概要:
简述 Loki 相关组件原理,并演示两种使用 Loki 监控Pod日志的部署方式:使用 yaml 资源清单部署 和 使用 Helm 部署
集群环境
| IP | Hostname | 用途 |
|---|---|---|
| 10.20.1.139 | k8s-master01 | Master节点 |
| 10.20.1.140 | k8s-node01 | Node节点 |
| 10.20.1.141 | k8s-node02 | Node节点 |
| 10.20.1.142 | k8s-node03 | Node节点 |
一、简介
对于 Kubernetes 集群本身的监控也是非常重要的,我们需要时时刻刻了解集群的运行状态。
对于集群的监控一般我们需要考虑以下几个方面:
- Kubernetes 节点的监控:比如节点的 cpu、load、disk、memory 等指标
- 内部系统组件的状态:比如 kube-scheduler、kube-controller-manager、kubedns/coredns 等组件的详细运行状态
- 编排级的 metrics:比如 Deployment 的状态、资源请求、调度和 API 延迟等数据指标
Kubernetes 集群的监控方案目前主要有以下几种方案:
cAdvisor : 是一个轻量级的容器监控工具,用于收集容器运行时的资源使用情况(如 CPU、内存、磁盘、网络等)以及性能统计数据。
作用
- 提供容器级别的资源使用和性能指标。
- 暴露这些指标,供其他监控工具(如 Metrics Server 或 Prometheus)采集。
- 内置于 Kubernetes 的 Kubelet 中,自动为集群中的每个节点收集容器数据。
特点
轻量级:资源占用低,适合在每个节点运行。
实时性:提供实时的容器性能数据。
原生支持:在 Kubernetes 中默认集成到 Kubelet,无需单独部署。
开放接口:通过 HTTP API 暴露指标,易于集成到其他监控系统。
metrics-server : 是一个轻量级的、可扩展的组件,用于从 Kubernetes 集群中的节点和 Pod 收集资源使用情况(如 CPU 和内存)的指标数据,并通过 Kubernetes API 提供这些数据。
作用
- 提供实时的资源使用指标,供用户或工具(如 kubectl、HPA)查询。
- 支持基于资源使用情况的自动扩展决策。
- 替代了早期的 Heapster(已废弃),是 Kubernetes 生态系统中默认的监控数据收集工具。
特点
轻量级:Metrics Server 只存储内存中的瞬时数据,不持久化历史数据。
高效:通过 Kubernetes API 聚合层提供指标,易于集成。
可扩展:支持与更复杂的监控系统(如 Prometheus)集成。
kube-state-metrics : 是一个服务,通过 Kubernetes API 收集集群中资源对象(如 Pod、Deployment、Service 等)的状态和元数据,并以 Prometheus 兼容的格式通过 HTTP 端点暴露这些指标。
作用:
- 提供 Kubernetes 资源对象的状态信息(如 Pod 运行状态、Deployment 副本数等)。
- 补充 cAdvisor 和 node_exporter 的功能,专注于 Kubernetes 对象的元数据而非系统或容器级资源使用。
- 支持 Prometheus 抓取数据,用于监控、告警和可视化。
特点:
轻量级:以单一 Deployment 运行,资源占用低。
专注于状态:提供资源对象的元数据和状态(如 Pod 是否 Running、Job 是否完成)。
Prometheus 集成:通过 /metrics 端点暴露数据,易于与 Prometheus 和 Grafana 集成。
动态更新:实时监听 Kubernetes API 的资源变化。
node_exporter : 一个 Prometheus 导出器(exporter),专门用于收集主机(节点)的系统级指标,如 CPU、内存、磁盘、网络、文件系统等,并以 Prometheus 兼容的格式通过 HTTP 端点暴露这些指标。
- 作用:
- 提供节点级别的详细系统监控数据,弥补 Kubernetes Metrics Server 和 cAdvisor 的局限性(后者主要聚焦于容器指标)。
- 支持 Prometheus 抓取指标,用于长期存储、分析和可视化。
- 广泛用于 Kubernetes 集群、裸机或虚拟机环境的监控。
- 特点:
- 轻量级:资源占用低,适合在每个节点运行。
- 模块化:支持多种收集器(collector),可按需启用或禁用。
- 跨平台:主要支持 Linux,也支持部分 Unix 系统(如 macOS、FreeBSD)。
- Prometheus 集成:通过标准化的 /metrics 端点暴露数据,易于与 Prometheus 和 Grafana 集成。
- 作用:
不过 kube-state-metrics 和 metrics-server 之间还是有很大不同的,二者的主要区别如下:
- kube-state-metrics 主要关注的是业务相关的一些元数据,比如 Deployment、Pod、副本状态等
- metrics-server 主要关注的是资源度量 API 的实现,比如 CPU、文件描述符、内存、请求延时等指标
二、部署 StorageClass
1. 安装NFS
安装 NFS,配置存储卷自动分配 PV,用于持久化日志数据。
这里选用 k8s-master (10.20.1.139) 作为 nfs 服务端,其它节点作为 nfs 客户端
1.1 安装 NFS 服务
master节点、node01、node02、node03 节点都需要安装执行
$ yum install -y nfs-utils rpcbind1.2 创建共享目录
仅在 nfs 服务端 (master节点) 执行
# 创建 共享目录
$ mkdir -p /root/data/prometheus/
# 目录提权
chmod 777 /root/data/prometheus/
# 变更用户组
chown nobody /root/data/prometheus/1.3 编辑共享目录读写配置
仅在 nfs 服务端 (master节点) 执行
$ vim /etc/exports
/root/data 10.20.1.0/24(rw,fsid=0,no_root_squash)
/root/data/prometheus 10.20.1.0/24(rw,no_root_squash,no_all_squash,no_subtree_check,sync)这里使用的是 NFS4 服务,上面的配置表示 10.20.1.0/24 网段的 ip 都可以与 nfs 主服务器共享 /root/data/prometheus 目录内容
1.4 启动NFS服务
集群内所有节点都需要操作
# 启动服务
$ systemctl start rpcbind
$ systemctl restart nfs-server.service
# 设置开机自启
$ systemctl enable rpcbind
$ systemctl enable nfs-server.service1.5 测试 NFS 目录挂载
# NFS 客户端执行:创建目录
$ mkdir /data/test1
# NFS 客户端执行:挂载目录到NFS服务端
$ mount -t nfs4 10.20.1.139:/prometheus /data/test1
# NFS 客户端执行:查看挂载结果
$ mount | grep /data/test1
10.20.1.139:/prometheus on /data/test1 type nfs4 (rw,relatime,vers=4.2,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.20.1.141,local_lock=none,addr=10.20.1.139)
# NFS 客户端执行:写入数据
$ echo "this is client" > /data/test1/a.txt
# NFS 服务端执行:查看数据, 结论:客户端数据已写入服务端挂载目录
$ cat /root/data/prometheus/a.txt
this is client
# NFS 服务端执行:写入数据
$ echo "This is Server" >> /root/data/prometheus/a.txt
# NFS 客户端执行:查看数据, 结论:服务端数据已写入客户端挂载目录
$ cat /data/test1/a.txt
this is client
This is Server取消挂载
# 取消挂载
umount /data/test1
# 如果取消挂载出现报错,例如:
$ umount /data/test1
umount.nfs4: /data/test1: device is busy
# 查看目录占用进程
$ fuser -m /data/test1
/data/test1: 32679c
# kill 进程
$ kill -9 32679
# 方式二:强制卸载
umount -l /data/test12. 创建 StorageClass
资源清单:prometheus-storage.yaml
# 1.命名空间
apiVersion: v1
kind: Namespace
metadata:
name: prometheus-storage
# 2.存储类
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
namespace: prometheus-storage
name: prometheus-storage
# provisioner: nfs-provisioner
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner # 指定动态配置器,NFS 子目录外部配置器
parameters:
pathPattern: ${.PVC.namespace}/${.PVC.name} # 动态生成的 NFS 路径,格式为 <PVC 命名空间>/<PVC 名称>,例如 loki-storageclass/test-claim。
archiveOnDelete: "true" ##删除 pv,pv内容是否备份
# 3.NFS 动态存储配置器,用于自动为 PVC 创建 PV
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: prometheus-storage
name: nfs-client-provisioner # NFS 动态存储配置器,用于自动为 PVC 创建 PV
spec:
replicas: 1
selector:
matchLabels:
app: nfs-client-provisioner
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner # 指定使用的 ServiceAccountName
containers:
- name: nfs-client-provisioner
image: k8s.dockerproxy.com/sig-storage/nfs-subdir-external-provisioner:v4.0.2
imagePullPolicy: IfNotPresent
volumeMounts:
- name: nfs-client-root # 挂载的卷名称,与 volumes 部分定义的卷对应
mountPath: /persistentvolumes # 将 NFS 卷挂载到容器内的 /persistentvolumes 路径,供容器读写 NFS 共享数据。
env:
- name: PROVISIONER_NAME
value: k8s-sigs.io/nfs-subdir-external-provisioner # 指定配置器名称,与 StorageClass 保持一致
- name: NFS_SERVER
value: 10.20.1.139 # NFS 服务器地址
- name: NFS_PATH
value: /root/data/prometheus # NFS 共享路径
volumes:
- name: nfs-client-root # 定义一个名为 nfs-client-root 的 NFS 卷,连接到 NFS 服务器的指定地址和路径
nfs:
server: 10.20.1.139 # NFS 服务器地址
path: /root/data/prometheus # NFS 共享路径
nodeSelector: # 指定Pod运行的节点
kubernetes.io/hostname: k8s-node01
# nodeName: k8s-node01 # 指定 Pod 运行在 k8s-node01 节点上
# 4.服务账户
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner # SA 的名称
namespace: prometheus-storage
# 5.集群角色
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
# 6.集群角色绑定
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount # 绑定类型 ServiceAccount
name: nfs-client-provisioner # ServiceAccount 的名称
namespace: prometheus-storage
roleRef:
kind: ClusterRole # 绑定的角色类型
name: nfs-client-provisioner-runner # 集群角色名称 nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
# 角色
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner # 角色的名称,表明它与 NFS 客户端存储提供者的领导者选举(leader election)机制相关。
namespace: prometheus-storage
rules:
- apiGroups: [""] # 空字符串表示核心 API 组(core API group),包含 Kubernetes 的基本资源,如 endpoints。
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
# SA角色绑定
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-leader-locking-nfs-client-provisioner
namespace: prometheus-storage
subjects:
- kind: ServiceAccount # 绑定资源类型为 ServiceAccount
name: nfs-client-provisioner # 绑定的ServiceAccount 名称
namespace: prometheus-storage
roleRef:
kind: Role # 绑定角色(loki-storage名称空间的角色)
apiGroup: rbac.authorization.k8s.io
name: leader-locking-nfs-client-provisioner # 角色的名称执行资源清单
# 创建 StorageClass
$ kubectl apply -f prometheus-storage.yaml
# 查看 StorageClass
$ kubectl get StorageClass
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
loki-storage k8s-sigs.io/nfs-subdir-external-provisioner Delete Immediate false 5d21h
nfs-client k8s-sigs.io/nfs-subdir-external-provisioner Delete Immediate false 6d5h
prometheus-storage k8s-sigs.io/nfs-subdir-external-provisioner Delete Immediate false 11m
# 查看 Pod
$ kubectl get pods -n prometheus-storage -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nfs-client-provisioner-6cb79b9755-7q2t4 1/1 Running 0 11m 192.168.85.207 k8s-node01 <none> <none>三、部署 Prometheus
1. 创建命名空间
资源清单:kube-ops.yaml
# 1.命名空间
apiVersion: v1
kind: Namespace
metadata:
name: kube-ops执行资源清单
# 执行资源清单
$ kubectl apply -f kube-ops.yaml
# 查看命名空间
$ kubectl get namespace | grep kube-ops
kube-ops Active 50s2. 创建Prometheus ConfigMap
资源清单:prometheus-cm.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: kube-ops
data:
prometheus.yml: | # 使用 | 表示 YAML 中的多行文本
global: # 定义 Prometheus 的全局配置,适用于所有抓取任务(除非在具体任务中被覆盖)
scrape_interval: 15s # 表示 prometheus 抓取指标数据的频率,默认是 15s
scrape_timeout: 15s # 表示 prometheus 抓取指标数据的超时时间,默认是 15s
scrape_configs:
- job_name: 'prometheus' # 定义任务名,这里监控 prometheus 自身
