然保证调度过程的性能。
- 灵活性:在实际运作中,用户往往希望Pod的调度策略是可控的,从而处理大量复杂的实际问题。因此平台要允许多个调度器并行工作,同时支持自定义调度器。
为达到上述目标,kube-scheduler 通过结合 Node 资源、负载情况、数据位置等各种因素进行调度判断,确保在满足场景需求的同时将Pod 分配到最优节点。显然,kube-scheduler 影响着 Kubernetes 集群的可用性与性能,Pod 数量越多集群的调度能力越重要,尤其达到了数千级节点数时,优秀的调度能力将显著提升容器平台性能。
2. kube-scheduler 调度流程
kube-scheduler的根本工作任务是根据各种调度算法将Pod绑定(bind)到最合适的工作节点,整个调度流程分为两个阶段:预选策略(Predicates)和优选策略(Priorities)。
- 预选(Predicates):输入是所有节点,输出是满足预选条件的节点。kube-scheduler 根据预选策略过滤掉不满足策略的 Nodes。例如,如果某节点的资源不足或者不满足预选策略的条件如 “ Node 的 label 必须与 Pod 的 Selector 一致”时则无法通过预选。
- 优选(Priorities):输入是预选阶段筛选出的节点,优选会根据优先策略为通过预选的 Nodes 进行打分排名,选择得分最高的Node。例如,资源越富裕、负载越小的 Node 可能具有越高的排名。
通俗点说,调度的过程就是在回答两个问题:1. 候选有哪些?2. 其中最适合的是哪个?
值得一提的是,如果在预选阶段没有节点满足条件,Pod会一直处在Pending状态直到出现满足的节点,在此期间调度器会不断的进行重试。
2.1 预选策略(Predicates)
官网地址:调度器预选、优选策略
过滤条件包含如下:
- PodFitsHostPorts:检查 Pod 容器所需的 HostPort 是否已被节点上其它容器或服务占用。如果已被占用,则禁止 Pod 调度到该节点。
- PodFitsHost:检查 Pod 指定的 NodeName 是否匹配当前节点。
- PodFitsResources:检查节点是否有足够空闲资源(例如 CPU 和内存)来满足 Pod 的要求。
- PodMatchNodeSelector:检查 Pod 的节点选择器( nodeSelector )是否与节点( Node )的标签匹配
- NoVolumeZoneConflict:对于给定的某块区域,判断如果在此区域的节点上部署 Pod 是否存在卷冲突。
- NoDiskConflict:根据节点请求的卷和已经挂载的卷,评估 Pod 是否适合该节点。
- MaxCSIVolumeCount:决定应该附加多少 CSI 卷,以及该卷是否超过配置的限制。
- CheckNodeMemoryPressure:如果节点报告内存压力,并且没有配置异常,那么将不会往那里调度 Pod。
- CheckNodePIDPressure:如果节点报告进程 id 稀缺,并且没有配置异常,那么将不会往那里调度 Pod。
- CheckNodeDiskPressure:如果节点报告存储压力(文件系统已满或接近满),并且没有配置异常,那么将不会往那里调度 Pod。
- CheckNodeCondition:节点可以报告它们有一个完全完整的文件系统,然而网络不可用,或者 kubelet 没有准备好运行 Pods。如果为节点设置了这样的条件,并且没有配置异常,那么将不会往那里调度 Pod。
- PodToleratesNodeTaints:检查 Pod 的容忍度是否能容忍节点的污点。
- CheckVolumeBinding:评估 Pod 是否适合它所请求的容量。这适用于约束和非约束 PVC。
如果在predicates(预选)过程中没有合适的节点,那么Pod会一直在pending状态,不断重试调度,直到有节点满足条件。
经过这个步骤,如果有多个节点满足条件,就继续priorities过程,最后按照优先级大小对节点排序。
2.2 优选策略(Priorities)
包含如下优选评分条件:
- SelectorSpreadPriority:对于属于同一服务、有状态集或副本集(Service,StatefulSet or ReplicaSet)的Pods,会将Pods尽量分散到不同主机上。
- InterPodAffinityPriority:策略有podAffinity和podAntiAffinity两种配置方式。简单来说,就说根据Node上运行的Pod的Label来进行调度匹配的规则,匹配的表达式有:In, NotIn, Exists, DoesNotExist,通过该策略,可以更灵活地对Pod进行调度。
- LeastRequestedPriority:偏向使用较少请求资源的节点。换句话说,放置在节点上的Pod越多,这些Pod使用的资源越多,此策略给出的排名就越低。
- MostRequestedPriority:偏向具有最多请求资源的节点。这个策略将把计划的Pods放到整个工作负载集所需的最小节点上运行。
- RequestedToCapacityRatioPriority:使用默认的资源评分函数模型创建基于ResourceAllocationPriority的requestedToCapacity。
- BalancedResourceAllocation:偏向具有平衡资源使用的节点。
- NodePreferAvoidPodsPriority:根据节点注释scheduler.alpha.kubernet .io/preferAvoidPods为节点划分优先级。可以使用它来示意两个不同的Pod不应在同一Node上运行。
- NodeAffinityPriority:根据preferredduringschedulingignoredingexecution中所示的节点关联调度偏好来对节点排序。
- TaintTolerationPriority:根据节点上无法忍受的污点数量,为所有节点准备优先级列表。此策略将考虑该列表调整节点的排名。
- ImageLocalityPriority:偏向已经拥有本地缓存Pod容器镜像的节点。
- ServiceSpreadingPriority:对于给定的服务,此策略旨在确保Service的Pods运行在不同的节点上。总的结果是,Service对单个节点故障变得更有弹性。
- EqualPriority:赋予所有节点相同的权值1。
- EvenPodsSpreadPriority:实现择优 pod的拓扑扩展约束
2.3 自定义调度器
除了Kubernetes自带的调度器,我们也可以编写自己的调度器。通过spec.schedulername参数指定调度器名字,可以为Pod选择某个调度器进行调度。
# 在 kubernetes Master 节点开启 apiServer 的代理
$ kubectl proxy --port=8001基于 shell 编写一个自定义调度器
vi my-scheduler.sh
!/bin/bash
SERVER='localhost:8001'
while true;
do
for PODNAME in $(kubectl --server $SERVER get pods -o json | jq '.items[] | select(.spec.schedulerName =="my-scheduler") | select(.spec.nodeName == null) | .metadata.name' | tr -d '"')
do
NODES=($(kubectl --server $SERVER get nodes -o json | jq '.items[].metadata.name' | tr -d '"'))
NUMNODES=${#NODES[@]}
CHOSEN=${NODES[$[ $RANDOM % $NUMNODES]]}
curl --header "Content-Type:application/json" --request POST --data '{"apiVersion":"v1","kind":"Binding","metadata": {"name":"'$PODNAME'"},"target": {"apiVersion":"v1","kind": "Node", "name": "'$CHOSEN'"}}' http://$SERVER/api/v1/namespaces/default/pods/$PODNAME/binding/
echo "Assigned $PODNAME to $CHOSEN"
done
sleep 1
done如下Pod选择my-scheduler进行调度,而不是默认的default-scheduler
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: myapp
name: myapp
spec:
replicas: 1
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
schedulerName: my-scheduler
containers:
- image: wangyanglinux/myapp:v1.0
name: myapp自定义调度器在日常工作中几乎不会用到。
二、亲和性和反亲和性
主机配置规划
| 服务器名称(hostname) | 系统版本 | 配置 | 内网IP |
|---|---|---|---|
| k8s-master | Rocky 9.3 | 2C/4G/100G | 192.168.142.199 |
| k8s-node01 | Rocky 9.3 | 2C/4G/100G | 192.168.142.201 |
| k8s-node02 | Rocky 9.3 | 2C/4G/100G | 192.168.142.202 |
1. 概述
nodeSelector提供了一种非常简单的方法,将pods约束到具有特定标签的节点。而亲和性/反亲和性极大地扩展了可表达的约束类型。关键的增强是:
- 亲和性/反亲和性语言更具表达性。除了使用逻辑AND操作创建的精确匹配之外,该语言还提供了更多的匹配规则;
- 可以指示规则是优选项而不是硬要求,因此如果调度器不能满足,pod仍将被调度;
- 可以针对节点(或其他拓扑域)上运行的 pods 的标签进行约束,而不是针对节点的自身标签,这影响哪些 Pod 可以或不可以共处。
亲和特性包括两种类型:node节点亲和性/反亲和性 和 pod亲和性/反亲和性。pod亲和性/反亲和性约束针对的是pod标签而不是节点标签。
拓扑域是什么:多个node节点,拥有相同的label标签【节点标签的键值相同】,那么这些节点就处于同一个拓扑域。
2. Node 节点亲和性
2.1 相关概念
当前有两种类型的节点亲和性,称为 requiredDuringSchedulingIgnoredDuringExecution 和 preferredDuringSchedulingIgnoredDuringExecution ,可以将它们分别视为“硬策略”【必须满足条件】和“软策略”【优选满足条件】要求。
前者表示Pod要调度到的节点必须满足规则条件,不满足则不会调度,pod会一直处于Pending状态;后者表示优先调度到满足规则条件的节点,如果不能满足再调度到其他节点。
名称中的 IgnoredDuringExecution 部分意味着,与 nodeSelector 的工作方式类似,如果节点上的标签在 Pod 运行时发生更改,使得pod 上的亲和性规则不再满足,那么 pod 仍将继续在该节点上运行。
在未来,会计划提供 requiredDuringSchedulingRequiredDuringExecution ,类似 requiredDuringSchedulingIgnoredDuringExecution 。不同之处就是 pod 运行过程中如果节点不再满足 pod 的亲和性,则 pod 会在该节点中逐出。
节点亲和性语法支持以下运算符:In,NotIn,Exists,DoesNotExist,Gt,Lt。可以使用 NotIn 和 DoesNotExist 实现节点的反亲和行为。
运算符关系:
- In:label 的值在某个列表中
- NotIn:label 的值不在某个列表中
- Gt:label 的值大于某个值
- Lt:label 的值小于某个值
- Exists:某个label 存在
- DoesNotExist:某个 label 不存在
2.2 节点亲和性重要说明
如果同时指定 nodeSelector 和 nodeAffinity ,则必须满足两个条件,才能将 Pod 调度到候选节点上。
如果在 nodeAffinity 类型下指定了多个 nodeSelectorTerms 对象【对象不能有多个,如果存在多个只有最后一个生效】,那么只有最后一个 nodeSelectorTerms 对象生效。
如果在 nodeSelectorTerms 下指定了多个 matchExpressions 列表,那么只要能满足其中一个 matchExpressions ,就可以将 pod 调度到某个节点上【针对节点硬亲和】。
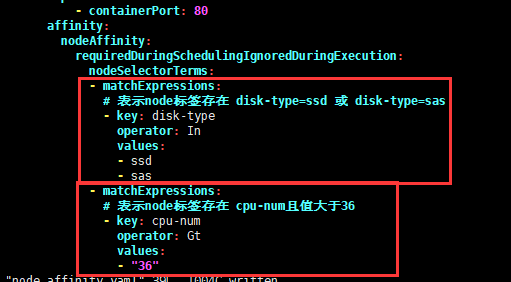
如果在 matchExpressions下有多个 key 列表,那么只有当所有 key 满足时,才能将 pod 调度到某个节点【针对硬亲和】。
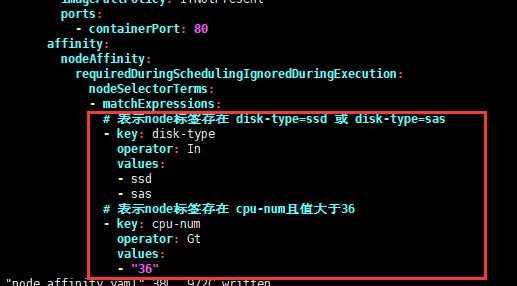
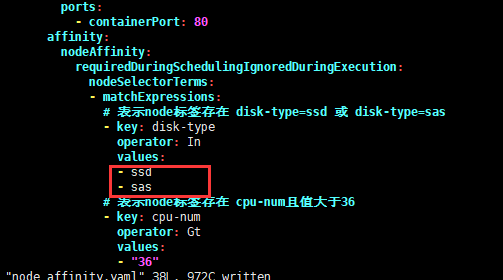
在key下的values只要有一个满足条件,那么当前的key就满足条件
如果 pod 已经调度在该节点,当我们删除或修该节点的标签时,pod 不会被移除。换句话说,亲和性选择只有在 pod 调度期间有效。
preferredDuringSchedulingIgnoredDuringExecution中的 weight(权重)字段在1-100范围内。对于每个满足所有调度需求的节点(资源请求、RequiredDuringScheduling 亲和表达式等),调度器将通过迭代该字段的元素来计算一个总和,如果节点与相应的匹配表达式匹配,则向该总和添加“权重”。然后将该分数与节点的其他优先级函数的分数结合起来。总得分最高的节点是最受欢迎的。
2.3 节点亲和性示例
2.3.1 准备事项
给node节点打label标签
# 查看当前集群节点列表
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-node01 Ready <none> 76d v1.29.15
k8s-node02 Ready <none> 76d v1.29.15
node Ready control-plane 76d v1.29.15
# 1.给node01节点打标签
### --overwrite覆盖已存在的标签信息
$ kubectl label nodes k8s-node01 disk-type=ssd --overwrite
node/k8s-node01 labeled
$ kubectl label nodes k8s-node01 cpu-num=12
node/k8s-node01 labeled
# 2.给node02节点打标签
$ kubectl label nodes k8s-node02 disk-type=sata --overwrite
node/k8s-node02 labeled
$ kubectl label nodes k8s-node02 cpu-num=24
node/k8s-node02 labeled查询所有节点标签信息
$ kubectl get node --show-labels
NAME STATUS ROLES AGE VERSION LABELS
k8s-node01 Ready <none> 76d v1.29.15 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,cpu-num=12,disk-type=ssd,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node01,kubernetes.io/os=linux
k8s-node02 Ready <none> 76d v1.29.15 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,cpu-num=24,disk-type=sata,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node02,kubernetes.io/os=linux
node Ready control-plane 76d v1.29.15 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node.kubernetes.io/exclude-from-external-load-balancers=2.3.2 节点硬亲和性示例
必须满足条件才能调度,否则不会调度
资源清单:node_required_affinity.yaml
kind: Deployment
apiVersion: apps/v1
metadata:
name: node-affinity-deploy
labels:
app: nodeaffinity-deploy
spec:
replicas: 5
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: nginx
image: wangyanglinux/myapp:v1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
name: web
protocol: TCP
affinity: # 亲和性
nodeAffinity: # 节点亲和性
requiredDuringSchedulingIgnoredDuringExecution: # 节点硬亲和性
nodeSelectorTerms:
- matchExpressions:
# 表示node标签存在 disk-type=ssd 或 disk-type=sas
- key: disk-type
operator: In
values:
- ssd
- sas
# 表示node标签存在 cpu-num且值大于6
- key: cpu-num
operator: Gt
values:
- "6"执行资源清单,并查看状态
# 执行资源清单,创建Deployment 和 Pod
$ kubectl apply -f node_required_affinity.yaml
# 查看Deployment控制器
$ kubectl get deploy -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
node-affinity-deploy 5/5 5 5 9s nginx wangyanglinux/myapp:v1.0 app=myapp
# 查看Pod
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
node-affinity-deploy-7f4f994b48-747jn 1/1 Running 0 31s 192.168.85.244 k8s-node01 <none> <none>
node-affinity-deploy-7f4f994b48-8cvx8 1/1 Running 0 31s 192.168.85.243 k8s-node01 <none> <none>
node-affinity-deploy-7f4f994b48-9rcs6 1/1 Running 0 31s 192.168.85.240 k8s-node01 <none> <none>
node-affinity-deploy-7f4f994b48-dckdb 1/1 Running 0 31s 192.168.85.241 k8s-node01 <none> <none>
node-affinity-deploy-7f4f994b48-fmmbf 1/1 Running 0 31s 192.168.85.242 k8s-node01 <none> <none>
# 查看rs
$ kubectl get rs -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
node-affinity-deploy-7f4f994b48 5 5 5 3m46s nginx wangyanglinux/myapp:v1.0 app=myapp,pod-template-hash=7f4f994b48由上可见,由于节点硬亲和性的限制,Pod 都运行到了 k8s-node01 节点上了,即便是删除 Pod 重新创建新的Pod,依然会运行到 k8s-node01 节点上。
# 删除 Pod
$ kubectl delete pod node-affinity-deploy-7f4f994b48-747jn
pod "node-affinity-deploy-7f4f994b48-747jn" deleted
# 再次查看Pod
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
node-affinity-deploy-7f4f994b48-8cvx8 1/1 Running 0 5m57s 192.168.85.243 k8s-node01 <none> <none>
node-affinity-deploy-7f4f994b48-9rcs6 1/1 Running 0 5m57s 192.168.85.240 k8s-node01 <none> <none>
node-affinity-deploy-7f4f994b48-dckdb 1/1 Running 0 5m57s 192.168.85.241 k8s-node01 <none> <none>
node-affinity-deploy-7f4f994b48-fmmbf 1/1 Running 0 5m57s 192.168.85.242 k8s-node01 <none> <none>
node-affinity-deploy-7f4f994b48-r22mr 1/1 Running 0 6s 192.168.85.245 k8s-node01 <none> <none>2.3.3 节点软亲和性示例
优先调度到满足条件的节点,如果都不满足也会调度到其他节点。
资源清单:node_preferred_affinity.yaml
kind: Deployment
apiVersion: apps/v1
metadata:
name: node-affinity-deploy
labels:
app: nodeaffinity-deploy
spec:
replicas: 5
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: nginx
image: wangyanglinux/myapp:v1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
name: web
protocol: TCP
affinity: # 亲和性
nodeAffinity: # 节点亲和性
preferredDuringSchedulingIgnoredDuringExecution: # 节点软亲和性
- weight: 1 # 权重,范围 1-100
preference:
matchExpressions:
# 表示node标签存在 disk-type=ssd 或 disk-type=sas
- key: disk-type
operator: In
values:
- ssd
- sas
- weight: 50 # 权重,范围 1-100
preference:
matchExpressions:
# 表示node标签存在 cpu-num且值大于16
- key: cpu-num
operator: Gt
values:
- "16"执行资源清单,并查看状态
# 运行资源清单,创建Deployment
$ kubectl apply -f node_preferred_affinity.yaml
# 查看 Deployment
$ kubectl get deployment -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
node-affinity-deploy 5/5 5 5 6s nginx wangyanglinux/myapp:v1.0 app=myapp
# 查看 RS
$ kubectl get rs -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
node-affinity-deploy-649bb7b9cf 5 5 5 12s nginx wangyanglinux/myapp:v1.0 app=myapp,pod-template-hash=649bb7b9cf
# 查看 Pod详情
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
node-affinity-deploy-649bb7b9cf-7mj7p 1/1 Running 0 19s 192.168.58.239 k8s-node02 <none> <none>
node-affinity-deploy-649bb7b9cf-9q56z 1/1 Running 0 19s 192.168.58.242 k8s-node02 <none> <none>
node-affinity-deploy-649bb7b9cf-b7gtd 1/1 Running 0 19s 192.168.58.240 k8s-node02 <none> <none>
node-affinity-deploy-649bb7b9cf-qp775 1/1 Running 0 19s 192.168.58.238 k8s-node02 <none> <none>
node-affinity-deploy-649bb7b9cf-ztkl8 1/1 Running 0 19s 192.168.58.241 k8s-node02 <none> <none>由于 Node 软亲和性的限制,可以推断出 Pod 会运行在 k8s-node02 节点上。
2.3.4 节点硬亲和性 和 软亲和性联合示例
资源清单:node_affinity.yaml
kind: Deployment
apiVersion: apps/v1
metadata:
name: node-affinity-deploy
labels:
app: nodeaffinity-deploy
spec:
replicas: 5
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: nginx
image: wangyanglinux/myapp:v1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
name: web
protocol: TCP
affinity: # 亲和性
nodeAffinity: # 节点亲和性
requiredDuringSchedulingIgnoredDuringExecution: # 节点硬亲和性
nodeSelectorTerms:
- matchExpressions:
# 表示node标签存在 cpu-num且值大于10
- key: cpu-num
operator: Gt
values:
- "10"
preferredDuringSchedulingIgnoredDuringExecution: # 节点软亲和性
- weight: 50 # 权重,范围 1-100
preference:
matchExpressions:
# 表示node标签存在 disk-type=ssd 或 disk-type=sas
- key: disk-type
operator: In
values:
- ssd
- sas执行资源清单并查看状态
# 运行资源清单,创建Deployment
$ kubectl apply -f node_affinity.yaml
deployment.apps/node-affinity-deploy created
# 查看 Deployment
$ kubectl get deployment -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
node-affinity-deploy 5/5 5 5 6s nginx wangyanglinux/myapp:v1.0 app=myapp
# 查看 RS
$ kubectl get rs -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
node-affinity-deploy-5498f54ffc 5 5 5 10s nginx wangyanglinux/myapp:v1.0 app=myapp,pod-template-hash=5498f54ffc
# 查看 Pod 详情
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
node-affinity-deploy-5498f54ffc-dcp9v 1/1 Running 0 13s 192.168.85.248 k8s-node01 <none> <none>
node-affinity-deploy-5498f54ffc-kkss7 1/1 Running 0 13s 192.168.85.250 k8s-node01 <none> <none>
node-affinity-deploy-5498f54ffc-nd6sb 1/1 Running 0 13s 192.168.85.247 k8s-node01 <none> <none>