static_configs:
- targets: ['localhost:9090']执行资源清单
# 执行资源清单
$ kubectl apply -f prometheus-cm.yaml
# 查看 ConfigMap
$ kubectl get cm -n kube-ops
NAME DATA AGE
kube-root-ca.crt 1 32m
prometheus-config 1 38s3. 部署 Prometheus
资源清单:prometheus.yaml
# 定义 PVC
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: prometheus
namespace: kube-ops
spec:
storageClassName: prometheus-storage # 指定使用的 StorageClass
accessModes:
- ReadWriteMany # 存储卷可以被多个节点(Node)以读写模式同时挂载
resources:
requests:
storage: 10Gi # 定义 PVC 请求的资源量,这里特指存储容量
# 创建 SA
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: kube-ops
# 集群角色
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups:
- ""
resources:
- nodes
- services
- endpoints
- pods
- nodes/proxy
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- configmaps
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
# 集群角色绑定
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: kube-ops
# Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus
namespace: kube-ops
labels:
app: prometheus
spec:
replicas: 1 # Pod 副本数为1
selector:
matchLabels:
app: prometheus
template:
metadata:
labels:
app: prometheus
spec:
serviceAccountName: prometheus # 指定 Pod 使用的 Kubernetes 服务账号(ServiceAccount)为 prometheus
containers:
- name: prometheus
image: prom/prometheus:v2.4.3
imagePullPolicy: IfNotPresent
command:
- "/bin/prometheus" # 指定容器启动时运行的命令为 /bin/prometheus,这是 Prometheus 的主可执行文件
args:
- "--config.file=/etc/prometheus/prometheus.yml" # 指定 Prometheus 的配置文件路径为 /etc/prometheus/prometheus.yml,这个文件由 ConfigMap(prometheus-config)提供,挂载到容器内
- "--storage.tsdb.path=/prometheus" # 指定 Prometheus 时间序列数据库(TSDB)的存储路径为 /prometheus,这个路径由 PVC(prometheus)提供,持久化存储数据
- "--storage.tsdb.retention=24h" # 设置数据保留时间为 24 小时,意味着 Prometheus 只保留最近 24 小时的监控数据,旧数据将被删除。生产环境建议 15-30天
- "--web.enable-admin-api" # 启用 Prometheus 的 Admin HTTP API,允许执行管理操作(如删除时间序列)
- "--web.enable-lifecycle" # 启用生命周期 API,支持通过 HTTP 请求(如 localhost:9090/-/reload)动态重新加载配置文件。
ports:
- containerPort: 9090 # 指定 Prometheus 监听端口,用于提供 Web UI 和 API
protocol: TCP
name: http
volumeMounts: # 定义容器内的挂载点,将卷挂载到指定路径
- mountPath: "/prometheus" # 将名为 data 的卷挂载到容器内的 /prometheus 路径,用于存储 TSDB 数据
subPath: prometheus # 表示使用卷中的子路径 prometheus,避免覆盖整个卷的其他内容
name: data # 卷由 PVC(prometheus)提供
- mountPath: "/etc/prometheus" # 将名为 config-volume 的卷挂载到容器内的 /etc/prometheus 路径,用于存储配置文件
name: config-volume # 由 ConfigMap(prometheus-config)提供
resources:
requests:
cpu: 100m # 请求 100 毫核(0.1 CPU 核心),表示容器需要的最小 CPU 资源
memory: 512Mi # 请求 512 MiB 内存,表示容器需要的最小内存
limits:
cpu: 100m # 限制容器最多使用 100 毫核 CPU,防止过量占用
memory: 512Mi # 限制容器最多使用 512 MiB 内存,防止内存溢出
securityContext: # 定义 Pod 的安全上下文,控制容器运行时的权限
runAsUser: 0 # 指定容器以用户 ID 0(即 root 用户)运行
volumes: # 定义 Pod 使用的卷,供容器挂载
- name: data
persistentVolumeClaim: # 指定挂载的PVC
claimName: prometheus
- name: config-volume
configMap: # 指定挂载的 configMap
name: prometheus-config
# Service
apiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: kube-ops
labels:
app: prometheus
spec:
selector:
app: prometheus
type: NodePort
ports:
- name: web-prometheus # 端口名称
port: 9090 # service 对外端口 9090
targetPort: http # 内部名为 http 的端口 (9090)
# Ingress, 安装参考:https://georgechan95.github.io/blog/6436eaf1.html
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: prometheus-ui
namespace: kube-ops
spec:
ingressClassName: nginx # 指定 Ingress 控制器为 nginx,由 Nginx Ingress Controller 处理
rules:
- host: my.prometheus.com # 定义一个基于域名 my.prometheus.com 的路由规则
http:
paths:
- backend:
service:
name: prometheus # 流量转发到 kube-ops 命名空间中的 prometheus 服务
port:
number: 9090
path: / # 匹配根路径 / 及所有以 / 开头的子路径(如 /graph, /api/v1)
pathType: Prefix执行资源清单
# 执行资源清单
$ kubectl apply -f prometheus.yaml
# 查看PVC
$ kubectl get pvc -n kube-ops
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
prometheus Bound pvc-b85318bf-0ef5-449f-ab40-200238200e10 10Gi RWX prometheus-storage <unset> 3h15m
# 查看 ServiceAccount
$ kubectl get serviceaccount -n kube-ops
NAME SECRETS AGE
default 0 4h4m
prometheus 0 3h11m
# 查看 Deployment
$ kubectl get deploy -n kube-ops
NAME READY UP-TO-DATE AVAILABLE AGE
prometheus 1/1 1 1 125m
# 查看 Pods
$ kubectl get pods -n kube-ops
NAME READY STATUS RESTARTS AGE
prometheus-844847f5c7-7gwck 1/1 Running 0 125m
# 查看 Service
$ kubectl get svc -n kube-ops
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus NodePort 10.102.229.198 <none> 9090:31676/TCP 18m
# 查看 Ingress
$ kubectl get ingress -n kube-ops
NAME CLASS HOSTS ADDRESS PORTS AGE
prometheus-ui nginx my.prometheus.com 80 9m56s添加Host域名映射
10.20.1.140 my.prometheus.com浏览器访问 Prometheus

四、配置 Prometheus 抓取 Ingress-Nginx 指标
1、开启 Ingress-nginx 监听端口
这里的 ingress-nginx 使用的是 helm 安装的,安装过程见:https://georgechan95.github.io/blog/6436eaf1.html
开启 Ingress-nginx 指标监听端口,默认:10254
编辑 value.yaml
metrics:
port: 10254
portName: metrics
# if this port is changed, change healthz-port: in extraArgs: accordingly
enabled: true更新 Ingress-Nginx
$ helm upgrade ingress-nginx -n ingress-nginx -f values.yaml .2. 修改 Prometheus ConfigMap
资源清单:prometheus-cm.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: kube-ops
data:
prometheus.yml: | # 使用 | 表示 YAML 中的多行文本
global: # 定义 Prometheus 的全局配置,适用于所有抓取任务(除非在具体任务中被覆盖)
scrape_interval: 15s # 表示 prometheus 抓取指标数据的频率,默认是 15s
scrape_timeout: 15s # 表示 prometheus 抓取指标数据的超时时间,默认是 15s
scrape_configs:
- job_name: 'prometheus' # 定义任务名,这里监控 prometheus 自身
static_configs:
- targets: ['localhost:9090']
- job_name: 'ingressnginx140' # 10.20.1.140 Ingress-nginx 指标数据抓取
static_configs:
- targets: ['10.20.1.140:10254']
- job_name: 'ingressnginx141' # 10.20.1.141 Ingress-nginx 指标数据抓取
static_configs:
- targets: ['10.20.1.141:10254']
- job_name: 'ingressnginx142' # 10.20.1.142 Ingress-nginx 指标数据抓取
static_configs:
- targets: ['10.20.1.142:10254']重新执行资源清单
方式一:
# 执行资源清单
$ kubectl apply -f prometheus-cm.yaml
$ kubectl get svc -n kube-ops
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus NodePort 10.102.229.198 <none> 9090:31676/TCP 111m
# 请求uri,重新加载
curl -X POST http://10.102.229.198:9090/-/reload方式二:
# 执行资源清单
$ kubectl apply -f prometheus-cm.yaml
# 查看 prometheus pod
$ kubectl get pods -n kube-ops
NAME READY STATUS RESTARTS AGE
prometheus-844847f5c7-7gwck 1/1 Running 0 3h29m
# 杀死重启Pod,重新加载 ConfigMap
$ kubectl delete pod prometheus-844847f5c7-7gwck -n kube-ops
pod "prometheus-844847f5c7-7gwck" deleted再次从浏览器查看 Prometheus
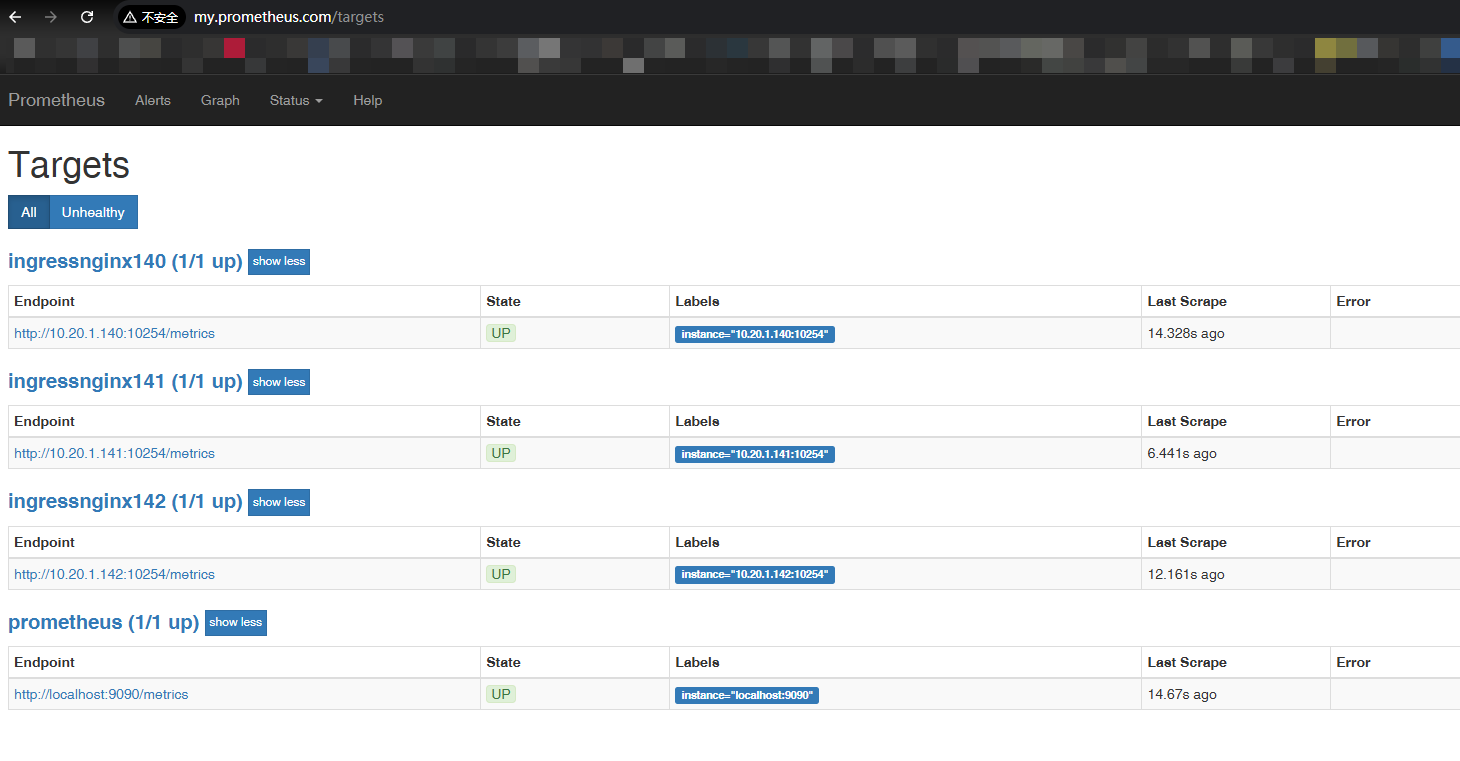
五、创建 node_exporter,监控节点资源
node_exporter 就是抓取用于采集服务器节点的各种运行指标,目前 node_exporter 支持几乎所有常见的监控点,比如 conntrack,cpu,diskstats,filesystem,loadavg,meminfo,netstat 等,详细的监控点列表可以参考其 Node_Exporter
说明:
在 Kubernetes 下,Promethues 通过与 Kubernetes API 集成,目前主要支持5中服务发现模式,分别是:Node、Service、Pod、Endpoints、Ingress
通过指定 kubernetes_sd_configs 的模式为 node,Prometheus 就会自动从 Kubernetes 中发现所有的 node 节点并作为当前 job 监控的目标实例,发现的节点 /metrics 接口是默认的 kubelet 的 HTTP 接口
prometheus 去发现 Node 模式的服务的时候,访问的端口默认是10250,而现在该端口下面已经没有了/metrics指标数据了,现在 kubelet 只读的数据接口统一通过 10255 端口进行暴露了,所以我们应该去替换掉这里的端口,但是我们是要替换成 10255 端口吗?不是的,因为我们是要去配置上面通过node-exporter抓取到的节点指标数据,而我们上面是不是指定了 hostNetwork=true ,所以在每个节点上就会绑定一个端口 9100,所以我们应该将这里的 10250 替换成 9100
这里我们就需要使用到 Prometheus 提供的relabel_configs中的replace能力了,relabel 可以在 Prometheus 采集数据之前,通过Target 实例的 Metadata 信息,动态重新写入 Label 的值。除此之外,我们还能根据 Target 实例的 Metadata 信息选择是否采集或者忽略该 Target 实例
添加了一个 action 为labelmap,正则表达式是__meta_kubernetes_node_label_(.+)的配置,这里的意思就是表达式中匹配都的数据也添加到指标数据的 Label 标签中去。
对于 kubernetes_sd_configs 下面可用的标签如下: 可用元标签:
- __meta_kubernetes_node_name:节点对象的名称
- _meta_kubernetes_node_label:节点对象中的每个标签
- _meta_kubernetes_node_annotation:来自节点对象的每个注释
- _meta_kubernetes_node_address:每个节点地址类型的第一个地址(如果存在) *
关于 kubernets_sd_configs 更多信息可以查看官方文档:kubernetes_sd_config
Kubernetes 1.11+ 版本以后,kubelet 就移除了 10255 端口, metrics 接口又回到了 10250 端口,所以这里不需要替换端口,但是需要使用 https 的协议
1. 部署 node-exporter
资源清单:prometheus-node-exporter.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
namespace: kube-ops
labels:
name: node-exporter
spec:
selector:
matchLabels:
name: node-exporter
template:
metadata:
labels:
name: node-exporter
spec:
hostPID: true # 允许 Pod 使用主机节点的 PID 命名空间, Node Exporter 需要访问主机的 /proc 文件系统以收集进程相关指标(如 CPU、内存使用情况),因此需要 hostPID: true