node-affinity-deploy-5498f54ffc-p5x2t 1/1 Running 0 13s 192.168.85.249 k8s-node01 <none> <none>
node-affinity-deploy-5498f54ffc-r5pbd 1/1 Running 0 13s 192.168.85.246 k8s-node01 <none> <none>从资源清单可以看出,节点的硬亲和要求,k8s-node01 与 k8s-node02 都满足要求,节点的软亲和只有 k8s-node01 满足,所以 Pod 优先调度到 k8s-node01 节点上。
3. Pod 亲和性 / 反亲和性
3.1 相关概念
与节点亲和性一样,当前有Pod亲和性/反亲和性都有两种类型,称为 requiredDuringSchedulingIgnoredDuringExecution 和 preferredDuringSchedulingIgnoredDuringExecution,分别表示“硬”与“软”要求。对于硬要求,如果不满足则pod会一直处于Pending状态。
Pod 的亲和性与反亲和性是基于 Node 节点上已经运行 pod 的标签(而不是节点上的标签)决定的,从而约束哪些节点适合调度你的 pod。
规则的形式是:如果X已经运行了一个或多个符合规则Y的pod,则此pod应该在X中运行(如果是反亲和的情况下,则不应该在X中运行)。当然pod必须处在同一名称空间,不然亲和性/反亲和性无作用。从概念上讲,X是一个拓扑域。我们可以使用topologyKey来表示它,topologyKey 的值是node节点标签的键以便系统用来表示这样的拓扑域。当然这里也有个隐藏条件,就是node节点标签的键值相同时,才是在同一拓扑域中;如果只是节点标签名相同,但是值不同,那么也不在同一拓扑域。
也就是说:Pod的亲和性/反亲和性调度是根据拓扑域来界定调度的,而不是根据node节点。
注意事项
- Pod 之间亲和性/反亲和性需要大量的处理,这会明显降低大型集群中的调度速度。不建议在大于几百个节点的集群中使用它们。
- Pod 反亲和性要求对节点进行一致的标记。换句话说,集群中的每个节点都必须有一个匹配 topologyKey 的适当标签。如果某些或所有节点缺少指定的topologyKey 标签,可能会导致意外行为。
requiredDuringSchedulingIgnoredDuringExecution 中亲和性的一个示例是“将服务A和服务B的Pod放置在同一区域【拓扑域】中,因为它们之间有很多交流”; preferredDuringSchedulingIgnoredDuringExecution 中反亲和性的示例是“将此服务的 pod 跨区域【拓扑域】分布”【此时硬性要求是说不通的,因为你可能拥有的 pod 数多于区域数】。
Pod 亲和性/反亲和性语法支持以下运算符:In,NotIn,Exists,DoesNotExist。
原则上,topologyKey可以是任何合法的标签键。但是,出于性能和安全方面的原因,topologyKey有一些限制:
- 对于 Pod 亲和性,在 requiredDuringSchedulingIgnoredDuringExecution 和 preferredDuringSchedulingIgnoredDuringExecution 中 topologyKey 都不允许为空。
- 对于 Pod 反亲和性,在 requiredDuringSchedulingIgnoredDuringExecution 和 preferredDuringSchedulingIgnoredDuringExecution 中 topologyKey 也都不允许为空。
- 对于 requiredDuringSchedulingIgnoredDuringExecution 的 pod 反亲和性,引入了允许控制器 LimitPodHardAntiAffinityTopology 来限制 topologyKey 的kubernet.io/hostname 。如果你想让它对自定义拓扑可用,你可以修改许可控制器,或者干脆禁用它。
- 除上述情况外,topologyKey 可以是任何合法的标签键。
Pod 间亲和通过 PodSpec 中 affinity 字段下的 podAffinity 字段进行指定。而 pod 间反亲和通过 PodSpec 中 affinity 字段下的 podAntiAffinity 字段进行指定。
Pod亲和性/反亲和性的requiredDuringSchedulingIgnoredDuringExecution所关联的matchExpressions下有多个key列表,那么只有当所有key满足时,才能将pod调度到某个区域【针对Pod硬亲和】。
3.2 pod亲和性与反亲和性示例
为了更好的演示Pod亲和性与反亲和性,本次示例我们会将k8s-master节点也加入进来进行演示。
3.2.1 准备事项
给 node 节点打 label 标签
# 删除已存在标签
kubectl label nodes k8s-node01 cpu-num-
kubectl label nodes k8s-node01 disk-type-
kubectl label nodes k8s-node02 cpu-num-
kubectl label nodes k8s-node02 disk-type-
### --overwrite覆盖已存在的标签信息
# master节点 标签添加(master节点的名称叫做 node)
kubectl label nodes node busi-use=www --overwrite
kubectl label nodes node disk-type=ssd --overwrite
kubectl label nodes node busi-db=redis
# k8s-node01 标签添加
kubectl label nodes k8s-node01 busi-use=www
kubectl label nodes k8s-node01 disk-type=sata
kubectl label nodes k8s-node01 busi-db=redis
# k8s-node02 标签添加
kubectl label nodes k8s-node02 busi-use=www
kubectl label nodes k8s-node02 disk-type=ssd
kubectl label nodes k8s-node02 busi-db=etcd查询所有节点标签信息
$ kubectl get node -o wide --show-labels
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME LABELS
k8s-node01 Ready <none> 69d v1.29.15 192.168.6.140 <none> Rocky Linux 9.3 (Blue Onyx) 5.14.0-362.8.1.el9_3.x86_64 docker://28.0.4 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,busi-db=redis,busi-use=www,disk-type=sata,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node01,kubernetes.io/os=linux
k8s-node02 Ready <none> 69d v1.29.15 192.168.6.141 <none> Rocky Linux 9.3 (Blue Onyx) 5.14.0-362.8.1.el9_3.x86_64 docker://28.0.4 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,busi-db=etcd,busi-use=www,disk-type=ssd,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node02,kubernetes.io/os=linux
node Ready control-plane 69d v1.29.15 192.168.6.139 <none> Rocky Linux 9.3 (Blue Onyx) 5.14.0-362.8.1.el9_3.x86_64 docker://28.0.4 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,busi-db=redis,busi-use=www,disk-type=ssd,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-master01,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node.kubernetes.io/exclude-from-external-load-balancers=master 节点添加了 disk-type=ssd, busi-db=redis, busi-use=www 标签
k8s-node01 添加了 disk-type=sata, busi-db=redis, busi-use=www 标签
k8s-node02 添加了 disk-type=ssd, busi-db=etcd, busi-use=www 标签
通过 deployment 运行一个 pod,或者直接运行一个 pod 也可以。为后续的 Pod 亲和性与反亲和性测验做基础。
演示Pod资源清单:web_deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-deploy
labels:
app: myweb-deploy
spec:
replicas: 1
selector:
matchLabels:
app: myapp-web
template:
metadata:
labels:
app: myapp-web
version: v1
spec:
containers:
- name: myapp-pod
image: wangyanglinux/myapp:v1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80执行资源清单
# 执行资源清单,创建Pod
$ kubectl apply -f web_deploy.yaml
# 获取Pod
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-deploy-7b868c54f5-x78hw 1/1 Running 0 17s 172.16.58.243 k8s-node02 <none> <none>
# 查看 k8s-node02 节点标签
$ kubectl get node k8s-node02 -o wide --show-labels
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME LABELS
k8s-node02 Ready <none> 69d v1.29.15 192.168.6.141 <none> Rocky Linux 9.3 (Blue Onyx) 5.14.0-362.8.1.el9_3.x86_64 docker://28.0.4 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,busi-db=etcd,busi-use=www,disk-type=ssd,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node02,kubernetes.io/os=linux当前 pod 在 k8s-node02 节点;其中 pod 的标签 app=myapp-web,version=v1 会在后面 pod 亲和性/反亲和性示例中使用。
3.2.2 pod 硬亲和性示例
资源清单:pod_required_affinity.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: pod-podaffinity-deploy
labels:
app: podaffinity-deploy
spec:
replicas: 6
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
tolerations: # 配置容忍,允许运行到 Master 节点上
- key: node-role.kubernetes.io/control-plane
effect: NoSchedule
containers:
- name: myapp-pod
image: wangyanglinux/myapp:v1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
# 由于是Pod亲和性/反亲和性, 因此这里匹配规则写的是Pod的标签信息
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- myapp-web
# 拓扑域 若多个node节点具有相同的标签信息【标签键值相同】,则表示这些node节点就在同一拓扑域
topologyKey: disk-type执行资源清单
# 执行资源清单,创建Pod
$ kubectl apply -f pod_required_affinity.yaml
# 查看 Deployment
$ kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
pod-podaffinity-deploy 6/6 6 6 7s
web-deploy 1/1 1 1 27m
# 查看 Pod
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-podaffinity-deploy-6b588d4649-2ztpj 1/1 Running 0 13s 172.16.167.133 node <none> <none>
pod-podaffinity-deploy-6b588d4649-7pghc 1/1 Running 0 13s 172.16.58.208 k8s-node02 <none> <none>
pod-podaffinity-deploy-6b588d4649-d68kl 1/1 Running 0 13s 172.16.167.131 node <none> <none>
pod-podaffinity-deploy-6b588d4649-dpnzg 1/1 Running 0 13s 172.16.58.228 k8s-node02 <none> <none>
pod-podaffinity-deploy-6b588d4649-qjbwn 1/1 Running 0 13s 172.16.58.251 k8s-node02 <none> <none>
pod-podaffinity-deploy-6b588d4649-vcvhg 1/1 Running 0 13s 172.16.167.132 node <none> <none>
web-deploy-7b868c54f5-x78hw 1/1 Running 0 27m 172.16.58.243 k8s-node02 <none> <noneyaml 文件中为 topologyKey: disk-type;虽然 k8s-master、k8s-node01、k8s-node02 都有 disk-type 标签;但是 k8s-master 和 k8s-node02 节点的 disk-type 标签值为 ssd;而 k8s-node01 节点的 disk-type 标签值为 sata。因此 k8s-master 和 k8s-node02 节点属于同一拓扑域,Pod 只会调度到这两个节点上。
补充说明:因为 设置了 Pod 硬亲和,匹配运行了包含标签为 app: myapp-web 的 Pod 所在的 Node 节点(k8s-node02),而 k8s-node02 节点 topologyKey disk-type 为 ssd,而 topologyKey 满足 disk-type=ssd 的只有 master 节点和 k8s-node02.
3.2.3 pod 软亲和性示例
资源清单:pod_preferred_affinity.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: pod-podaffinity-deploy
labels:
app: podaffinity-deploy
spec:
replicas: 6
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
tolerations: # 配置容忍,允许运行到 Master 节点上
- key: node-role.kubernetes.io/control-plane
effect: NoSchedule
containers:
- name: myapp-pod
image: wangyanglinux/myapp:v1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
affinity:
podAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100 # 权重(1-100)
podAffinityTerm:
# 由于是Pod亲和性/反亲和性,因此这里匹配规则写的是Pod的标签信息
labelSelector:
matchExpressions:
- key: version
operator: In
values:
- v1
- v2
# 拓扑域 若多个node节点具有相同的标签信息【标签键值相同】,则表示这些node节点就在同一拓扑域
topologyKey: disk-type运行yaml文件并查看状态
# 运行资源清单,创建deploy 和 Pod
$ kubectl apply -f pod_preferred_affinity.yaml
# 查看deploy
$ kubectl get deploy -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
pod-podaffinity-deploy 6/6 6 6 17s myapp-pod wangyanglinux/myapp:v1.0 app=myapp
web-deploy 1/1 1 1 13h myapp-pod wangyanglinux/myapp:v1.0 app=myapp-web
# 查看 Pod
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-podaffinity-deploy-6d486b88bf-2lx4m 1/1 Running 0 5s 172.16.167.138 node <none> <none>
pod-podaffinity-deploy-6d486b88bf-4n258 1/1 Running 0 5s 172.16.167.137 node <none> <none>
pod-podaffinity-deploy-6d486b88bf-7xn7w 1/1 Running 0 5s 172.16.58.235 k8s-node02 <none> <none>
pod-podaffinity-deploy-6d486b88bf-8f647 1/1 Running 0 5s 172.16.167.139 node <none> <none>
pod-podaffinity-deploy-6d486b88bf-92w5r 1/1 Running 0 5s 172.16.58.219 k8s-node02 <none> <none>
pod-podaffinity-deploy-6d486b88bf-nhnzk 1/1 Running 0 5s 172.16.58.238 k8s-node02 <none> <none>
web-deploy-7b868c54f5-x78hw 1/1 Running 0 13h 172.16.58.243 k8s-node02 <none> <none>根据节点的标签信息,可以得出 Pod 会优先调度到 k8s-node2 和 master 节点上。
3.2.4 pod 硬反亲和性示例
资源清单:pod_required_AntiAffinity.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: pod-podantiaffinity-deploy
labels:
app: podantiaffinity-deploy
spec:
replicas: 6
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
tolerations: # 配置容忍,允许运行到 Master 节点上
- key: node-role.kubernetes.io/control-plane
effect: NoSchedule
containers:
- name: myapp-pod
image: wangyanglinux/myapp:v1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
# 由于是Pod亲和性/反亲和性, 因此这里匹配规则写的是Pod的标签信息
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- myapp-web
# 拓扑域 若多个node节点具有相同的标签信息【标签键值相同】,则表示这些node节点就在同一拓扑域
topologyKey: disk-type运行yaml文件并查看状态
# 执行资源清单,创建Deployment 和 Pod
$ kubectl apply -f pod_required_AntiAffinity.yaml
# 查看 Deployment
$ kubectl get deploy -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
pod-podantiaffinity-deploy 6/6 6 6 8s myapp-pod wangyanglinux/myapp:v1.0 app=myapp
web-deploy 1/1 1 1 13h myapp-pod wangyanglinux/myapp:v1.0 app=myapp-web
# 查看 Pod
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-podantiaffinity-deploy-54b4fd688f-2jb2x 1/1 Running 0 14s 172.16.85.216 k8s-node01 <none> <none>
pod-podantiaffinity-deploy-54b4fd688f-2lppr 1/1 Running 0 14s 172.16.85.213 k8s-node01 <none> <none>
pod-podantiaffinity-deploy-54b4fd688f-hmwqp 1/1 Running 0 14s 172.16.85.218 k8s-node01 <none> <none>
pod-podantiaffinity-deploy-54b4fd688f-qgt95 1/1 Running 0 14s 172.16.85.217 k8s-node01 <none> <none>
pod-podantiaffinity-deploy-54b4fd688f-tprg4 1/1 Running 0 14s 172.16.85.215 k8s-node01 <none> <none>
pod-podantiaffinity-deploy-54b4fd688f-xz2gt 1/1 Running 0 14s 172.16.85.212 k8s-node01 <none> <none>
web-deploy-7b868c54f5-x78hw 1/1 Running 0 13h 172.16.58.243 k8s-node02 <none> <none>调度说明:由于设置了 Pod 反亲和性的硬策略(必须执行),不允许 Pod 调度到已运行了包含标签为 app: myapp-web 的pod所在的节点,以及相同 topologyKey 的其它节点,限制了 topoloyKey key 为 disk-type 。
运行 app: myapp-web 的Pod 在 k8s-node02 节点上,该节点 topologyKey disk-type=ssd,与之相同的节点是 master 节点,由于设置了反亲和性,所以 资源清单运行的 Pod 不会运行在 master 节点和 k8s-node02 节点上,因此产生的Pod只能运行到 k8s-node01 节点上。
3.2.5 pod 软反亲和性示例
资源清单:pod_preferred_AntiAffinity.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: pod-podantiaffinity-deploy
labels:
app: podantiaffinity-deploy
spec:
replicas: 6
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
tolerations: # 配置容忍,允许运行到 Master 节点上
- key: node-role.kubernetes.io/control-plane
effect: NoSchedule
containers:
- name: myapp-pod
image: wangyanglinux/myapp:v1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
affinity:
podAntiAffinity: # Pod 反亲和性
preferredDuringSchedulingIgnoredDuringExecution: # 软策略
- weight: 100 # 权重(1-100)
podAffinityTerm:
# 由于是Pod亲和性/反亲和性,因此这里匹配规则写的是Pod的标签信息
labelSelector:
matchExpressions:
- key: version
operator: In
values:
- v1
- v2
# 拓扑域 若多个node节点具有相同的标签信息【标签键值相同】,则表示这些node节点就在同一拓扑域
topologyKey: disk-type运行yaml文件并查看状态
# 执行资源清单,创建 Pod
$ kubectl apply -f pod_preferred_AntiAffinity.yaml
# 查看Pod详情
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-podaffinity-deploy-67b85c69b9-74s92 1/1 Running 0 6s 172.16.85.228 k8s-node01 <none> <none>
pod-podaffinity-deploy-67b85c69b9-kzdkj 1/1 Running 0 6s 172.16.85.220 k8s-node01 <none> <none>
pod-podaffinity-deploy-67b85c69b9-mlnzf 1/1 Running 0 6s 172.16.85.222 k8s-node01 <none> <none>
pod-podaffinity-deploy-67b85c69b9-n7c4k 1/1 Running 0 6s 172.16.85.221 k8s-node01 <none> <none>
pod-podaffinity-deploy-67b85c69b9-r6ps6 1/1 Running 0 6s 172.16.85.223 k8s-node01 <none> <none>
pod-podaffinity-deploy-67b85c69b9-wwfld 1/1 Running 0 6s 172.16.85.219 k8s-node01 <none> <none>
web-deploy-7b868c54f5-x78hw 1/1 Running 0 14h 172.16.58.243 k8s-node02 <none> <none>由于是Pod反亲和测验,再根据 master、k8s-node01、k8s-node02的标签信息;很容易推断出 Pod 会优先调度到 k8s-node01 节点。
3.2.6 pod 亲和性与反亲和性联合示例
资源清单:pod_podAffinity_all.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: pod-podaffinity-all-deploy
labels:
app: podaffinity-all-deploy
spec:
replicas: 6
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
tolerations: # 配置容忍,允许运行到 Master 节点上
- key: node-role.kubernetes.io/control-plane
effect: NoSchedule
containers:
- name: myapp-pod