hostIPC: true # 允许 Pod 使用主机节点的 IPC(进程间通信)命名空间,这通常用于访问主机的共享内存或其他 IPC 机制,但在 Node Exporter 中可能不是必需,建议评估是否需要以降低安全风险。
hostNetwork: true # Pod 使用主机节点的网络命名空间,直接绑定到主机的网络接口和端口,Node Exporter 的端口(9100)将直接绑定到主机网络,便于 Prometheus 抓取节点的指标(如通过节点 IP:9100)
containers:
- name: node-exporter
image: prom/node-exporter:v0.16.0 # Node Exporter 收集主机系统的指标(如 CPU、内存、磁盘、文件系统等)并通过 HTTP 端点(默认 /metrics)暴露
imagePullPolicy: IfNotPresent
ports:
- containerPort: 9100 # Node Exporter 监听 9100 端口,暴露 Prometheus 格式的指标端点(默认 /metrics)
resources:
requests:
cpu: 0.15 # 请求 0.15 CPU 核心(150 毫核),表示 Node Exporter 的最小 CPU 需求
securityContext:
privileged: true # 容器以特权模式运行,拥有对主机的广泛访问权限
args:
- --path.procfs # 指定进程文件系统路径为 /host/proc,映射到主机的 /proc,用于收集进程、CPU、内存等指标
- /host/proc
- --path.sysfs # 指定系统文件系统路径为 /host/sys,映射到主机的 /sys,用于收集硬件相关指标(如设备信息)
- /host/sys
- --collector.filesystem.ignored-mount-points # 配置文件系统收集器,忽略以 /sys, /proc, /dev, /host, /etc 开头的挂载点,防止收集容器内部或无关的文件系统指标,专注于主机文件系统
- '"^/(sys|proc|dev|host|etc)($|/)"'
volumeMounts:
- name: dev
mountPath: /host/dev # 挂载主机的 /dev 到容器内的 /host/dev
- name: proc
mountPath: /host/proc # 挂载主机的 /proc 到 /host/proc
- name: sys
mountPath: /host/sys # 挂载主机的 /sys 到 /host/sys
- name: rootfs
mountPath: /rootfs # 挂载主机的根文件系统(/)到 /rootfs
tolerations:
- key: "node-role.kubernetes.io/control-plane" # 允许 Pod 调度到带有 node-role.kubernetes.io/control-plane 污点的节点
operator: Exists
effect: NoSchedule
volumes: # 定义 Pod 使用的卷,映射主机文件系统到容器
- name: proc
hostPath:
path: /proc
- name: dev
hostPath:
path: /dev
- name: sys
hostPath:
path: /sys
- name: rootfs
hostPath:
path: /执行资源清单
# 执行资源清单,创建 node-exporter
$ kubectl apply -f prometheus-node-exporter.yaml
# 查看 Pod
$ kubectl get pods -n kube-ops
NAME READY STATUS RESTARTS AGE
node-exporter-d85s5 1/1 Running 0 165m
node-exporter-gmwln 1/1 Running 0 165m
node-exporter-kjdm9 1/1 Running 0 165m
node-exporter-vg29l 1/1 Running 0 165m
prometheus-844847f5c7-2zvbn 1/1 Running 0 17h2. 修改 Prometheus ConfigMap
资源清单:prometheus-cm.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: kube-ops
data:
prometheus.yml: | # 使用 | 表示 YAML 中的多行文本
global: # 定义 Prometheus 的全局配置,适用于所有抓取任务(除非在具体任务中被覆盖)
scrape_interval: 15s # 表示 prometheus 抓取指标数据的频率,默认是 15s
scrape_timeout: 15s # 表示 prometheus 抓取指标数据的超时时间,默认是 15s
scrape_configs:
- job_name: 'prometheus' # 定义任务名,这里监控 prometheus 自身
static_configs:
- targets: ['localhost:9090']
- job_name: 'ingressnginx140' # 10.20.1.140 Ingress-nginx 指标数据抓取
static_configs:
- targets: ['10.20.1.140:10254']
- job_name: 'ingressnginx141' # 10.20.1.141 Ingress-nginx 指标数据抓取
static_configs:
- targets: ['10.20.1.141:10254']
- job_name: 'ingressnginx142' # 10.20.1.142 Ingress-nginx 指标数据抓取
static_configs:
- targets: ['10.20.1.142:10254']
- job_name: 'kubernetes-nodes' # 基于Node自动发现节点,并抓取指标信息。Node Exporter:提供系统级指标,适合监控节点的硬件和操作系统状态(如磁盘 I/O、网络流量)。
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__] # 默认抓取节点的 Kubelet 端点(端口 10250,/metrics),但这里通过 relabel_configs 修改为 Node Exporter 的端口(9100)
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- action: labelmap # 将 Kubernetes 节点的标签(__meta_kubernetes_node_label_<key>)映射为 Prometheus 指标的标签
regex: __meta_kubernetes_node_label_(.+)
- job_name: 'kubernetes-kubelet' # 基于Node发现,从 Kubelet 抓取指标信息。Kubelet:提供 Kubernetes 特定指标,如 Pod 运行状态、Kubelet 的健康状况和 API 请求统计。
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt # k8s 自动为pod挂载的证书文件路径,在pod内部
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token # k8s 自动为pod挂载的token文件路径,在pod内部
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+) # 将 Kubernetes 节点的标签(__meta_kubernetes_node_label_<key>)映射为 Prometheus 指标的标签重新执行资源清单
# 执行更新 ConfigMap 资源清单
$ kubectl apply -f prometheus-cm.yaml
# 等待一会,待ConfigMap更新后,执行请求,让 Prometheus 配置热更新
$ kubectl get svc -n kube-ops
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus NodePort 10.102.229.198 <none> 9090:31676/TCP 18h
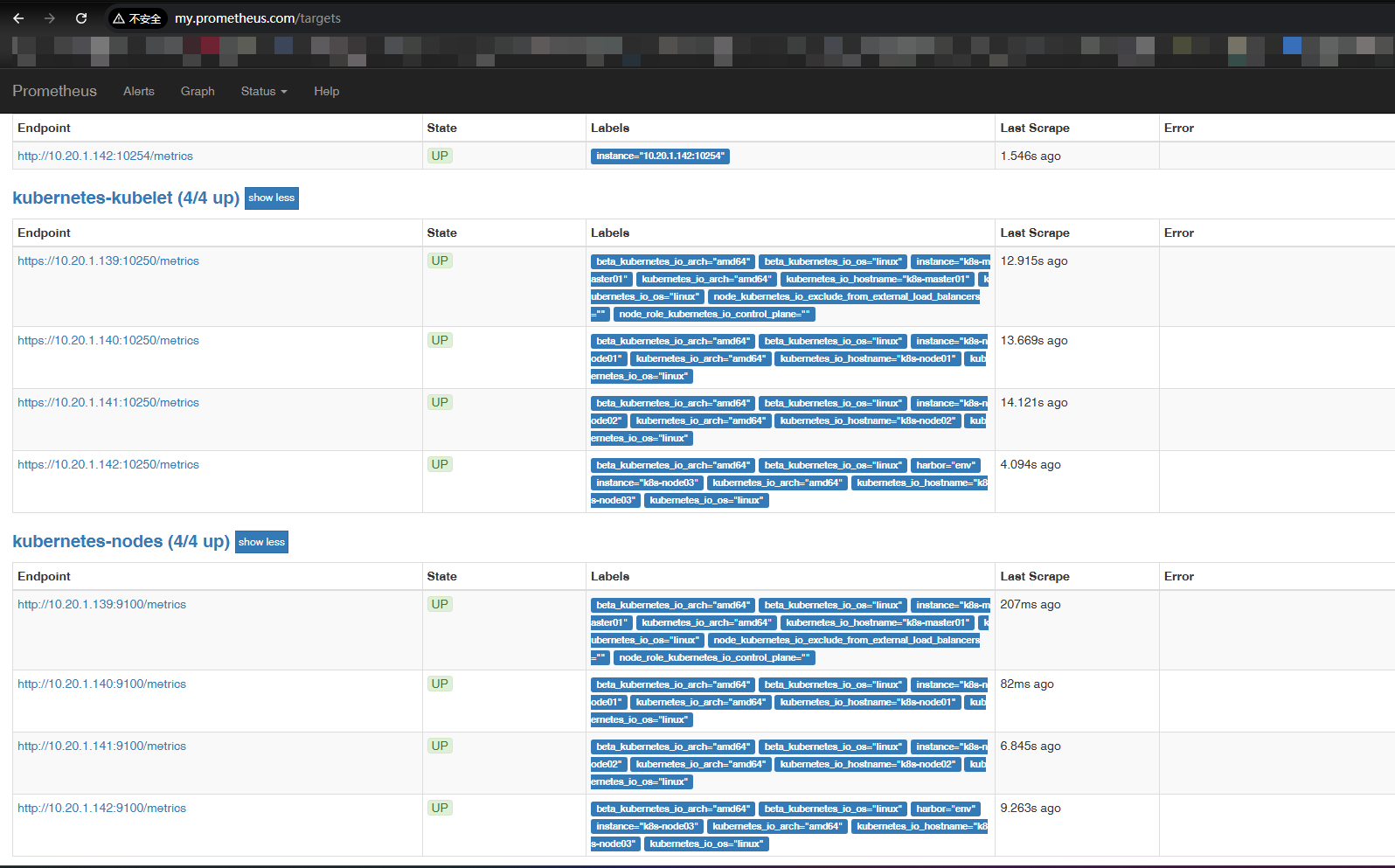
$ curl -X POST http://10.102.229.198:9090/-/reload再次从浏览器查看 Prometheus 控制台,发现 node_exporter 和 kubelet 已被监听
六、使用 cAdvisor 监控容器资源指标
说到容器监控我们自然会想到 cAdvisor,我们前面也说过cAdvisor已经内置在了 kubelet 组件之中,所以我们不需要单独去安装,cAdvisor 的数据路径为/api/v1/nodes/<node>/proxy/metrics,同样我们这里使用 node 的服务发现模式,因为每一个节点下面都有 kubelet
1. 修改 Prometheus ConfigMap
资源清单:prometheus-cm.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: kube-ops
data:
prometheus.yml: | # 使用 | 表示 YAML 中的多行文本
global: # 定义 Prometheus 的全局配置,适用于所有抓取任务(除非在具体任务中被覆盖)
scrape_interval: 15s # 表示 prometheus 抓取指标数据的频率,默认是 15s
scrape_timeout: 15s # 表示 prometheus 抓取指标数据的超时时间,默认是 15s
scrape_configs:
- job_name: 'prometheus' # 定义任务名,这里监控 prometheus 自身
static_configs:
- targets: ['localhost:9090']
- job_name: 'ingressnginx140' # 10.20.1.140 Ingress-nginx 指标数据抓取
static_configs:
- targets: ['10.20.1.140:10254']
- job_name: 'ingressnginx141' # 10.20.1.141 Ingress-nginx 指标数据抓取
static_configs:
- targets: ['10.20.1.141:10254']
- job_name: 'ingressnginx142' # 10.20.1.142 Ingress-nginx 指标数据抓取
static_configs:
- targets: ['10.20.1.142:10254']
- job_name: 'kubernetes-nodes' # 基于Node自动发现节点,并抓取指标信息。Node Exporter:提供系统级指标,适合监控节点的硬件和操作系统状态(如磁盘 I/O、网络流量)。
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__] # 默认抓取节点的 Kubelet 端点(端口 10250,/metrics),但这里通过 relabel_configs 修改为 Node Exporter 的端口(9100)
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- action: labelmap # 将 Kubernetes 节点的标签(__meta_kubernetes_node_label_<key>)映射为 Prometheus 指标的标签
regex: __meta_kubernetes_node_label_(.+)
- job_name: 'kubernetes-kubelet' # 基于Node发现,从 Kubelet 抓取指标信息。Kubelet:提供 Kubernetes 特定指标,如 Pod 运行状态、Kubelet 的健康状况和 API 请求统计。
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt # k8s 自动为pod挂载的证书文件路径,在pod内部
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token # k8s 自动为pod挂载的token文件路径,在pod内部
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+) # 将 Kubernetes 节点的标签(__meta_kubernetes_node_label_<key>)映射为 Prometheus 指标的标签
- job_name: 'kubernetes-cadvisor' # 抓取任务名称为 kubernetes-cadvisor,用于监控 Kubernetes 节点的 cAdvisor 指标
kubernetes_sd_configs:
- role: node
scheme: https # 指定使用 HTTPS 协议访问目标(Kubernetes API 服务器的 443 端口)
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt # 使用 Pod 内部的服务账号卷挂载的 CA 证书
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token # 使用服务账号的 Bearer 令牌
relabel_configs: # 定义标签重写规则,修改服务发现的目标地址和路径
- action: labelmap # 规则1:将节点的标签(如 kubernetes.io/hostname)映射到 Prometheus 指标标签
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443 # 规则2:将抓取目标地址设置为 kubernetes.default.svc:443,即 Kubernetes API 服务器的 ClusterIP 服务(默认命名空间 default,端口 443)
- source_labels: [__meta_kubernetes_node_name] # 规则3:使用节点名称(__meta_kubernetes_node_name,如 node01)动态构造指标路径
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor重新执行资源清单
# 执行更新 ConfigMap 资源清单
$ kubectl apply -f prometheus-cm.yaml
# 等待一会,待ConfigMap更新后,执行请求,让 Prometheus 配置热更新
$ kubectl get svc -n kube-ops
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus NodePort 10.102.229.198 <none> 9090:31676/TCP 18h
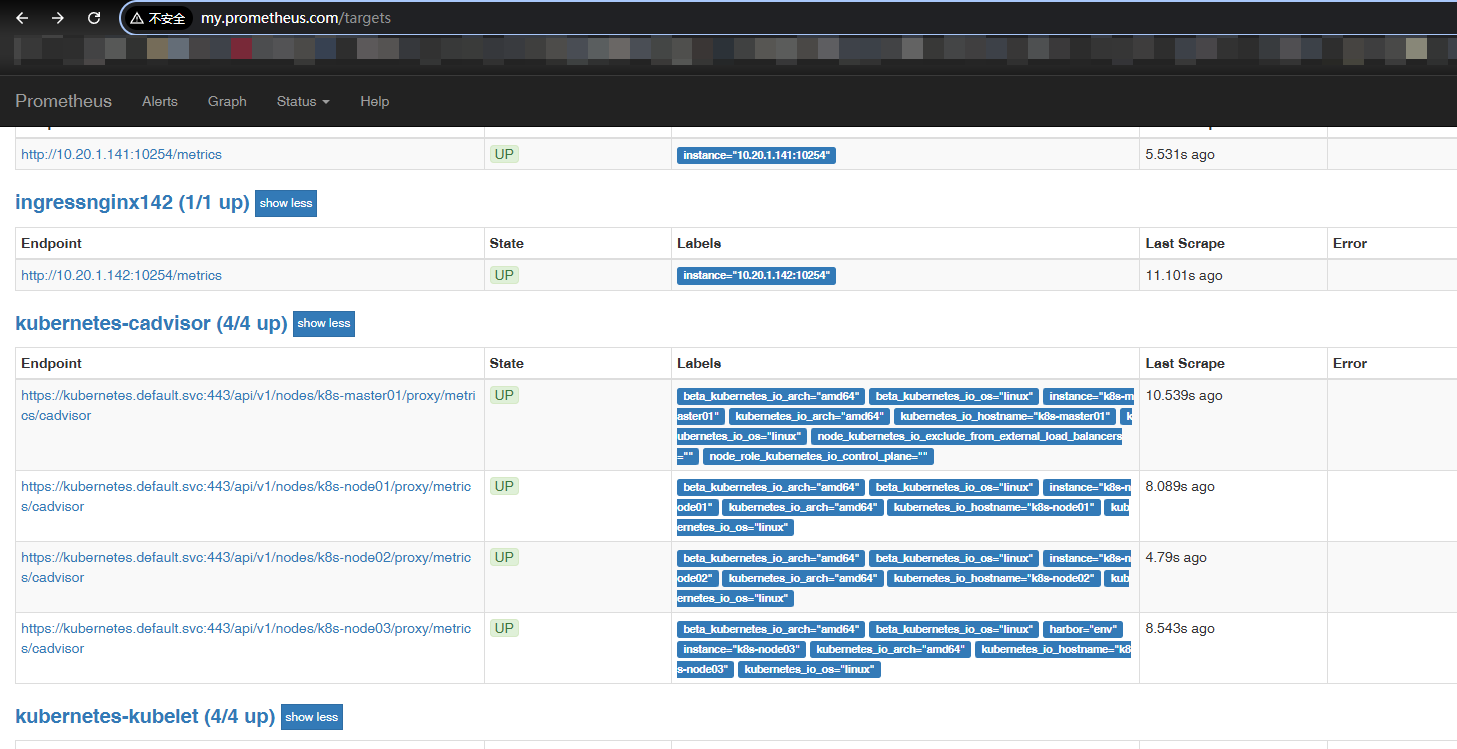
$ curl -X POST http://10.102.229.198:9090/-/reload再次从浏览器查看 Prometheus 控制台,发现 cAdvisor 已被监听
七、Prometheus 监控 kube-apiserver
kube-apiserver 监听在节点的 6443 端口,通过以下配置可以使 Prometheus 读取 kube-apiserver 的指标数据
1. 修改 Prometheus ConfigMap
资源清单:prometheus-cm.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: kube-ops
data:
prometheus.yml: | # 使用 | 表示 YAML 中的多行文本
global: # 定义 Prometheus 的全局配置,适用于所有抓取任务(除非在具体任务中被覆盖)
scrape_interval: 15s # 表示 prometheus 抓取指标数据的频率,默认是 15s
scrape_timeout: 15s # 表示 prometheus 抓取指标数据的超时时间,默认是 15s
scrape_configs:
- job_name: 'prometheus' # 定义任务名,这里监控 prometheus 自身
static_configs:
- targets: ['localhost:9090']
- job_name: 'ingressnginx140' # 10.20.1.140 Ingress-nginx 指标数据抓取
static_configs:
- targets: ['10.20.1.140:10254']
- job_name: 'ingressnginx141' # 10.20.1.141 Ingress-nginx 指标数据抓取
static_configs:
- targets: ['10.20.1.141:10254']
- job_name: 'ingressnginx142' # 10.20.1.142 Ingress-nginx 指标数据抓取
static_configs:
- targets: ['10.20.1.142:10254']
- job_name: 'kubernetes-nodes' # 基于Node自动发现节点,并抓取指标信息。Node Exporter:提供系统级指标,适合监控节点的硬件和操作系统状态(如磁盘 I/O、网络流量)。
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__] # 默认抓取节点的 Kubelet 端点(端口 10250,/metrics),但这里通过 relabel_configs 修改为 Node Exporter 的端口(9100)