image: wangyanglinux/myapp:v1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
affinity:
podAffinity: # Pod亲和性
requiredDuringSchedulingIgnoredDuringExecution: # 硬策略
# 由于是Pod亲和性/反亲和性, 因此这里匹配规则写的是Pod的标签信息
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- myapp-web
# 拓扑域 若多个node节点具有相同的标签信息【标签键值相同】,则表示这些node节点就在同一拓扑域
topologyKey: disk-type
podAntiAffinity: # Pod反亲和性
preferredDuringSchedulingIgnoredDuringExecution: # 软策略
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: version
operator: In
values:
- v1
- v2
topologyKey: disk-type运行yaml文件并查看状态
# 执行资源清单,创建 Deployment 和 Pod
$ kubectl apply -f pod_podAffinity_all.yaml
# 查看 Deployment
$ kubectl get deploy -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
pod-podaffinity-all-deploy 6/6 6 6 6s myapp-pod wangyanglinux/myapp:v1.0 app=myapp
web-deploy 1/1 1 1 14h myapp-pod wangyanglinux/myapp:v1.0 app=myapp-web
# 查看 Pod
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-podaffinity-all-deploy-6d9d4f8fd4-5knr4 1/1 Running 0 11s 172.16.58.233 k8s-node02 <none> <none>
pod-podaffinity-all-deploy-6d9d4f8fd4-9hw46 1/1 Running 0 11s 172.16.167.142 node <none> <none>
pod-podaffinity-all-deploy-6d9d4f8fd4-csprs 1/1 Running 0 11s 172.16.167.141 node <none> <none>
pod-podaffinity-all-deploy-6d9d4f8fd4-md5f2 1/1 Running 0 11s 172.16.58.222 k8s-node02 <none> <none>
pod-podaffinity-all-deploy-6d9d4f8fd4-rlm76 1/1 Running 0 11s 172.16.167.140 node <none> <none>
pod-podaffinity-all-deploy-6d9d4f8fd4-vcmv7 1/1 Running 0 11s 172.16.58.253 k8s-node02 <none> <none>
web-deploy-7b868c54f5-x78hw 1/1 Running 0 14h 172.16.58.243 k8s-node02 <none> <none>调度解析:在这个示例中,Pod 的亲和性和 Pod 的反亲和性是冲突的,因为他们指向的节点都是 k8s-node02, 但是由于Pod 亲和性采用的是硬策略,优先级更高,因此最终产生的 Pod 会调度在 k8s-node02 节点和 master 节点上。
三、污点与容忍
1. 概述
节点和 Pod 亲和力,是将 Pod 吸引到一组节点【根据拓扑域】(作为优选或硬性要求)。污点(Taints)则相反,它们允许一个节点排斥一组 Pod。
容忍(Tolerations)应用于 pod,允许(但不强制要求)pod 调度到具有匹配污点的节点上。
污点(Taints)和容忍(Tolerations)共同作用,确保 pods 不会被调度到不适当的节点。一个或多个污点应用于节点;这标志着该节点不应该接受任何不容忍污点的 Pod 。
说明:我们在平常使用中发现pod不会调度到k8s的master节点,就是因为master节点存在污点。
2. Taints 污点
使用 kubectl taint 命令可以给某个 Node 节点设置污点,Node 被设置污点之后就和 Pod 之间存在一种相斥的关系,可以让 Node 拒绝Pod的调度执行,甚至将Node 上已经存在的 Pod 驱逐出去。
每个污点的组成如下:
key=value:effect每个污点有一个 key 和 value 作为污点的标签,effect描述污点的作用。当前 taint effect 支持如下选项:
- NoSchedule:表示 K8S 将不会把 Pod 调度到具有该污点的 Node 节点上
- PreferNoSchedule:表示 K8S 将尽量避免把 Pod 调度到具有该污点的 Node 节点上
- NoExecute:表示 K8S 将不会把 Pod 调度到具有该污点的 Node 节点上,同时会将 Node 上已经存在的 Pod 驱逐出去
2.1 污点taint的NoExecute详解
taint 的 effect 值 NoExecute,它会影响已经在节点上运行的 pod:
- 如果 pod 不能容忍 effect 值为 NoExecute 的 taint,那么 pod 将马上被驱逐
- 如果 pod 能够容忍 effect 值为 NoExecute 的 taint,且在 toleration 定义中没有指定 tolerationSeconds,则 pod 会一直在这个节点上运行。
- 如果 pod 能够容忍 effect 值为 NoExecute 的 taint,但是在toleration定义中指定了 tolerationSeconds,则表示 pod 还能在这个节点上继续运行的时间长度。
2.2 Taints污点设置
2.2.1 污点(Taints)查看
# 查看 master 节点的污点(master 节点的名称也叫node)
$ kubectl describe node node
查看 k8s-node01 节点的污点
$ kubectl describe node k8s-node01
2.2.2 污点(Taints)添加
# 给 k8s-node01 设置污点
$ kubectl taint node k8s-node01 check=george:NoSchedule
node/k8s-node01 tainted
# 查看 k8s-node01 节点设置的污点
$ kubectl describe node k8s-node01
Name: k8s-node01
Roles: <none>
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
busi-db=redis
busi-use=www
disk-type=sata
kubernetes.io/arch=amd64
kubernetes.io/hostname=k8s-node01
kubernetes.io/os=linux
Annotations: kubeadm.alpha.kubernetes.io/cri-socket: unix:///var/run/cri-dockerd.sock
node.alpha.kubernetes.io/ttl: 0
projectcalico.org/IPv4Address: 192.168.6.140/24
projectcalico.org/IPv4IPIPTunnelAddr: 172.16.85.192
volumes.kubernetes.io/controller-managed-attach-detach: true
CreationTimestamp: Fri, 28 Mar 2025 17:31:29 +0800
Taints: check=george:NoSchedule # 已设置污点
Unschedulable: false在 k8s-node01 节点添加了一个污点(taint),污点的 key 为 check,value 为 george,污点 effec 为 NoSchedule。这意味着没有 pod 可以调度到 k8s-node01 节点,除非具有相匹配的容忍。
2.2.3 污点(Taints)删除
# 污点删除:方式一
$ kubectl taint nodes k8s-node01 check:NoSchedule-
node/k8s-node01 untainted
# 污点删除:方式二
$ kubectl taint nodes k8s-node01 check=george:NoSchedule-
# 查看 k8s-node01 污点
$ kubectl describe node k8s-node01
Name: k8s-node01
Roles: <none>
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
busi-db=redis
busi-use=www
disk-type=sata
kubernetes.io/arch=amd64
kubernetes.io/hostname=k8s-node01
kubernetes.io/os=linux
Annotations: kubeadm.alpha.kubernetes.io/cri-socket: unix:///var/run/cri-dockerd.sock
node.alpha.kubernetes.io/ttl: 0
projectcalico.org/IPv4Address: 192.168.6.140/24
projectcalico.org/IPv4IPIPTunnelAddr: 172.16.85.192
volumes.kubernetes.io/controller-managed-attach-detach: true
CreationTimestamp: Fri, 28 Mar 2025 17:31:29 +0800
Taints: <none> # 污点已删除
Unschedulable: false3. Tolerations 容忍
设置了污点的 Node 将根据 taint 的 effect:NoSchedule、PreferNoSchedule、NoExecute 和 Pod 之间产生互斥的关系,Pod 将在一定程度上不会被调度到 Node上。
但我们可以在 Pod 上设置容忍(Tolerations),意思是设置了容忍的 Pod 将可以容忍污点的存在,可以被调度到存在污点的 Node 上。
3.1 容忍设置示例
pod.spec.tolerations示例
tolerations:
- key: "key"
operator: "Equal"
value: "value"
effect: "NoSchedule"
tolerations:
- key: "key"
operator: "Exists"
effect: "NoSchedule"
tolerations:
- key: "key"
operator: "Equal"
value: "value"
effect: "NoExecute"
tolerationSeconds: 3600重要说明:
- 其中 key、value、effect 要与 Node 上设置的 taint 保持一致
- operator 的值为 Exists 时,将会忽略 value;只要有 key 和 effect 就行
- tolerationSeconds:表示 pod 能够容忍 effect 值为 NoExecute 的 taint;当指定了 tolerationSeconds【容忍时间】,则表示 pod 还能在这个节点上继续运行的时间长度。
3.2 当不指定key值时
当不指定 key 值和 effect 值时,且 operator 为 Exists,表示容忍所有的污点【能匹配污点所有的 keys,values 和 effects】
tolerations:
- operator: "Exists"3.3 当不指定effect值时
当不指定 effect 值时,则能匹配污点 key 对应的所有 effects 情况
tolerations:
- key: "key"
operator: "Exists"3.4 当有多个Master存在时
当有多个Master存在时,为了防止资源浪费,可以进行如下设置:
kubectl taint nodes Node-name node-role.kubernetes.io/control-plane=:PreferNoSchedule4. 多个 Taints 污点和多个 Tolerations 容忍怎么判断
可以在同一个 node 节点上设置多个污点(Taints),在同一个 pod 上设置多个容忍(Tolerations)。Kubernetes 处理多个污点和容忍的方式就像一个过滤器:从节点的所有污点开始,然后忽略可以被 Pod 容忍匹配的污点;保留其余不可忽略的污点,污点的 effect 对 Pod 具有显示效果:特别是:
- 如果有至少一个不可忽略污点,effect 为 NoSchedule,那么 Kubernetes 将不调度 Pod 到该节点
- 如果没有 effect 为 NoSchedule 的不可忽视污点,但有至少一个不可忽视污点,effect 为 PreferNoSchedule,那么 Kubernetes 将尽量不调度 Pod 到该节点
- 如果有至少一个不可忽视污点,effect 为 NoExecute,那么 Pod 将被从该节点驱逐(如果 Pod 已经在该节点运行),并且不会被调度到该节点(如果 Pod 还未在该节点运行)
5. 污点和容忍示例
5.1 Node 污点为 NoExecute 的示例
目标:测试给节点添加 effect 为 NoExecute 的污点,是否会驱逐已经运行的 Pod。
注意:在开始测试实验前,将节点添加的污点清除。
初始状态下
- master 节点污点为:node-role.kubernetes.io/control-plane:NoSchedule
- k8s-node01 节点污点为空
- k8s-node02 节点污点为空
查看污点
# 查看 master 节点的污点设置
$ kubectl describe node node | grep 'Taints' -A 5
# 查看 k8s-node01 节点的污点设置
$ kubectl describe node k8s-node01 | grep 'Taints' -A 5
# 查看 k8s-node02 节点的污点设置
$ kubectl describe node k8s-node02 | grep 'Taints' -A 5除了 master 默认的污点,在 k8s-node01、k8s-node02 无污点。
污点为NoExecute示例
资源清单:noexecute_tolerations.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: noexec-tolerations-deploy
labels:
app: noexectolerations-deploy
spec:
replicas: 6
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp-pod
image: wangyanglinux/myapp:v1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80执行资源清单
# 执行资源清单,创建 Pod
$ kubectl apply -f noexecute_tolerations.yaml
# 查看 Pod 运行详情
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
noexec-tolerations-deploy-75dbf9dcdc-4vd9c 1/1 Running 0 46s 172.16.58.224 k8s-node02 <none> <none>
noexec-tolerations-deploy-75dbf9dcdc-76k76 1/1 Running 0 46s 172.16.85.227 k8s-node01 <none> <none>
noexec-tolerations-deploy-75dbf9dcdc-nm7xd 1/1 Running 0 46s 172.16.58.196 k8s-node02 <none> <none>
noexec-tolerations-deploy-75dbf9dcdc-pp2f7 1/1 Running 0 46s 172.16.85.230 k8s-node01 <none> <none>
noexec-tolerations-deploy-75dbf9dcdc-x92bz 1/1 Running 0 46s 172.16.85.225 k8s-node01 <none> <none>
noexec-tolerations-deploy-75dbf9dcdc-xfc25 1/1 Running 0 46s 172.16.58.211 k8s-node02 <none> <none>此时 k8s-node01 与 k8s-node02 节点没有设置 taint,资源清单也没有添加 tolerations ,此时 Pod 在这两个节点上均匀的分布。
给 k8s-node02 节点添加 effect 为 NoExecute 的污点
$ kubectl taint nodes k8s-node02 check-mem=memdb:NoExecute此时再查看集群中节点的污点设置情况如下:
- master 节点污点为:node-role.kubernetes.io/control-plane:NoSchedule
- k8s-node01 节点污点为空
- k8s-node02 节点污点:check-mem=memdb:NoExecute
再次查看Pod分布
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
noexec-tolerations-deploy-75dbf9dcdc-76k76 1/1 Running 0 13m 172.16.85.227 k8s-node01 <none> <none>
noexec-tolerations-deploy-75dbf9dcdc-ctj5q 1/1 Running 0 83s 172.16.85.234 k8s-node01 <none> <none>
noexec-tolerations-deploy-75dbf9dcdc-pp2f7 1/1 Running 0 13m 172.16.85.230 k8s-node01 <none> <none>
noexec-tolerations-deploy-75dbf9dcdc-qpsxh 1/1 Running 0 83s 172.16.85.226 k8s-node01 <none> <none>
noexec-tolerations-deploy-75dbf9dcdc-x92bz 1/1 Running 0 13m 172.16.85.225 k8s-node01 <none> <none>
noexec-tolerations-deploy-75dbf9dcdc-z72r2 1/1 Running 0 83s 172.16.85.232 k8s-node01 <none> <none>所有 Pod 都已转移到 k8s-node01 节点上了,原本运行在 k8s-node02 节点上的 Pod 都被驱逐。
5.2 Pod 没有容忍时(Tolerations)
目标:测试在节点设置了污点,且 Pod 没有设置容忍时,观察 k8s 对 Pod 的调度情况
注意:在实验前,将之前给节点添加的污点删除,避免对后面的实验产生影响。
给节点设置污点
# 删除 node02 污点
$ kubectl taint nodes k8s-node02 check-mem:NoExecute-
# 给 node01 设置污点
$ kubectl taint nodes k8s-node01 check-nginx=web:PreferNoSchedule
# 给 node02 设置污点
$ kubectl taint nodes k8s-node02 check-nginx=web:NoSchedule当前集群节点的污点设置情况
- master 节点污点为:node-role.kubernetes.io/control-plane:NoSchedule
- k8s-node01 节点污点为:check-nginx=web:PreferNoSchedule
- k8s-node02 节点污点为:check-nginx=web:NoSchedule
资源清单
no_tolerations.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: no-tolerations-deploy
labels:
app: notolerations-deploy
spec:
replicas: 6
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp-pod
image: wangyanglinux/myapp:v1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80执行资源清单
# 执行资源清单,创建 Pod
$ kubectl apply -f no_tolerations.yaml
# 查看 Pod 详情
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
no-tolerations-deploy-75dbf9dcdc-2242k 1/1 Running 0 6s 172.16.85.236 k8s-node01 <none> <none>
no-tolerations-deploy-75dbf9dcdc-5q5sd 1/1 Running 0 6s 172.16.85.240 k8s-node01 <none> <none>
no-tolerations-deploy-75dbf9dcdc-b2ztm 1/1 Running 0 6s 172.16.85.239 k8s-node01 <none> <none>
no-tolerations-deploy-75dbf9dcdc-crnp9 1/1 Running 0 6s 172.16.85.235 k8s-node01 <none> <none>
no-tolerations-deploy-75dbf9dcdc-ktcz6 1/1 Running 0 6s 172.16.85.237 k8s-node01 <none> <none>
no-tolerations-deploy-75dbf9dcdc-xjr5f 1/1 Running 0 6s 172.16.85.233 k8s-node01 <none> <none>因为 k8s-node02 节点的污点 check-nginx 的 effect 为 NoSchedule,说明 pod 不能被调度到该节点。此时 k8s-node01 节点的污点 check-nginx 的 effect 为PreferNoSchedule【尽量不调度到该节点】;但只有该节点满足调度条件,因此都调度到了 k8s-node01 节点。
5.3 Pod 单个容忍时(Tolerations)
目标:测试在节点设置了污点,给 Pod 设置一个容忍时,观察 k8s 对 Pod 的调度情况
注意:在实验前,将之前给节点添加的污点删除,避免对后面的实验产生影响。
给节点设置污点
# 给 node01 设置污点
$ kubectl taint nodes k8s-node01 check-nginx=web:PreferNoSchedule
# 给 node02 设置污点
$ kubectl taint nodes k8s-node02 check-nginx=web:NoSchedule当前集群节点的污点设置情况
- master 节点污点为:node-role.kubernetes.io/control-plane:NoSchedule
- k8s-node01 节点污点为:check-nginx=web:PreferNoSchedule
- k8s-node02 节点污点为:check-nginx=web:NoSchedule
单个容忍的示例
资源清单:one_tolerations.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: one-tolerations-deploy
labels:
app: onetolerations-deploy
spec:
replicas: 30
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp-pod
image: wangyanglinux/myapp:v1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
tolerations:
- key: "check-nginx"
operator: "Equal"
value: "web"
effect: "NoSchedule"执行资源清单
# 执行资源清单,创建 Pod
$ kubectl apply -f one_tolerations.yaml
# 查看 Pod 调度详情
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
no-tolerations-deploy-6675cffc9-ccz55 1/1 Running 0 6s 172.16.58.226 k8s-node02 <none> <none>
no-tolerations-deploy-6675cffc9-ff5m4 1/1 Running 0 6s 172.16.58.214 k8s-node02 <none> <none>
no-tolerations-deploy-6675cffc9-mg99m 1/1 Running 0 6s 172.16.58.248 k8s-node02 <none> <none>
no-tolerations-deploy-6675cffc9-pdqvh 1/1 Running 0 6s 172.16.58.242 k8s-node02 <none> <none>
no-tolerations-deploy-6675cffc9-s8bxh 1/1 Running 0 6s 172.16.58.217 k8s-node02 <none> <none>
no-tolerations-deploy-6675cffc9-zjzkl 1/1 Running 0 6s 172.16.58.221 k8s-node02 <none> <none>由于给 Pod 添加了容忍(针对 node02 节点),因此 Pod 可以运行到 k8s-node02 节点上。但是没有运行到 k8s-node01 节点上,这是由于 node01 节点的 污点 effect 设置为 PreferNoSchedule (尽可能不调度),因此只有当 node02 节点的压力比较大时,才会往 node01 节点调度。
给Pod添加副本,让Pod调度到 k8s-node01 节点
# Pod 副本数扩展到 120个
$ kubectl scale deployment one-tolerations-deploy --replicas 120
# 再次查看 Pod 调度情况
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
one-tolerations-deploy-6675cffc9-2ff55 0/1 ContainerCreating 0 2s <none> k8s-node01 <none> <none>
one-tolerations-deploy-6675cffc9-2k7pm 1/1 Running 0 35s 172.16.58.243 k8s-node02 <none> <none>
one-tolerations-deploy-6675cffc9-2tkw9 0/1 ContainerCreating 0 2s <none> k8s-node02 <none> <none>
......终于让 node01 节点也运行了 Pod 了。
5.4 Pod多个容忍时(Tolerations)
目标:测试在节点设置了污点,给 Pod 设置多个容忍时,观察 k8s 对 Pod 的调度情况
注意:在实验前,将之前给节点添加的污点删除,避免对后面的实验产生影响。
给节点设置污点
# 给 node01 设置污点
$ kubectl taint nodes k8s-node01 check-nginx=web:PreferNoSchedule
$ kubectl taint nodes k8s-node01 check-redis=memdb:NoSchedule
# 给 node02 设置污点
$ kubectl taint nodes k8s-node02 check-nginx=web:NoSchedule
$ kubectl taint nodes k8s-node02 check-redis=database:NoSchedule当前集群节点的污点设置情况
- master 节点污点为:node-role.kubernetes.io/control-plane:NoSchedule