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- action: labelmap # 将 Kubernetes 节点的标签(__meta_kubernetes_node_label_<key>)映射为 Prometheus 指标的标签
regex: __meta_kubernetes_node_label_(.+)
- job_name: 'kubernetes-kubelet' # 基于Node发现,从 Kubelet 抓取指标信息。Kubelet:提供 Kubernetes 特定指标,如 Pod 运行状态、Kubelet 的健康状况和 API 请求统计。
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt # k8s 自动为pod挂载的证书文件路径,在pod内部
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token # k8s 自动为pod挂载的token文件路径,在pod内部
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+) # 将 Kubernetes 节点的标签(__meta_kubernetes_node_label_<key>)映射为 Prometheus 指标的标签
- job_name: 'kubernetes-cadvisor' # 抓取任务名称为 kubernetes-cadvisor,用于监控 Kubernetes 节点的 cAdvisor 指标
kubernetes_sd_configs:
- role: node
scheme: https # 指定使用 HTTPS 协议访问目标(Kubernetes API 服务器的 443 端口)
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt # 使用 Pod 内部的服务账号卷挂载的 CA 证书
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token # 使用服务账号的 Bearer 令牌
relabel_configs: # 定义标签重写规则,修改服务发现的目标地址和路径
- action: labelmap # 规则1:将节点的标签(如 kubernetes.io/hostname)映射到 Prometheus 指标标签
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443 # 规则2:将抓取目标地址设置为 kubernetes.default.svc:443,即 Kubernetes API 服务器的 ClusterIP 服务(默认命名空间 default,端口 443)
- source_labels: [__meta_kubernetes_node_name] # 规则3:使用节点名称(__meta_kubernetes_node_name,如 node01)动态构造指标路径
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
- job_name: 'kubernetes-apiservers' # 抓取任务名称为 kubernetes-apiservers,用于监控 Kubernetes API 服务器的指标,包括请求速率、延迟、错误率等(如 apiserver_request_total, apiserver_request_duration_seconds)
kubernetes_sd_configs:
- role: endpoints # 使用 Kubernetes 服务发现,角色为 endpoints,发现集群中的所有 Endpoints 对象
scheme: https # Kubernetes API 服务器默认通过 HTTPS(端口 443)暴露 /metrics 端点
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt # 使用 Prometheus Pod 内部的服务账号卷挂载的 CA 证书(位于 /var/run/secrets/kubernetes.io/serviceaccount/ca.crt)验证 API 服务器的 TLS 证书
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token # 使用服务账号的 Bearer 令牌(位于 /var/run/secrets/kubernetes.io/serviceaccount/token)进行身份验证
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] # 断点所在的名称空间,断点所在的 Service, 断点端口名称
action: keep # 仅保留匹配正则表达式的端点,未匹配的端点被丢弃。
regex: default;kubernetes;https # 确保 Prometheus 只抓取 default 命名空间中 kubernetes 服务的 HTTPS 端点(即 API 服务器的 /metrics)重新执行资源清单
# 执行更新 ConfigMap 资源清单
$ kubectl apply -f prometheus-cm.yaml
# 等待一会,待ConfigMap更新后,执行请求,让 Prometheus 配置热更新
$ kubectl get svc -n kube-ops
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus NodePort 10.102.229.198 <none> 9090:31676/TCP 18h
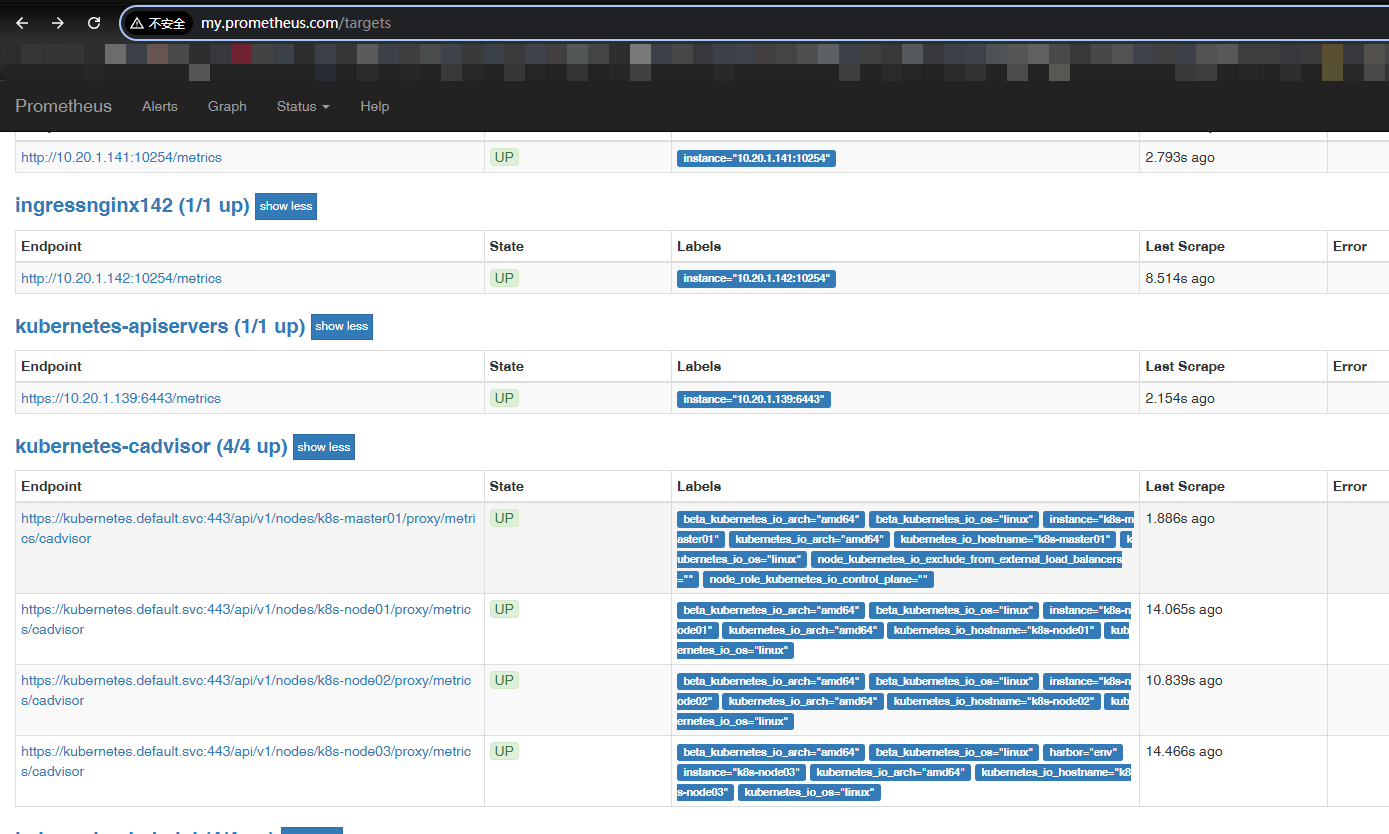
$ curl -X POST http://10.102.229.198:9090/-/reload再次从浏览器查看 Prometheus 控制台,发现 apiServer 已被监听
八、Prometheus 通过 Service 监控服务
1. 修改 Prometheus ConfigMap
资源清单:prometheus-cm.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: kube-ops
data:
prometheus.yml: | # 使用 | 表示 YAML 中的多行文本
global: # 定义 Prometheus 的全局配置,适用于所有抓取任务(除非在具体任务中被覆盖)
scrape_interval: 15s # 表示 prometheus 抓取指标数据的频率,默认是 15s
scrape_timeout: 15s # 表示 prometheus 抓取指标数据的超时时间,默认是 15s
scrape_configs:
- job_name: 'prometheus' # 定义任务名,这里监控 prometheus 自身
static_configs:
- targets: ['localhost:9090']
- job_name: 'ingressnginx140' # 10.20.1.140 Ingress-nginx 指标数据抓取
static_configs:
- targets: ['10.20.1.140:10254']
- job_name: 'ingressnginx141' # 10.20.1.141 Ingress-nginx 指标数据抓取
static_configs:
- targets: ['10.20.1.141:10254']
- job_name: 'ingressnginx142' # 10.20.1.142 Ingress-nginx 指标数据抓取
static_configs:
- targets: ['10.20.1.142:10254']
- job_name: 'kubernetes-nodes' # 基于Node自动发现节点,并抓取指标信息。Node Exporter:提供系统级指标,适合监控节点的硬件和操作系统状态(如磁盘 I/O、网络流量)。
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__] # 默认抓取节点的 Kubelet 端点(端口 10250,/metrics),但这里通过 relabel_configs 修改为 Node Exporter 的端口(9100)
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- action: labelmap # 将 Kubernetes 节点的标签(__meta_kubernetes_node_label_<key>)映射为 Prometheus 指标的标签
regex: __meta_kubernetes_node_label_(.+)
- job_name: 'kubernetes-kubelet' # 基于Node发现,从 Kubelet 抓取指标信息。Kubelet:提供 Kubernetes 特定指标,如 Pod 运行状态、Kubelet 的健康状况和 API 请求统计。
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt # k8s 自动为pod挂载的证书文件路径,在pod内部
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token # k8s 自动为pod挂载的token文件路径,在pod内部
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+) # 将 Kubernetes 节点的标签(__meta_kubernetes_node_label_<key>)映射为 Prometheus 指标的标签
- job_name: 'kubernetes-cadvisor' # 抓取任务名称为 kubernetes-cadvisor,用于监控 Kubernetes 节点的 cAdvisor 指标
kubernetes_sd_configs:
- role: node
scheme: https # 指定使用 HTTPS 协议访问目标(Kubernetes API 服务器的 443 端口)
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt # 使用 Pod 内部的服务账号卷挂载的 CA 证书
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token # 使用服务账号的 Bearer 令牌
relabel_configs: # 定义标签重写规则,修改服务发现的目标地址和路径
- action: labelmap # 规则1:将节点的标签(如 kubernetes.io/hostname)映射到 Prometheus 指标标签
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443 # 规则2:将抓取目标地址设置为 kubernetes.default.svc:443,即 Kubernetes API 服务器的 ClusterIP 服务(默认命名空间 default,端口 443)
- source_labels: [__meta_kubernetes_node_name] # 规则3:使用节点名称(__meta_kubernetes_node_name,如 node01)动态构造指标路径
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
- job_name: 'kubernetes-apiservers' # 抓取任务名称为 kubernetes-apiservers,用于监控 Kubernetes API 服务器的指标,包括请求速率、延迟、错误率等(如 apiserver_request_total, apiserver_request_duration_seconds)
kubernetes_sd_configs:
- role: endpoints # 使用 Kubernetes 服务发现,角色为 endpoints,发现集群中的所有 Endpoints 对象
scheme: https # Kubernetes API 服务器默认通过 HTTPS(端口 443)暴露 /metrics 端点
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt # 使用 Prometheus Pod 内部的服务账号卷挂载的 CA 证书(位于 /var/run/secrets/kubernetes.io/serviceaccount/ca.crt)验证 API 服务器的 TLS 证书
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token # 使用服务账号的 Bearer 令牌(位于 /var/run/secrets/kubernetes.io/serviceaccount/token)进行身份验证
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] # 断点所在的名称空间,断点所在的 Service, 断点端口名称
action: keep # 仅保留匹配正则表达式的端点,未匹配的端点被丢弃。
regex: default;kubernetes;https # 确保 Prometheus 只抓取 default 命名空间中 kubernetes 服务的 HTTPS 端点(即 API 服务器的 /metrics)
- job_name: 'kubernetes-service-endpoints' # 抓取任务名称为 kubernetes-service-endpoints,用于监控 Kubernetes Service 的 Endpoints 指标。
kubernetes_sd_configs:
- role: endpoints # 使用 Kubernetes 服务发现,角色为 endpoints,发现集群中所有 Service 的 Endpoints 对象
relabel_configs: # 定义标签重写规则,过滤和配置服务发现的目标,确保只抓取符合条件的 Service Endpoints
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep # 仅保留注解 prometheus.io/scrape: "true" 的 Service Endpoints,未匹配的被丢弃
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace # 将匹配的值替换到 __scheme__ 标签,决定抓取协议(http 或 https),允许 Service 指定是否通过 HTTPS 抓取指标,适用于需要安全连接的场景
target_label: __scheme__
regex: (https?) # 匹配 http 或 https,若注解未设置,默认使用 http
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace # 检查 Service 的注解 prometheus.io/path,将匹配的值替换到 __metrics_path__ 标签,指定指标端点的路径
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace # 将地址和端口组合替换到 __address__ 标签,允许 Service 指定抓取端口(如 prometheus.io/port: "8080"),覆盖 Endpoints 的默认端口
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap # 将 Service 的标签(如 app=my-app)映射到 Prometheus 指标标签
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace] # 将 Service 的命名空间(__meta_kubernetes_namespace)写入指标标签 kubernetes_namespace
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name] # 将 Service 名称(__meta_kubernetes_service_name)写入指标标签 kubernetes_name
action: replace
target_label: kubernetes_name重新执行资源清单
# 执行更新 ConfigMap 资源清单
$ kubectl apply -f prometheus-cm.yaml
# 等待一会,待ConfigMap更新后,执行请求,让 Prometheus 配置热更新
$ kubectl get svc -n kube-ops
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus NodePort 10.102.229.198 <none> 9090:31676/TCP 18h
$ curl -X POST http://10.102.229.198:9090/-/reload再次从浏览器查看 Prometheus 控制台,发现 Service 已被监听
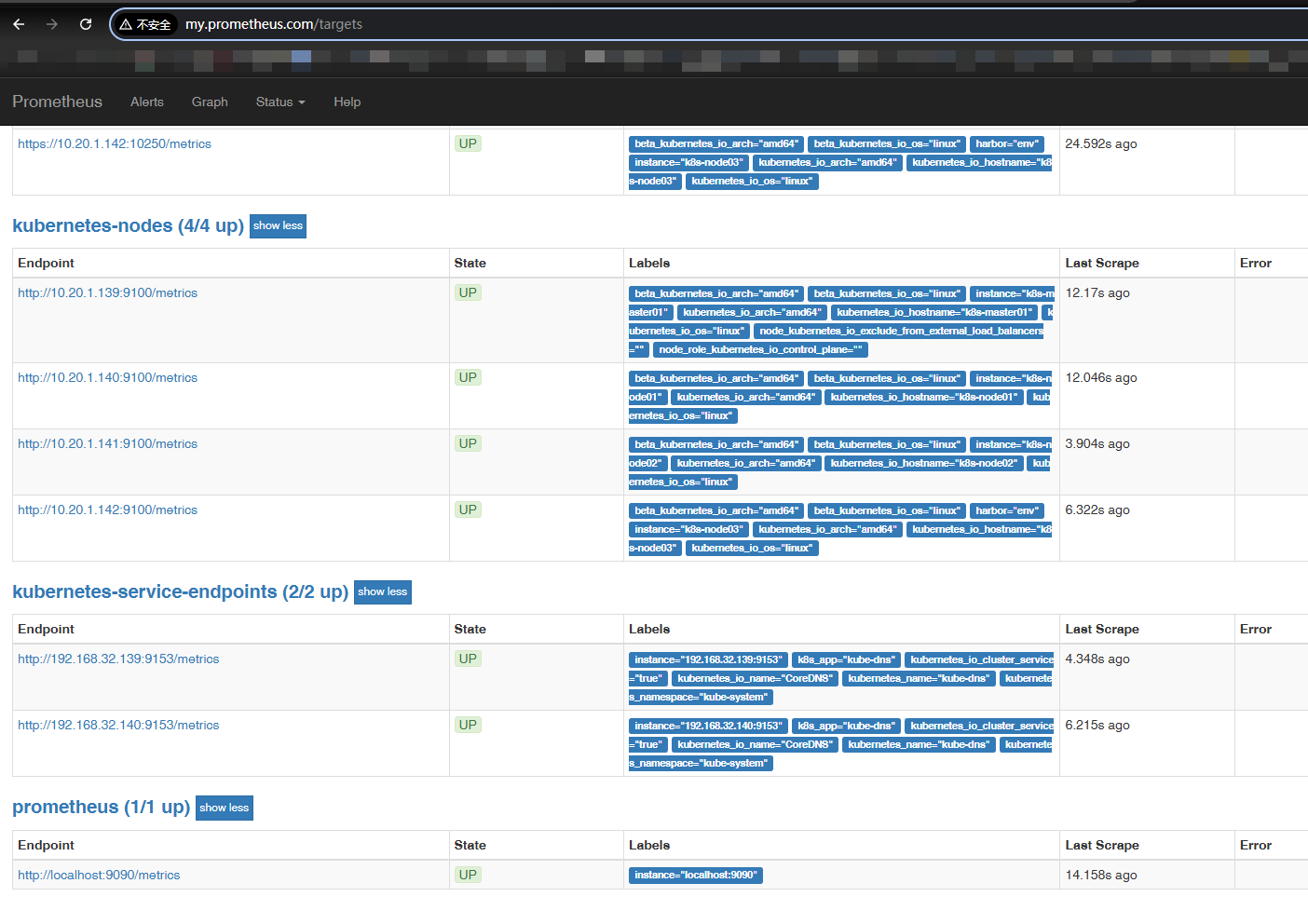
九、部署 kube-state-metrics,并使用 Prometheus 监控
1. 部署 kube-state-metrics
# 克隆 kube-state-metrics 仓库代码
git clone https://github.com/kubernetes/kube-state-metrics.git
# 克隆后,进入资源清单目录
cd kube-state-metrics/examples/standard
# 修改 service.yaml
$ vim service.yaml
# 添加 annotations 信息,用于被prometheus发现
metadata:
annotations:
prometheus.io/scrape: 'true'
prometheus.io/port: "8080"
# 执行所有资源清单,注意:这里是 -k 不是 -f
$ kubectl apply -k .查看部署资源
# 查看 Service
$ kubectl get pods -n kube-system | grep kube-state-metrics
kube-state-metrics-54c8f8787f-6jnp5 1/1 Running 0 107s
# 查看 Pod
$ kubectl get svc -n kube-system | grep kube-state-metrics
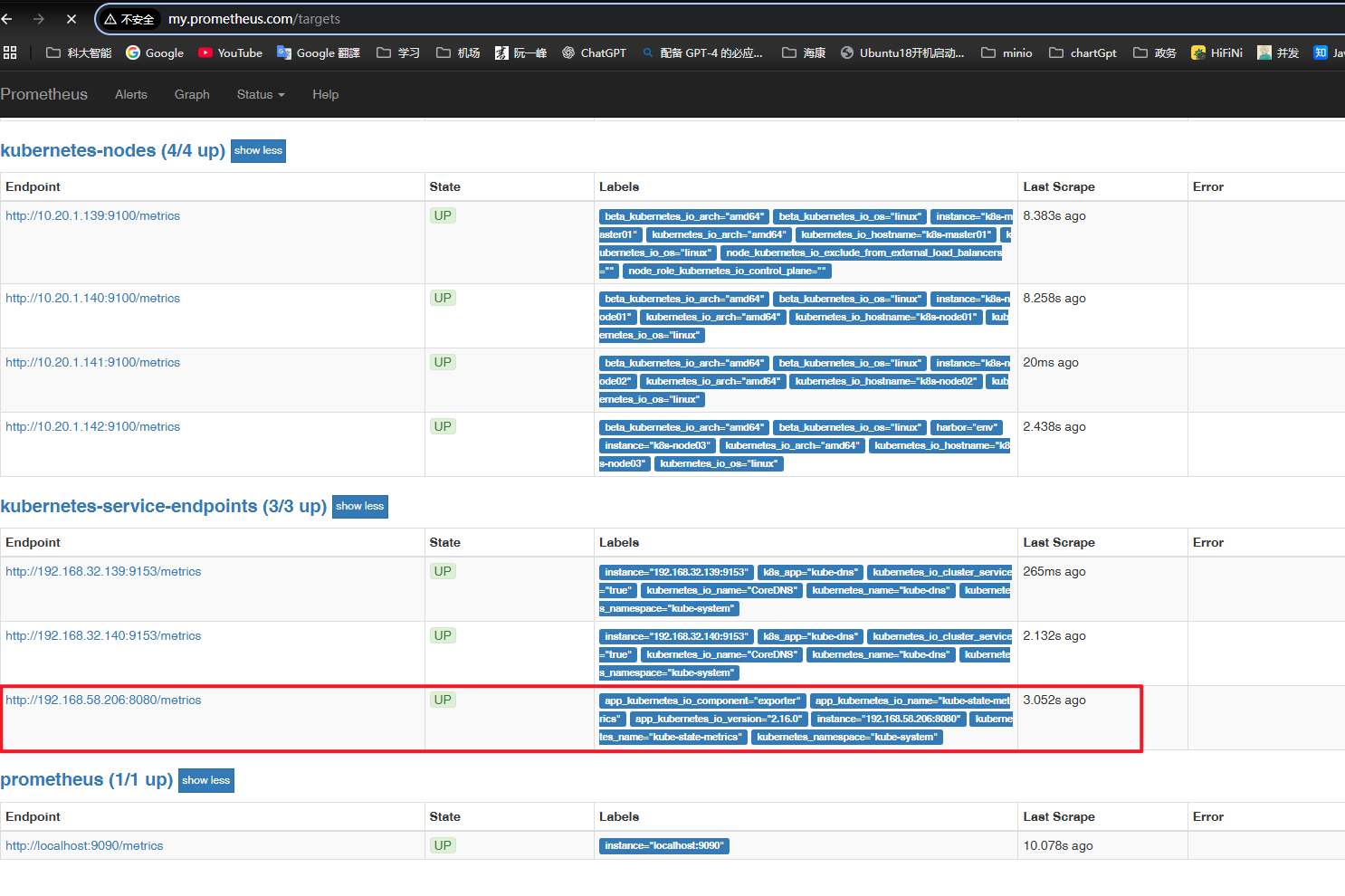
kube-state-metrics ClusterIP None <none> 8080/TCP,8081/TCP 119s部署完成后,等待一会,等待 Prometheus 抓取 kube-state-metrics 指标信息。
在浏览器查看 Prometheus ,kube-state-metrics 信息已经被成功抓取。
十、部署 Grafana
用于展示 Prometheus 抓取保存的指标数据
资源清单:prometheus-grafana.yaml
# 1.声明 PVC ,使用 StorageClass 动态创建PV
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana-pvc
namespace: kube-ops
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
storageClassName: prometheus-storage # 使用 StorageClass 动态创建PV
volumeMode: Filesystem
# 2.创建Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: grafana
name: grafana
namespace: kube-ops
spec:
replicas: 1
selector:
matchLabels:
app: grafana
template:
metadata:
labels:
app: grafana
spec:
securityContext:
fsGroup: 472
supplementalGroups:
- 0
containers:
- name: grafana
image: grafana/grafana:8.3.5
imagePullPolicy: IfNotPresent
env: # 设置grafana初始华用户名和密码
- name: GF_SECURITY_ADMIN_USER
value: admin
- name: GF_SECURITY_ADMIN_PASSWORD
value: admin
ports:
- containerPort: 3000
name: http-grafana
protocol: TCP
readinessProbe: # 就绪探测
failureThreshold: 10
httpGet:
path: /api/health
port: 3000
scheme: HTTP
initialDelaySeconds: 60 # 延迟 60秒探测,等待job执行完成
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 30
livenessProbe: # 存活探测
failureThreshold: 3
httpGet:
path: /api/health
port: 3000
scheme: HTTP
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
resources:
requests:
cpu: 500m
memory: 1024Mi
limits:
cpu: 1000m
memory: 2048Mi
volumeMounts:
- mountPath: /var/lib/grafana
subPath: grafana
name: grafana-pv
securityContext: # 容器以用户id 472 运行
runAsUser: 472
volumes: # 挂载容器卷
- name: grafana-pv
persistentVolumeClaim:
claimName: grafana-pvc # 使用声明的PVC,通过 StorageClass 动态创建PV
nodeSelector: # 指定Pod运行的节点
kubernetes.io/hostname: k8s-node02
# 3.创建Service
apiVersion: v1
kind: Service
metadata:
name: grafana
namespace: kube-ops
spec:
ports:
- port: 3000
protocol: TCP
targetPort: http-grafana
nodePort: 30339
selector:
app: grafana
type: NodePort
# 创建 job,调整 grafana 挂载目录权限
apiVersion: batch/v1
kind: Job
metadata:
name: grafana-chown
namespace: kube-ops
spec:
template:
spec:
restartPolicy: Never
containers:
- name: grafana-chown
command: ["chown", "-R", "472:472", "/var/lib/grafana"]
image: busybox:1.37.0
imagePullPolicy: IfNotPresent
volumeMounts:
- name: storage
subPath: grafana
mountPath: /var/lib/grafana
volumes:
- name: storage
persistentVolumeClaim:
claimName: grafana-pvc
# 4.创建 Ingress
apiVersion: networking.k8s.io/v1 # 指定 API 版本
kind: Ingress
metadata:
name: grafana-ui
namespace: kube-ops
labels:
k8s-app: grafana
spec:
ingressClassName: nginx # 指定此 Ingress 资源由名称为 nginx 的 IngressClass 处理
rules:
- host: prom.grafana.com # 指定此规则适用于请求的 HTTP 主机头(Host Header)为 prom.grafana.com 的流量。客户端必须通过该域名访问
http:
paths:
- path: / # 指定匹配的 URL 路径为 /,即根路径,表示匹配所有以 / 开头的请求
pathType: Prefix # 定义路径匹配的类型为 Prefix,表示匹配以指定路径(/) 开头的所有请求
backend:
service:
name: grafana # 指定后端服务的名称为 nginx-svc.(必须存在于同一命名空间,或通过 <namespace>/<service-name> 跨命名空间引用)
port:
number: 3000 # 指定目标 Service 的端口为 80执行资源清单
# 执行资源清单
$ kubectl apply -f prometheus-grafana.yaml
# 查看 NFS Server 挂载目录权限
$ cd /root/data/prometheus/kube-ops/grafana-pvc/
$ ll
total 0
drwxrwxrwx 6 472 472 77 Jul 23 20:19 grafana
# 查看 Service
$ kubectl get svc -n kube-ops | grep grafana
grafana NodePort 10.109.7.30 <none> 3000:30339/TCP 8m33s
# 查看 Pod
$ kubectl get pods -n kube-ops | grep grafana
grafana-b85d687cc-gtrhh 1/1 Running 0 8m41s
grafana-chown-z55rs 0/1 Completed 0 8m41s
# 查看 Job
$ kubectl get job -n kube-ops | grep grafana
grafana-chown 1/1 4s 8m50s添加 Host 域名映射
10.20.1.140 prom.grafana.com浏览器访问 Grafana
用户名/密码:admin/admin
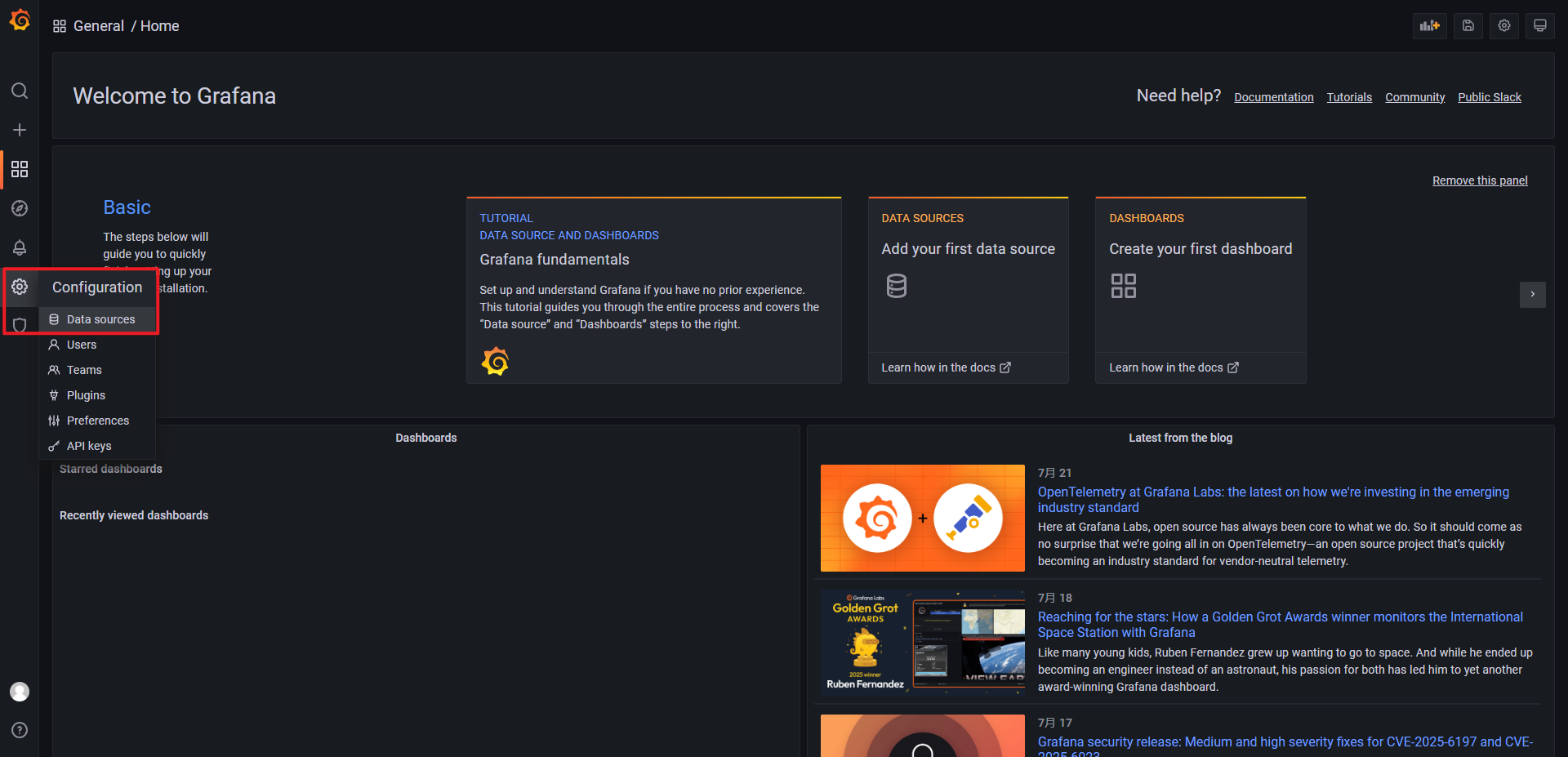
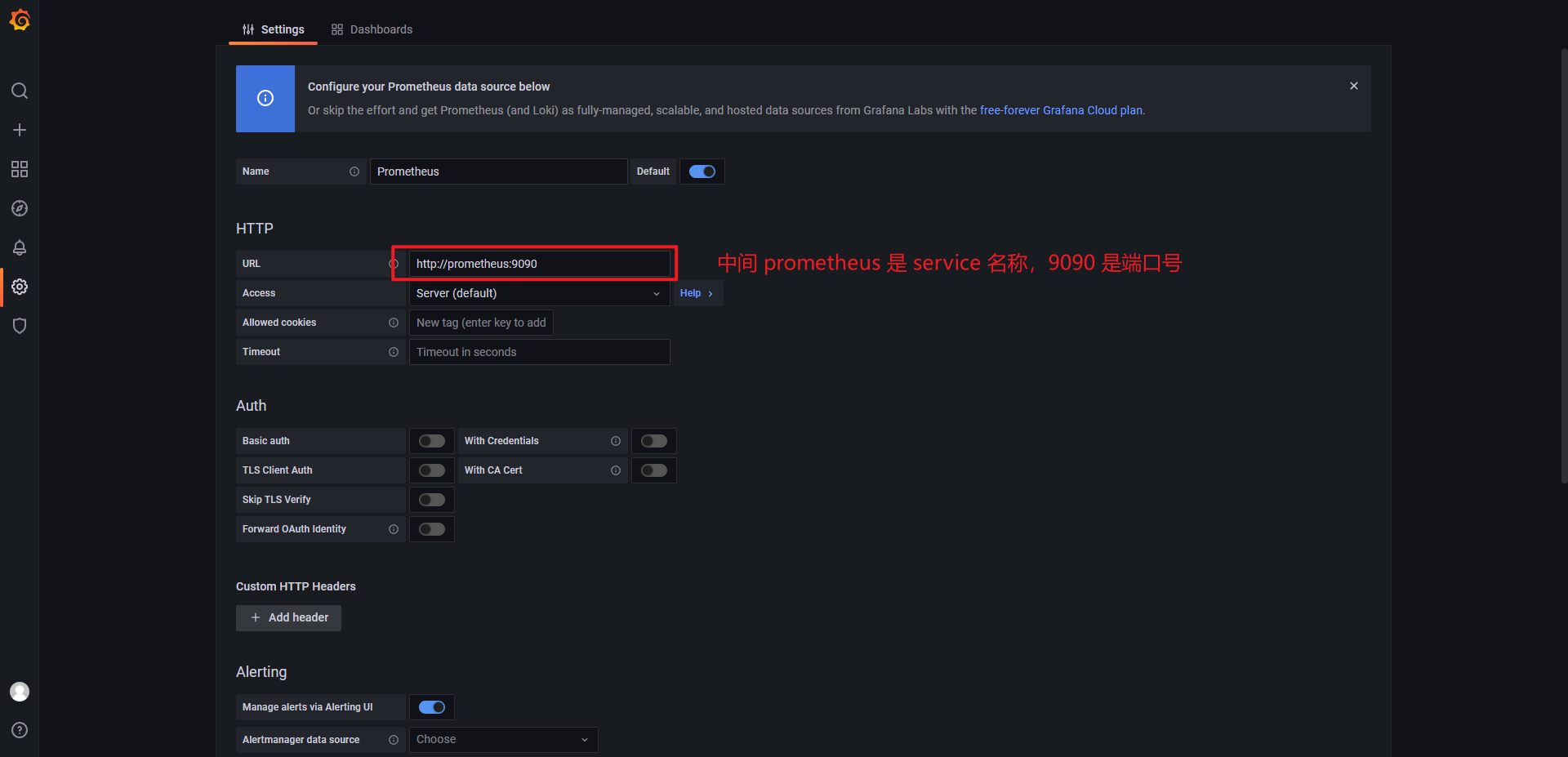
添加Prometheus数据源
导入监控配置Json文件
文件内容如下
{"__inputs":[{"name":"DS_PROMETHEUS","label":"prometheus","description":"","type":"datasource","pluginId":"prometheus","pluginName":"Prometheus"}],"__requires":[{"type":"grafana","id":"grafana","name":"Grafana","version":"5.3.4"},{"type":"panel","id":"graph","name":"Graph","version":"5.0.0"},{"type":"datasource","id":"prometheus","name":"Prometheus","version":"5.0.0"},{"type":"panel","id":"singlestat","name":"Singlestat","version":"5.0.0"}],"annotations":{"list":[{"builtIn":1,"datasource":"-- Grafana --","enable":true,"hide":true,"iconColor":"rgba(0, 211, 255, 1)","name":"Annotations & Alerts","type":"dashboard"}]},"editable":true,"gnetId":null,"graphTooltip":0,"id":null,"links":[],"panels":[{"gridPos":{"h":1,"w":24,"x":0,"y":0},"id":40,"title":"Kubernetes 指标","type":"row"},{"aliasColors":{},"bars":false,"dashLength":10,"dashes":false,"datasource":"${DS_PROMETHEUS}","fill":1,"gridPos":{"h":7,"w":8,"x":0,"y":1},"id":38,"legend":{"alignAsTable":false,"avg":false,"current":false,"hideEmpty":false,"max":false,"min":false,"rightSide":false,"show":true,"total":false,"values":false},"lines":true,"linewidth":1,"links":[],"nullPointMode":"null","percentage":false,"pointradius":5,"points":false,"renderer":"flot","seriesOverrides":[],"spaceLength":10,"stack":false,"steppedLine":false,"targets":[{"expr":"sum(rate(apiserver_request_total[1m]))","format":"time_series","intervalFactor":1,"legendFormat":"一分钟平均","refId":"A"},{"expr":"sum(rate(apiserver_request_total[5m]))","format":"time_series","intervalFactor":1,"legendFormat":"五分钟平均","refId":"B"}],"thresholds":[],"timeFrom":null,"timeShift":null,"title":"ApiServer 每分钟请求数","tooltip":{"shared":true,"sort":0,"value_type":"individual"},"type":"graph","xaxis":{"buckets":null,"mode":"time","name":null,"show":true,"values":[]},"yaxes":[{"format":"short","label":null,"logBase":1,"max":null,"min":null,"show":true},{"format":"short","label":null,"logBase":1,"max":null,"min":null,"show":true}],"yaxis":{"align":false,"alignLevel":null}},{"cacheTimeout":null,"colorBackground":false,"colorValue":false,"colors":["#299c46","rgba(237, 129, 40, 0.89)","#d44a3a"],"datasource":"${DS_PROMETHEUS}","format":"none","gauge":{"maxValue":100,"minValue":0,"show":false,"thresholdLabels":false,"thresholdMarkers":true},"gridPos":{"h":7,"w":4,"x":8,"y":1},"id":32,"interval":null,"links":[],"mappingType":1,"mappingTypes":[{"name":"value to text","value":1},{"name":"range to text","value":2}],"maxDataPoints":100,"nullPointMode":"connected","nullText":null,"postfix":"","postfixFontSize":"50%","prefix":"","prefixFontSize":"50%","rangeMaps":[{"from":"null","text":"N/A","to":"null"}],"sparkline":{"fillColor":"rgba(31, 118, 189, 0.18)","full":false,"lineColor":"rgb(31, 120, 193)","show":false},"tableColumn":"","targets":[{"expr":"kubelet_active_pods{beta_kubernetes_io_arch=\\"amd64\\",beta_kubernetes_io_os=\\"linux\\",instance=\\"k8s-master01\\",job=\\"kubernetes-kubelet\\",kubernetes_io_arch=\\"amd64\\",kubernetes_io_hostname=\\"k8s-master01\\",kubernetes_io_os=\\"linux\\",static=\\"\\"}","format":"time_series","intervalFactor":1,"legendFormat":"","refId":"A"}],"thresholds":"","title":"Master01 节点 Pod 总量","type":"singlestat","valueFontSize":"80%","valueMaps":[{"op":"=","text":"N/A","value":"null"}],"valueName":"avg"},{"cacheTimeout":null,"colorBackground":false,"colorValue":false,"colors":["#299c46","rgba(237, 129, 40, 0.89)","#d44a3a"],"datasource":"${DS_PROMETHEUS}","format":"none","gauge":{"maxValue":100,"minValue":0,"show":false,"thresholdLabels":false,"thresholdMarkers":true},"gridPos":{"h":7,"w":4,"x":12,"y":1},"id":34,"interval":null,"links":[],"mappingType":1,"mappingTypes":[{"name":"value to text","value":1},{"name":"range to text","value":2}],"maxDataPoints":100,"nullPointMode":"connected","nullText":null,"postfix":"","postfixFontSize":"50%","prefix":"","prefixFontSize":"50%","rangeMaps":[{"from":"null","text":"N/A","to":"null"}],"sparkline":{"fillColor":"rgba(31, 