- k8s-node01 节点污点为:check-nginx=web:PreferNoSchedule、check-redis=memdb:NoSchedule
- k8s-node02 节点污点为:check-nginx=web:NoSchedule、check-redis=database:NoSchedule
污点查看操作如下:
# 查看 master 节点的污点(master节点名称叫 node)
kubectl describe node node | grep 'Taints' -A 5
# 查看 k8s-node01 节点的污点
kubectl describe node k8s-node01 | grep 'Taints' -A 5
# 查看 k8s-node02 节点的污点
kubectl describe node k8s-node02 | grep 'Taints' -A 5多个容忍示例
资源清单:multi_tolerations.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: multi-tolerations-deploy
labels:
app: multitolerations-deploy
spec:
replicas: 6
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp-pod
image: wangyanglinux/myapp:v1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
tolerations:
- key: "check-nginx"
operator: "Equal"
value: "web"
effect: "NoSchedule"
- key: check-redis
operator: Exists
effect: NoSchedule执行资源清单
# 执行资源清单,创建Pod
$ kubectl apply -f multi_tolerations.yaml
# 查看Pod
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
multi-tolerations-deploy-6879db4797-8qqzg 1/1 Running 0 3s 172.16.58.231 k8s-node02 <none> <none>
multi-tolerations-deploy-6879db4797-9hgn9 1/1 Running 0 3s 172.16.58.211 k8s-node02 <none> <none>
multi-tolerations-deploy-6879db4797-gfnwm 1/1 Running 0 3s 172.16.58.241 k8s-node02 <none> <none>
multi-tolerations-deploy-6879db4797-k5twd 1/1 Running 0 3s 172.16.58.205 k8s-node02 <none> <none>
multi-tolerations-deploy-6879db4797-k5z7x 1/1 Running 0 3s 172.16.58.230 k8s-node02 <none> <none>
multi-tolerations-deploy-6879db4797-rhlnx 1/1 Running 0 3s 172.16.58.234 k8s-node02 <none> <none>示例中的pod容忍为:check-nginx=web:NoSchedule;check-redis=:NoSchedule。因此 pod 会尽量调度到k8s-node02节点,尽量不调度到 k8s-node01 节点。
5.5 Pod容忍指定污点key的所有effects情况
实验目的:测试 Pod 容忍设置了 key 后,将 operator 设置为 Exists 时,节点的调度情况。
提示:把已有的污点清除,以免影响测验。
# 删除污点
kubectl taint nodes k8s-node01 check-redis=memdb:NoSchedule- check-nginx=web:PreferNoSchedule-
kubectl taint nodes k8s-node02 check-nginx=web:NoSchedule- check-redis=database:NoSchedule-节点上的污点设置(Taints)
kubectl taint nodes k8s-node01 check-redis=memdb:NoSchedule
kubectl taint nodes k8s-node02 check-redis=database:NoSchedule当前集群节点的污点设置情况
- master 节点污点为:node-role.kubernetes.io/control-plane:NoSchedule
- k8s-node01 节点污点为:check-redis=memdb:NoSchedule
- k8s-node02 节点污点为:check-redis=database:NoSchedule
污点查看操作如下:
# 查看 master 节点的污点(master节点名称叫 node)
kubectl describe node node | grep 'Taints' -A 5
# 查看 k8s-node01 节点的污点
kubectl describe node k8s-node01 | grep 'Taints' -A 5
# 查看 k8s-node02 节点的污点
kubectl describe node k8s-node02 | grep 'Taints' -A 5指定污点key的所有effects示例
资源清单:key_tolerations.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: key-tolerations-deploy
labels:
app: keytolerations-deploy
spec:
replicas: 6
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp-pod
image: wangyanglinux/myapp:v1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
tolerations: # 容忍指定污点key的所有effects
- key: check-redis
operator: Exists执行资源清单,查看状态
# 执行资源清单,创建 Pod
$ kubectl apply -f key_tolerations.yaml
# 查看 Deployment
$ kubectl get deploy -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
key-tolerations-deploy 6/6 6 6 18s myapp-pod wangyanglinux/myapp:v1.0 app=myapp
# 查看 Pod
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
key-tolerations-deploy-65c6c87cd-k8xdg 1/1 Running 0 24s 172.16.85.214 k8s-node01 <none> <none>
key-tolerations-deploy-65c6c87cd-lvmcv 1/1 Running 0 24s 172.16.58.201 k8s-node02 <none> <none>
key-tolerations-deploy-65c6c87cd-njdhh 1/1 Running 0 24s 172.16.58.228 k8s-node02 <none> <none>
key-tolerations-deploy-65c6c87cd-ppcs5 1/1 Running 0 24s 172.16.58.226 k8s-node02 <none> <none>
key-tolerations-deploy-65c6c87cd-ts7zn 1/1 Running 0 24s 172.16.85.208 k8s-node01 <none> <none>
key-tolerations-deploy-65c6c87cd-x25nb 1/1 Running 0 24s 172.16.58.207 k8s-node02 <none> <none>Pod 在 k8s-node01 k8s-node02 节点都有运行,虽然两个节点 Taint 设置的 value 不同,Key相同,由于资源清单中设置的 tolerations.operator: Exists 所有两个节点都有机会被调度执行。
5.6 Pod容忍所有污点
实验目的:测试 Pod 容忍仅设置:tolerations.operator: Exists 时,节点的调度情况。
提示:把已有的污点清除,以免影响测验。
# 删除污点
kubectl taint nodes k8s-node01 check-redis=memdb:NoSchedule- check-nginx=web:PreferNoSchedule-
kubectl taint nodes k8s-node02 check-nginx=web:NoSchedule- check-redis=database:NoSchedule-节点上的污点设置(Taints)
kubectl taint nodes k8s-node01 check-nginx=web:PreferNoSchedule check-redis=memdb:NoSchedule
kubectl taint nodes k8s-node02 check-nginx=web:NoSchedule check-redis=database:NoSchedule当前集群节点的污点设置情况
- master 节点污点为:node-role.kubernetes.io/control-plane:NoSchedule
- k8s-node01 节点污点为:check-redis=memdb:NoSchedule 、check-nginx=web:PreferNoSchedule
- k8s-node02 节点污点为:check-redis=database:NoSchedule、 check-nginx=web:NoSchedule
污点查看操作如下:
# 查看 master 节点的污点(master节点名称叫 node)
kubectl describe node node | grep 'Taints' -A 5
# 查看 k8s-node01 节点的污点
kubectl describe node k8s-node01 | grep 'Taints' -A 5
# 查看 k8s-node02 节点的污点
kubectl describe node k8s-node02 | grep 'Taints' -A 5所有容忍示例
资源清单:all_tolerations.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: key-tolerations-deploy
labels:
app: keytolerations-deploy
spec:
replicas: 6
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp-pod
image: wangyanglinux/myapp:v1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
tolerations: # 容忍所有污点
- operator: Exists执行资源清单,查看状态
# 执行资源清单
$ kubectl apply -f all_tolerations.yaml
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
key-tolerations-deploy-7d8d44b494-5r7c9 1/1 Running 0 11s 172.16.167.143 node <none> <none>
key-tolerations-deploy-7d8d44b494-bmzfq 1/1 Running 0 12s 172.16.58.220 k8s-node02 <none> <none>
key-tolerations-deploy-7d8d44b494-djhpm 1/1 Running 0 11s 172.16.85.210 k8s-node01 <none> <none>
key-tolerations-deploy-7d8d44b494-g4rxp 1/1 Running 0 11s 172.16.85.196 k8s-node01 <none> <none>
key-tolerations-deploy-7d8d44b494-s4qdh 1/1 Running 0 11s 172.16.58.238 k8s-node02 <none> <none>
key-tolerations-deploy-7d8d44b494-txtnq 1/1 Running 0 11s 172.16.167.144 node <none> <none>pod 在 master 节点、k8s-node01节点、k8s-node02 节点都有运行。
四、固定节点nodeName和nodeSelector调度
nodeName 是节点选择约束的最简单形式,但是由于其限制,通常很少使用它。nodeName 是 PodSpec 的领域。
pod.spec.nodeName 将 Pod 直接调度到指定的 Node 节点上,会【跳过 Scheduler 的调度策略】,该匹配规则是【强制】匹配。可以越过 Taints 污点进行调度。
nodeName用于选择节点的一些限制是:
- 如果指定的节点不存在,则容器将不会运行,并且在某些情况下可能会自动删除。
- 如果指定的节点没有足够的资源来容纳该Pod,则该Pod将会失败,并且其原因将被指出,例如OutOfmemory或OutOfcpu。
- 云环境中的节点名称并非总是可预测或稳定的。
1. 指定 nodeName 示例
当前集群节点如下:
$ kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-node01 Ready <none> 71d v1.29.15
k8s-node02 Ready <none> 71d v1.29.15
node Ready control-plane 71d v1.29.151.1 当 nodeName 指定节点存在
资源清单:scheduler_nodeName.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: scheduler-nodename-deploy