118, 189, 0.18)","full":false,"lineColor":"rgb(31, 120, 193)","show":false},"tableColumn":"","targets":[{"expr":"kubelet_active_pods{kubernetes_io_hostname=\\"k8s-node01\\",static=\\"\\"}","format":"time_series","intervalFactor":1,"refId":"A"}],"thresholds":"","title":"Node01 节点 Pod 总量","type":"singlestat","valueFontSize":"80%","valueMaps":[{"op":"=","text":"N/A","value":"null"}],"valueName":"avg"},{"cacheTimeout":null,"colorBackground":false,"colorValue":false,"colors":["#299c46","rgba(237, 129, 40, 0.89)","#d44a3a"],"datasource":"${DS_PROMETHEUS}","format":"none","gauge":{"maxValue":100,"minValue":0,"show":false,"thresholdLabels":false,"thresholdMarkers":true},"gridPos":{"h":7,"w":4,"x":16,"y":1},"id":36,"interval":null,"links":[],"mappingType":1,"mappingTypes":[{"name":"value to text","value":1},{"name":"range to text","value":2}],"maxDataPoints":100,"nullPointMode":"connected","nullText":null,"postfix":"","postfixFontSize":"50%","prefix":"","prefixFontSize":"50%","rangeMaps":[{"from":"null","text":"N/A","to":"null"}],"sparkline":{"fillColor":"rgba(31, 118, 189, 0.18)","full":false,"lineColor":"rgb(31, 120, 193)","show":false},"tableColumn":"","targets":[{"expr":"kubelet_active_pods{kubernetes_io_hostname=\\"k8s-node02\\",static=\\"\\"}","format":"time_series","intervalFactor":1,"refId":"A"}],"thresholds":"","title":"Node02 节点 Pod 总量","type":"singlestat","valueFontSize":"80%","valueMaps":[{"op":"=","text":"N/A","value":"null"}],"valueName":"avg"},{"collapsed":false,"gridPos":{"h":1,"w":24,"x":0,"y":8},"id":24,"panels":[],"title":"Kubernetes 物理机","type":"row"},{"aliasColors":{},"bars":true,"dashLength":10,"dashes":false,"datasource":"${DS_PROMETHEUS}","decimals":null,"fill":4,"gridPos":{"h":6,"w":8,"x":0,"y":9},"id":10,"legend":{"alignAsTable":false,"avg":false,"current":false,"hideEmpty":false,"max":false,"min":false,"rightSide":false,"show":true,"total":false,"values":false},"lines":false,"linewidth":1,"links":[],"nullPointMode":"null","percentage":false,"pointradius":5,"points":false,"renderer":"flot","seriesOverrides":[],"spaceLength":10,"stack":false,"steppedLine":false,"targets":[{"expr":"100 * (1 - avg by (instance) (rate(node_cpu_seconds_total{mode=\\"idle\\", instance=\\"k8s-master01\\"}[1m])))","format":"time_series","hide":false,"intervalFactor":1,"legendFormat":"Master01","refId":"A"},{"expr":"100 * (1 - avg by (instance) (rate(node_cpu_seconds_total{mode=\\"idle\\", instance=\\"k8s-node01\\"}[1m])))","format":"time_series","hide":false,"intervalFactor":1,"legendFormat":"Node01","refId":"B"},{"expr":"100 * (1 - avg by (instance) (rate(node_cpu_seconds_total{mode=\\"idle\\", instance=\\"k8s-node02\\"}[1m])))","format":"time_series","hide":false,"intervalFactor":1,"legendFormat":"Node02","refId":"C"}],"thresholds":[],"timeFrom":null,"timeShift":null,"title":"CPU 使用量(百分比)","tooltip":{"shared":false,"sort":0,"value_type":"individual"},"type":"graph","xaxis":{"buckets":null,"mode":"series","name":null,"show":true,"values":["current"]},"yaxes":[{"format":"none","label":null,"logBase":1,"max":null,"min":null,"show":true},{"format":"short","label":null,"logBase":1,"max":null,"min":null,"show":true}],"yaxis":{"align":false,"alignLevel":null}},{"aliasColors":{},"bars":true,"dashLength":10,"dashes":false,"datasource":"${DS_PROMETHEUS}","fill":3,"gridPos":{"h":6,"w":8,"x":8,"y":9},"id":2,"legend":{"alignAsTable":false,"avg":false,"current":false,"hideEmpty":false,"max":false,"min":false,"rightSide":false,"show":false,"total":false,"values":false},"lines":false,"linewidth":3,"links":[],"nullPointMode":"null","percentage":false,"pointradius":5,"points":false,"renderer":"flot","seriesOverrides":[],"spaceLength":10,"stack":false,"steppedLine":false,"targets":[{"expr":"(node_memory_MemTotal_bytes{instance=\\"k8s-master01\\"} - (node_memory_MemFree_bytes{instance=\\"k8s-master01\\"} + node_memory_Buffers_bytes{instance=\\"k8s-master01\\"} + node_memory_Cached_bytes{instance=\\"k8s-master01\\"})) / node_memory_MemTotal_bytes{instance=\\"k8s-master01\\"} * 100","format":"time_series","intervalFactor":1,"legendFormat":"Master01 节点","refId":"A"},{"expr":"(node_memory_MemTotal_bytes{instance=\\"k8s-node01\\"} - (node_memory_MemFree_bytes{instance=\\"k8s-node01\\"} + node_memory_Buffers_bytes{instance=\\"k8s-node01\\"} + node_memory_Cached_bytes{instance=\\"k8s-node01\\"})) / node_memory_MemTotal_bytes{instance=\\"k8s-node01\\"} * 100","format":"time_series","intervalFactor":1,"legendFormat":"Node01 节点","refId":"B"},{"expr":"(node_memory_MemTotal_bytes{instance=\\"k8s-node02\\"} - (node_memory_MemFree_bytes{instance=\\"k8s-node02\\"} + node_memory_Buffers_bytes{instance=\\"k8s-node02\\"} + node_memory_Cached_bytes{instance=\\"k8s-node02\\"})) / node_memory_MemTotal_bytes{instance=\\"k8s-node02\\"} * 100","format":"time_series","hide":false,"intervalFactor":1,"legendFormat":"Node02 节点","refId":"C"}],"thresholds":[],"timeFrom":null,"timeShift":null,"title":"内存使用量(百分比)","tooltip":{"shared":false,"sort":0,"value_type":"individual"},"type":"graph","xaxis":{"buckets":null,"mode":"series","name":null,"show":true,"values":["current"]},"yaxes":[{"format":"none","label":null,"logBase":1,"max":null,"min":null,"show":true},{"decimals":null,"format":"none","label":null,"logBase":1,"max":null,"min":null,"show":true}],"yaxis":{"align":false,"alignLevel":null}},{"aliasColors":{},"bars":true,"dashLength":10,"dashes":false,"datasource":"${DS_PROMETHEUS}","fill":1,"gridPos":{"h":6,"w":8,"x":16,"y":9},"id":18,"legend":{"avg":false,"current":false,"max":false,"min":false,"show":false,"total":false,"values":false},"lines":false,"linewidth":1,"links":[],"nullPointMode":"null","percentage":false,"pointradius":5,"points":false,"renderer":"flot","seriesOverrides":[],"spaceLength":10,"stack":false,"steppedLine":false,"targets":[{"expr":"node_filesystem_avail_bytes{device=\\"/dev/mapper/rl-root\\",mountpoint=\\"/rootfs\\",instance=\\"k8s-master01\\"}","format":"time_series","intervalFactor":1,"legendFormat":"Master01","refId":"A"},{"expr":"node_filesystem_avail_bytes{device=\\"/dev/mapper/rl-root\\",mountpoint=\\"/rootfs\\",instance=\\"k8s-node01\\"}","format":"time_series","intervalFactor":1,"legendFormat":"Node01","refId":"B"},{"expr":"node_filesystem_avail_bytes{device=\\"/dev/mapper/rl-root\\",mountpoint=\\"/rootfs\\",instance=\\"k8s-node02\\"}","format":"time_series","intervalFactor":1,"legendFormat":"Node02","refId":"C"}],"thresholds":[],"timeFrom":null,"timeShift":null,"title":"存储空间剩余量","tooltip":{"shared":false,"sort":0,"value_type":"individual"},"type":"graph","xaxis":{"buckets":null,"mode":"series","name":null,"show":true,"values":["current"]},"yaxes":[{"format":"bytes","label":null,"logBase":1,"max":null,"min":null,"show":true},{"format":"short","label":null,"logBase":1,"max":null,"min":null,"show":true}],"yaxis":{"align":false,"alignLevel":null}},{"aliasColors":{},"bars":false,"dashLength":10,"dashes":false,"datasource":"${DS_PROMETHEUS}","fill":1,"gridPos":{"h":6,"w":24,"x":0,"y":15},"id":12,"legend":{"avg":false,"current":false,"max":false,"min":false,"show":true,"total":false,"values":false},"lines":true,"linewidth":1,"links":[],"nullPointMode":"null","percentage":false,"pointradius":5,"points":false,"renderer":"flot","seriesOverrides":[],"spaceLength":10,"stack":true,"steppedLine":false,"targets":[{"expr":"sum(rate(node_network_receive_bytes_total{instance=\\"k8s-master01\\"}[1m]))","format":"time_series","intervalFactor":1,"legendFormat":"Master01 下行","refId":"A"},{"expr":"sum(rate(node_network_transmit_bytes_total{instance=\\"k8s-master01\\"}[1m]))","format":"time_series","intervalFactor":1,"legendFormat":"Master01 上行","refId":"B"},{"expr":"sum(rate(node_network_receive_bytes_total{instance=\\"k8s-node01\\"}[1m]))","format":"time_series","intervalFactor":1,"legendFormat":"Node01 下行","refId":"C"},{"expr":"sum(rate(node_network_transmit_bytes_total{instance=\\"k8s-node01\\"}[1m]))","format":"time_series","intervalFactor":1,"legendFormat":"Node01 上行","refId":"D"},{"expr":"sum(rate(node_network_receive_bytes_total{instance=\\"k8s-node02\\"}[1m]))","format":"time_series","intervalFactor":1,"legendFormat":"Node02 下行","refId":"E"},{"expr":"sum(rate(node_network_transmit_bytes_total{instance=\\"k8s-node02\\"}[1m]))","format":"time_series","intervalFactor":1,"legendFormat":"Node02 上行","refId":"F"}],"thresholds":[],"timeFrom":null,"timeShift":null,"title":"网络 IO","tooltip":{"shared":true,"sort":0,"value_type":"individual"},"type":"graph","xaxis":{"buckets":null,"mode":"time","name":null,"show":true,"values":[]},"yaxes":[{"format":"short","label":null,"logBase":1,"max":null,"min":null,"show":true},{"format":"short","label":null,"logBase":1,"max":null,"min":null,"show":true}],"yaxis":{"align":false,"alignLevel":null}},{"collapsed":false,"gridPos":{"h":1,"w":24,"x":0,"y":21},"id":16,"panels":[],"repeat":null,"title":"Pod","type":"row"},{"aliasColors":{},"bars":false,"dashLength":10,"dashes":false,"datasource":"${DS_PROMETHEUS}","fill":1,"gridPos":{"h":7,"w":8,"x":0,"y":22},"id":20,"legend":{"avg":false,"current":false,"max":false,"min":false,"show":true,"total":false,"values":false},"lines":true,"linewidth":1,"links":[],"nullPointMode":"null","percentage":false,"pointradius":5,"points":false,"renderer":"flot","seriesOverrides":[],"spaceLength":10,"stack":false,"steppedLine":false,"targets":[{"expr":"100 * (sum(rate(container_cpu_usage_seconds_total{namespace=\\"kube-system\\", pod=\\"kube-apiserver-k8s-master01\\"}[1m])) by (namespace, pod))","format":"time_series","interval":"","intervalFactor":1,"legendFormat":"apiServer","refId":"A"},{"expr":"","format":"time_series","intervalFactor":1,"refId":"B"}],"thresholds":[],"timeFrom":null,"timeShift":null,"title":"Pod CPU 使用量","tooltip":{"shared":true,"sort":0,"value_type":"individual"},"type":"graph","xaxis":{"buckets":null,"mode":"time","name":null,"show":true,"values":[]},"yaxes":[{"format":"none","label":null,"logBase":1,"max":null,"min":null,"show":true},{"format":"short","label":null,"logBase":1,"max":null,"min":null,"show":true}],"yaxis":{"align":false,"alignLevel":null}},{"aliasColors":{},"bars":false,"dashLength":10,"dashes":false,"datasource":"${DS_PROMETHEUS}","fill":1,"gridPos":{"h":7,"w":8,"x":8,"y":22},"id":22,"legend":{"avg":false,"current":false,"max":false,"min":false,"show":true,"total":false,"values":false},"lines":true,"linewidth":1,"links":[],"nullPointMode":"null","percentage":false,"pointradius":5,"points":false,"renderer":"flot","seriesOverrides":[],"spaceLength":10,"stack":false,"steppedLine":false,"targets":[{"expr":"sum(container_memory_usage_bytes{namespace=\\"kube-system\\", pod=\\"kube-apiserver-k8s-master01\\"}) by (namespace, pod)","format":"time_series","intervalFactor":1,"legendFormat":"apiServer","refId":"A"}],"thresholds":[],"timeFrom":null,"timeShift":null,"title":"Pod 内存使用量","tooltip":{"shared":true,"sort":0,"value_type":"individual"},"type":"graph","xaxis":{"buckets":null,"mode":"time","name":null,"show":true,"values":[]},"yaxes":[{"format":"bytes","label":null,"logBase":1,"max":null,"min":null,"show":true},{"format":"short","label":null,"logBase":1,"max":null,"min":null,"show":true}],"yaxis":{"align":false,"alignLevel":null}},{"collapsed":false,"gridPos":{"h":1,"w":24,"x":0,"y":29},"id":8,"panels":[],"title":"Ingress-Nginx","type":"row"},{"cacheTimeout":null,"colorBackground":false,"colorValue":false,"colors":["#299c46","rgba(237, 129, 40, 0.89)","#d44a3a"],"datasource":"${DS_PROMETHEUS}","format":"none","gauge":{"maxValue":100,"minValue":0,"show":false,"thresholdLabels":false,"thresholdMarkers":true},"gridPos":{"h":2,"w":4,"x":0,"y":30},"id":28,"interval":null,"links":[],"mappingType":1,"mappingTypes":[{"name":"value to text","value":1},{"name":"range to text","value":2}],"maxDataPoints":100,"nullPointMode":"connected","nullText":null,"postfix":"","postfixFontSize":"50%","prefix":"","prefixFontSize":"50%","rangeMaps":[{"from":"null","text":"N/A","to":"null"}],"sparkline":{"fillColor":"rgba(31, 118, 189, 0.18)","full":false,"lineColor":"rgb(31, 120, 193)","show":false},"tableColumn":"","targets":[{"expr":"nginx_ingress_controller_success{job=\\"ingressnginx12\\"}","format":"time_series","intervalFactor":1,"legendFormat":"node01","refId":"A"},{"expr":"","format":"time_series","intervalFactor":1,"refId":"B"}],"thresholds":"","title":"node01 节点 Nginx-ingress 重载次数","type":"singlestat","valueFontSize":"80%","valueMaps":[{"op":"=","text":"N/A","value":"null"}],"valueName":"avg"},{"cacheTimeout":null,"colorBackground":false,"colorValue":false,"colors":["#299c46","rgba(237, 129, 40, 0.89)","#d44a3a"],"datasource":"${DS_PROMETHEUS}","format":"none","gauge":{"maxValue":100,"minValue":0,"show":false,"thresholdLabels":false,"thresholdMarkers":true},"gridPos":{"h":2,"w":4,"x":4,"y":30},"id":30,"interval":null,"links":[],"mappingType":1,"mappingTypes":[{"name":"value to text","value":1},{"name":"range to text","value":2}],"maxDataPoints":100,"nullPointMode":"connected","nullText":null,"postfix":"","postfixFontSize":"50%","prefix":"","prefixFontSize":"50%","rangeMaps":[{"from":"null","text":"N/A","to":"null"}],"sparkline":{"fillColor":"rgba(31, 118, 189, 0.18)","full":false,"lineColor":"rgb(31, 120, 193)","show":false},"tableColumn":"","targets":[{"expr":"nginx_ingress_controller_success{job=\\"ingressnginx13\\"}","format":"time_series","intervalFactor":1,"refId":"A"}],"thresholds":"","title":"node02 节点 Nginx-ingress 重载次数","type":"singlestat","valueFontSize":"80%","valueMaps":[{"op":"=","text":"N/A","value":"null"}],"valueName":"avg"},{"aliasColors":{},"bars":false,"dashLength":10,"dashes":false,"datasource":"${DS_PROMETHEUS}","fill":1,"gridPos":{"h":5,"w":8,"x":0,"y":32},"id":4,"legend":{"avg":false,"current":false,"max":false,"min":false,"show":true,"total":false,"values":false},"lines":true,"linewidth":1,"links":[],"nullPointMode":"null","percentage":false,"pointradius":5,"points":false,"renderer":"flot","seriesOverrides":[],"spaceLength":10,"stack":false,"steppedLine":false,"targets":[{"expr":"nginx_ingress_controller_nginx_process_requests_total{controller_class=\\"k8s.io/ingress-nginx\\",controller_namespace=\\"ingress\\",controller_pod=\\"ingress-nginx-controller-c5h6j\\",instance=\\"192.168.10.12:10254\\",job=\\"ingressnginx12\\"}","format":"time_series","intervalFactor":1,"legendFormat":"node01","refId":"A"},{"expr":"nginx_ingress_controller_nginx_process_requests_total{controller_class=\\"k8s.io/ingress-nginx\\",controller_namespace=\\"ingress\\",controller_pod=\\"ingress-nginx-controller-c5h6j\\",instance=\\"192.168.10.12:10254\\",job=\\"ingressnginx12\\"}","format":"time_series","intervalFactor":1,"legendFormat":"node02","refId":"B"}],"thresholds":[],"timeFrom":null,"timeShift":null,"title":"Ingress-Nginx 请求量","tooltip":{"shared":true,"sort":0,"value_type":"individual"},"type":"graph","xaxis":{"buckets":null,"mode":"time","name":null,"show":true,"values":[]},"yaxes":[{"format":"short","label":null,"logBase":1,"max":null,"min":null,"show":true},{"format":"short","label":null,"logBase":1,"max":null,"min":null,"show":true}],"yaxis":{"align":false,"alignLevel":null}},{"collapsed":false,"gridPos":{"h":1,"w":24,"x":0,"y":37},"id":6,"panels":[],"title":"NFS-StorageClass","type":"row"},{"aliasColors":{},"bars":false,"dashLength":10,"dashes":false,"datasource":"${DS_PROMETHEUS}","fill":1,"gridPos":{"h":6,"w":24,"x":0,"y":38},"id":14,"legend":{"avg":false,"current":false,"max":false,"min":false,"show":true,"total":false,"values":false},"lines":true,"linewidth":1,"links":[],"nullPointMode":"null","percentage":false,"pointradius":5,"points":false,"renderer":"flot","seriesOverrides":[],"spaceLength":10,"stack":false,"steppedLine":false,"targets":[{"expr":"node_nfsd_disk_bytes_read_total{beta_kubernetes_io_arch=\\"amd64\\",beta_kubernetes_io_os=\\"linux\\",instance=\\"k8s-master01\\",job=\\"kubernetes-nodes\\",kubernetes_io_arch=\\"amd64\\",kubernetes_io_hostname=\\"k8s-master01\\",kubernetes_io_os=\\"linux\\"}","format":"time_series","intervalFactor":1,"legendFormat":"读取总量","refId":"A"},{"expr":"node_nfsd_disk_bytes_written_total{beta_kubernetes_io_arch=\\"amd64\\",beta_kubernetes_io_os=\\"linux\\",instance=\\"k8s-master01\\",job=\\"kubernetes-nodes\\",kubernetes_io_arch=\\"amd64\\",kubernetes_io_hostname=\\"k8s-master01\\",kubernetes_io_os=\\"linux\\"}","format":"time_series","intervalFactor":1,"legendFormat":"写入总量","refId":"B"}],"thresholds":[],"timeFrom":null,"timeShift":null,"title":"NFS storageClass 读取文件总量","tooltip":{"shared":true,"sort":0,"value_type":"individual"},"type":"graph","xaxis":{"buckets":null,"mode":"time","name":null,"show":true,"values":[]},"yaxes":[{"format":"decbytes","label":null,"logBase":1,"max":null,"min":null,"show":true},{"format":"short","label":null,"logBase":1,"max":null,"min":null,"show":true}],"yaxis":{"align":false,"alignLevel":null}}],"refresh":false,"schemaVersion":16,"style":"dark","tags":[],"templating":{"list":[]},"time":{"from":"now-6h","to":"now"},"timepicker":{"refresh_intervals":["5s","10s","30s","1m","5m","15m","30m","1h","2h","1d"],"time_options":["5m","15m","1h","6h","12h","24h","2d","7d","30d"]},"timezone":"","title":"Kubernetes 监控","uid":"Lwdu47xIk","version":33}