labels:
app: nodename-deploy
spec:
replicas: 6
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp-pod
image: wangyanglinux/myapp:v1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
# 指定节点运行
nodeName: node # 指定 master 节点运行,这里 master 节点的名称为 node执行资源清单,查看状态
# 执行资源清单
$ kubectl apply -f scheduler_nodeName.yaml
# 查看 Deployment
$ kubectl get deployment -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
scheduler-nodename-deploy 6/6 6 6 18s myapp-pod wangyanglinux/myapp:v1.0 app=myapp
# 查看 ReplicSet
$ kubectl get rs -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
scheduler-nodename-deploy-6d6fdcbf6c 6 6 6 15s myapp-pod wangyanglinux/myapp:v1.0 app=myapp,pod-template-hash=6d6fdcbf6c
# 查看Pod
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
scheduler-nodename-deploy-6d6fdcbf6c-7crw8 1/1 Running 0 27s 172.16.167.147 node <none> <none>
scheduler-nodename-deploy-6d6fdcbf6c-9kg4p 1/1 Running 0 27s 172.16.167.149 node <none> <none>
scheduler-nodename-deploy-6d6fdcbf6c-j7qq4 1/1 Running 0 27s 172.16.167.150 node <none> <none>
scheduler-nodename-deploy-6d6fdcbf6c-kz6n2 1/1 Running 0 28s 172.16.167.145 node <none> <none>
scheduler-nodename-deploy-6d6fdcbf6c-v9tlk 1/1 Running 0 28s 172.16.167.146 node <none> <none>
scheduler-nodename-deploy-6d6fdcbf6c-wr6jj 1/1 Running 0 28s 172.16.167.148 node <none> <none>可以看到 Pod 都运行到了 master 节点上,尽管 master 节点上存在着污点。由于设置了 nodeName, Scheduler 在调度时忽略了污点。
1.2 当 nodeName 指定节点不存在
资源清单:scheduler_nodeName_02.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: scheduler-nodename-deploy
labels:
app: nodename-deploy
spec:
replicas: 6
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp-pod
image: wangyanglinux/myapp:v1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
# 指定节点运行
nodeName: k8s-node05 # 指定一个不存在的节点执行资源清单,查看状态
# 执行资源清单
$ kubectl apply -f scheduler_nodeName02.yaml
# 查看 Deployment
$ kubectl get deployment -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
scheduler-nodename-deploy 0/6 6 0 7s myapp-pod wangyanglinux/myapp:v1.0 app=myapp
# 查看 RS
$ kubectl get rs -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
scheduler-nodename-deploy-765654657f 6 6 0 14s myapp-pod wangyanglinux/myapp:v1.0 app=myapp,pod-template-hash=765654657f
# 查看 Pod
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
scheduler-nodename-deploy-765654657f-898xn 0/1 Pending 0 22s <none> k8s-node05 <none> <none>
scheduler-nodename-deploy-765654657f-dbbqw 0/1 Pending 0 22s <none> k8s-node05 <none> <none>
scheduler-nodename-deploy-765654657f-gslks 0/1 Pending 0 22s <none> k8s-node05 <none> <none>
scheduler-nodename-deploy-765654657f-j5tnk 0/1 Pending 0 22s <none> k8s-node05 <none> <none>
scheduler-nodename-deploy-765654657f-s74wk 0/1 Pending 0 22s <none> k8s-node05 <none> <none>
scheduler-nodename-deploy-765654657f-smcmt 0/1 Pending 0 22s <none> k8s-node05 <none> <none>由于 nodeName 指定的节点不存在, 因此 Pod 无法被调度。
2. 使用 nodeSelector 调度
nodeSelector 是节点选择约束的最简单推荐形式。nodeSelector 是 PodSpec 的领域。它指定键值对的映射。
pod.spec.nodeSelector 是通过 kubernetes 的 label-selector 机制选择节点,由调度器调度策略匹配 label,而后调度 Pod 到目标节点,该匹配规则属于【强制】约束。由于是调度器调度,因此不能越过Taints污点进行调度。
当前集群节点信息
$ kubectl get node --show-labels
NAME STATUS ROLES AGE VERSION LABELS
k8s-node01 Ready <none> 71d v1.29.15 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,busi-db=redis,busi-use=www,disk-type=sata,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node01,kubernetes.io/os=linux
k8s-node02 Ready <none> 71d v1.29.15 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,busi-db=etcd,busi-use=www,disk-type=ssd,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node02,kubernetes.io/os=linux
node Ready control-plane 71d v1.29.15 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,busi-db=redis,busi-use=www,disk-type=ssd,kubernetes.io/arch=amd64,kubernetes.io/hostname=node,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node.kubernetes.io/exclude-from-external-load-balancers=2.1 当 nodeSelector 标签存在
资源清单:scheduler_nodeSelector.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: scheduler-nodeselector-deploy
labels:
app: nodeselector-deploy
spec:
replicas: 6
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp-pod
image: wangyanglinux/myapp:v1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
# 指定节点标签的 key: value
nodeSelector:
disk-type: ssd执行资源清单,查看状态
# 执行资源清单,创建Pod
$ kubectl apply -f scheduler_nodeSelector.yaml
# 查看 Pod
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
scheduler-nodeselector-deploy-84dccd9bf8-4vwh5 1/1 Running 0 15s 172.16.58.217 k8s-node02 <none> <none>
scheduler-nodeselector-deploy-84dccd9bf8-kbpl9 1/1 Running 0 15s 172.16.58.222 k8s-node02 <none> <none>
scheduler-nodeselector-deploy-84dccd9bf8-mvtp2 1/1 Running 0 15s 172.16.58.196 k8s-node02 <none> <none>
scheduler-nodeselector-deploy-84dccd9bf8-p568f 1/1 Running 0 15s 172.16.58.209 k8s-node02 <none> <none>
scheduler-nodeselector-deploy-84dccd9bf8-rmnf2 1/1 Running 0 15s 172.16.58.203 k8s-node02 <none> <none>
scheduler-nodeselector-deploy-84dccd9bf8-twnjh 1/1 Running 0 15s 172.16.58.195 k8s-node02 <none> <none>可以看到 Pod 都被调度到了 k8s-node02 节点上了,虽然 k8s-node02 节点与 master 节点都存在标签为 disk-type: ssd,但是由于 master 节点设置了 Taint node-role.kubernetes.io/control-plane:NoSchedule , 因此Pod不能调度到 master 节点上。
2.2 当 nodeSelector 标签不存在
资源清单:scheduler_nodeSelector02.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: scheduler-nodeselector-deploy
labels:
app: nodeselector-deploy
spec:
replicas: 6
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp-pod
image: wangyanglinux/myapp:v1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
# 指定节点标签的 key: value
nodeSelector:
disk-type: abc执行资源清单,查看状态
# 执行资源清单
$ kubectl apply -f scheduler_nodeSelector02.yaml
# 查看 Pod
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
scheduler-nodeselector-deploy-686bd46f76-4n8qg 0/1 Pending 0 23s <none> <none> <none> <none>
scheduler-nodeselector-deploy-686bd46f76-5zsdx 0/1 Pending 0 22s <none> <none> <none> <none>
scheduler-nodeselector-deploy-686bd46f76-6hmd5 0/1 Pending 0 22s <none> <none> <none> <none>
scheduler-nodeselector-deploy-686bd46f76-dpzmh 0/1 Pending 0 22s <none> <none> <none> <none>
scheduler-nodeselector-deploy-686bd46f76-hrhqv 0/1 Pending 0 23s <none> <none> <none> <none>
scheduler-nodeselector-deploy-686bd46f76-nkd4g 0/1 Pending 0 23s <none> <none> <none> <none>由于没有节点存在标签为 disk-type: abc, 因此 Pod 无法被调度执行,一直处于Pending 状态。
参考链接
https://www.cnblogs.com/zhanglianghhh/p/13875203.html
https://www.cnblogs.com/zhanglianghhh/p/13922945.html
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 george_95@126.com