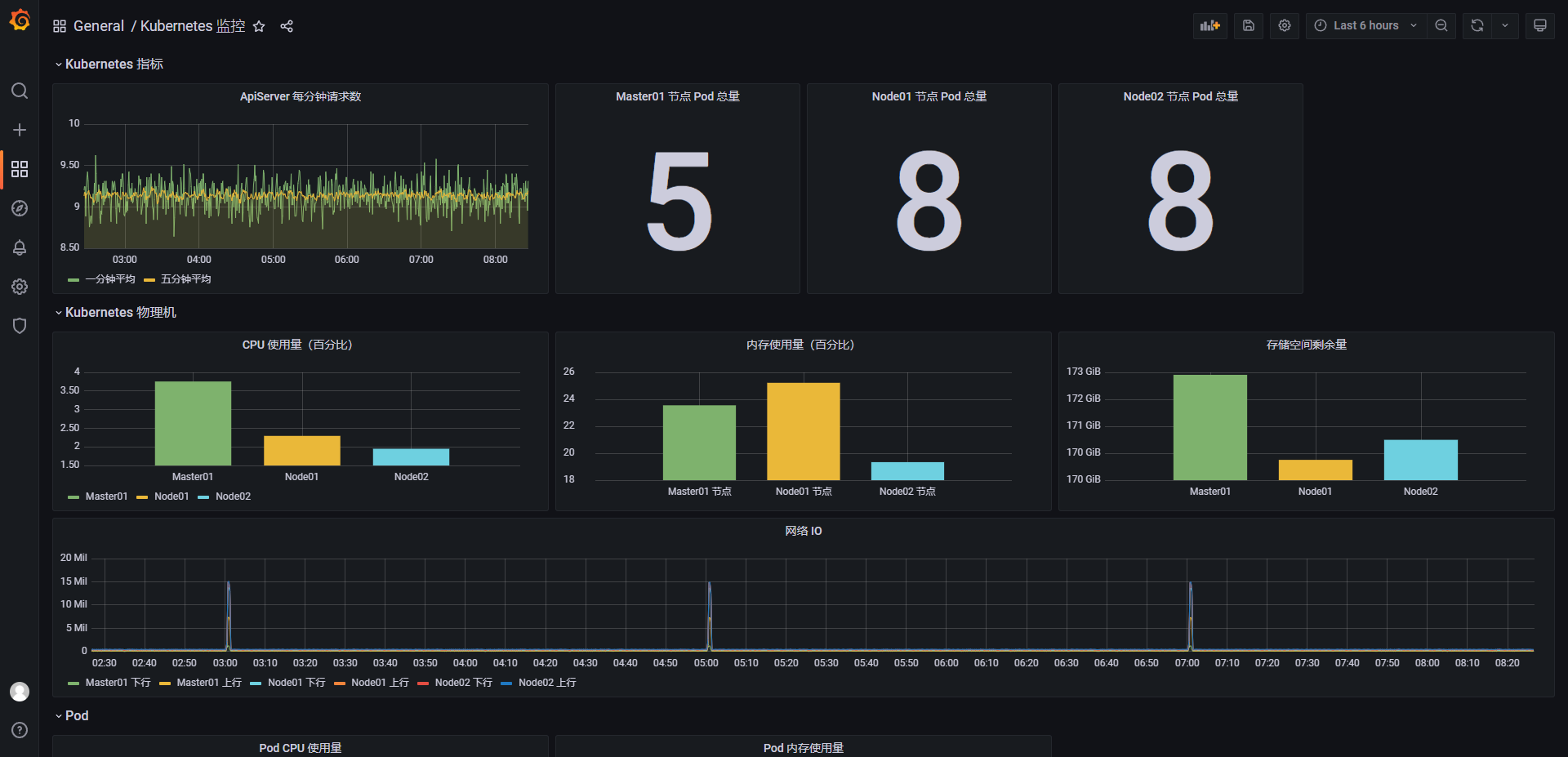
十一、监控 metrics.server
从 Kubernetes v1.8 开始,资源使用情况的监控可以通过 Metrics API 的形式获取,例如容器 CPU 和内存使用率。这些度量可以由用户直接访问(例如,通过使用 kubectl top 命令),或者由集群中的控制器(例如,Horizontal Pod Autoscaler)使用来进行决策,具体的组件为 Metrics Server,用来替换之前的 heapster,heapster 从 1.11 开始逐渐被废弃。
Metrics-Server 是集群核心监控数据的聚合器。通俗地说,它存储了集群中各节点的监控数据,并且提供了 API 以供分析和使用。Metrics-Server 作为一个 Deployment 对象默认部署在 Kubernetes 集群中。不过准确地说,它是 Deployment,Service,ClusterRole,ClusterRoleBinding,APIService,RoleBinding 等资源对象的综合体。
# https://github.com/kubernetes-sigs/metrics-server
https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.7.0/components.yaml当前 K8S 版本 1.29.0 ,使用 Metrics Server 版本 0.7.0.
下载后的资源清单稍作修改,跳过 Kubelet TLS 验证
components.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
rbac.authorization.k8s.io/aggregate-to-admin: "true"
rbac.authorization.k8s.io/aggregate-to-edit: "true"
rbac.authorization.k8s.io/aggregate-to-view: "true"
name: system:aggregated-metrics-reader
rules:
- apiGroups:
- metrics.k8s.io
resources:
- pods
- nodes
verbs:
- get
- list
- watch
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
rules:
- apiGroups:
- ""
resources:
- nodes/metrics
verbs:
- get
- apiGroups:
- ""
resources:
- pods
- nodes
verbs:
- get
- list
- watch
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server-auth-reader
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: extension-apiserver-authentication-reader
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server:system:auth-delegator
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:auth-delegator
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:metrics-server
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
ports:
- name: https
port: 443
protocol: TCP
targetPort: https
selector:
k8s-app: metrics-server
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
selector:
matchLabels:
k8s-app: metrics-server
strategy:
rollingUpdate:
maxUnavailable: 0
template:
metadata:
labels:
k8s-app: metrics-server
spec:
containers:
- args:
- --cert-dir=/tmp
- --secure-port=10250
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --kubelet-insecure-tls # 跳过 Kubelet TLS 验证
- --metric-resolution=15s
image: registry.k8s.io/metrics-server/metrics-server:v0.7.0
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 3
httpGet:
path: /livez
port: https
scheme: HTTPS
periodSeconds: 10
name: metrics-server
ports:
- containerPort: 10250
name: https
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /readyz
port: https
scheme: HTTPS
initialDelaySeconds: 20
periodSeconds: 10
resources:
requests:
cpu: 100m
memory: 200Mi
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop:
- ALL
readOnlyRootFilesystem: true
runAsNonRoot: true
runAsUser: 1000
seccompProfile:
type: RuntimeDefault
volumeMounts:
- mountPath: /tmp
name: tmp-dir
nodeSelector:
kubernetes.io/os: linux
priorityClassName: system-cluster-critical
serviceAccountName: metrics-server
volumes:
- emptyDir: {}
name: tmp-dir
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
labels:
k8s-app: metrics-server
name: v1beta1.metrics.k8s.io
spec:
group: metrics.k8s.io
groupPriorityMinimum: 100
insecureSkipTLSVerify: true
service:
name: metrics-server
namespace: kube-system
version: v1beta1
versionPriority: 100执行资源清单
# 执行资源清单,部署 metrics-server
$ kubectl apply -f components.yaml
# 查看 Pod
$ kubectl get pod -n kube-system -o wide -w | grep metrics-server
metrics-server-56cfc8b678-b77wb 1/1 Running 0 59s 192.168.85.217 k8s-node01 <none> <none>
十二、alertmanager 部署
1. 创建 alertmanager 配置文件
资源清单:alertmanager-conf.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: alert-config
namespace: kube-ops
data:
config.yml: |-
global:
# 定义告警在没有新触发的情况下被标记为已解决(resolved)的时间,设置为 5 分钟。
resolve_timeout: 5m
# 配置邮件发送信息
smtp_smarthost: 'smtp.163.com:25' # 指定 SMTP 服务器地址和端口,用于发送邮件通知
smtp_from: '18326088610@163.com' # 邮件发送者的地址,显示为发件人(From 字段)
smtp_auth_username: '18326088610@163.com' # SMTP 认证用户名,与发件人地址一致
smtp_auth_password: 'xxxxxxxxxxxxxxxx' # SMTP 认证密码,通常是 163 邮箱的授权码(非登录密码)
smtp_hello: '163.com' # SMTP 客户端在与服务器建立连接时发送的 HELO/EHLO 域名,设置为 163.com
smtp_require_tls: false # 禁用 TLS 加密,邮件通过明文传输(端口 25 通常不加密)
route: # 定义告警的路由策略,决定如何分组、处理和分发告警
# 这里的标签列表是接收到报警信息后的重新分组标签,例如,接收到的报警信息里面有许多具有 cluster=A 和 alertname=LatncyHigh 这样的标签的报警信息将会批量被聚合到一个分组里面
group_by: ['alertname', 'cluster']
# 当一个新的报警分组被创建后,需要等待至少group_wait时间来初始化通知,这种方式可以确保您能有足够的时间为同一分组来获取多个警报,然后一起触发这个报警信息。
group_wait: 30s
# 当第一个报警发送后,等待'group_interval'时间来发送新的一组报警信息。
group_interval: 5m
# 如果一个报警信息已经发送成功了,等待'repeat_interval'时间来重新发送他们
repeat_interval: 5m
# 默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器
receiver: default
# 上面所有的属性都由所有子路由继承,并且可以在每个子路由上进行覆盖。
routes:
- receiver: email # 匹配子路由的告警发送到 email 接收器
group_wait: 10s # 子路由覆盖父路由的 group_wait,仅等待 10 秒发送通知
match:
team: node # 仅匹配带有标签 team=node 的告警(如 Prometheus 规则中定义的 HighNodeCPU 告警)
receivers: # 定义告警通知的接收器,指定通知方式和目标
- name: 'default'
email_configs:
- to: 'george_95@126.com' # 告警邮件发送到 george_95@126.com
send_resolved: true # 当告警解决时,发送“已恢复”通知邮件
- name: 'email' # 自定义接收器,处理匹配 team: node 的告警
email_configs:
- to: 'george_95@126.com' # 告警邮件发送到 george_95@126.com
send_resolved: true # 当告警解决时,发送“已恢复”通知邮件执行资源清单
$ kubectl apply -f alertmanager-conf.yaml2. 修改 Prometheus ConfigMap
prometheus-cm.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: kube-ops
data:
rules.yml: | # 配置Prometheus告警规则,内存使用超过 20% 就告警
groups:
- name: test-rule
rules:
- alert: NodeMemoryUsage
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 20
for: 2m # 告警条件需持续满足 2 分钟(2m)才会触发
labels: # 为告警添加标签 team=node,用于路由和分组
team: node
annotations: # 提供告警的附加信息,显示在通知(如邮件)中
summary: "{{$labels.instance}}: High Memory usage detected"
description: "{{$labels.instance}}: Memory usage is above 20% (current value is: {{ $value }}"
prometheus.yml: | # 使用 | 表示 YAML 中的多行文本
global: # 定义 Prometheus 的全局配置,适用于所有抓取任务(除非在具体任务中被覆盖)
scrape_interval: 15s # 表示 prometheus 抓取指标数据的频率,默认是 15s
scrape_timeout: 15s # 表示 prometheus 抓取指标数据的超时时间,默认是 15s
scrape_configs:
- job_name: 'prometheus' # 定义任务名,这里监控 prometheus 自身
static_configs:
- targets: ['localhost:9090']
- job_name: 'ingressnginx140' # 10.20.1.140 Ingress-nginx 指标数据抓取
static_configs:
- targets: ['10.20.1.140:10254']
- job_name: 'ingressnginx141' # 10.20.1.141 Ingress-nginx 指标数据抓取
static_configs:
- targets: ['10.20.1.141:10254']
- job_name: 'ingressnginx142' # 10.20.1.142 Ingress-nginx 指标数据抓取
static_configs:
- targets: ['10.20.1.142:10254']
- job_name: 'kubernetes-nodes' # 基于Node自动发现节点,并抓取指标信息。Node Exporter:提供系统级指标,适合监控节点的硬件和操作系统状态(如磁盘 I/O、网络流量)。
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__] # 默认抓取节点的 Kubelet 端点(端口 10250,/metrics),但这里通过 relabel_configs 修改为 Node Exporter 的端口(9100)
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- action: labelmap # 将 Kubernetes 节点的标签(__meta_kubernetes_node_label_<key>)映射为 Prometheus 指标的标签
regex: __meta_kubernetes_node_label_(.+)
- job_name: 'kubernetes-kubelet' # 基于Node发现,从 Kubelet 抓取指标信息。Kubelet:提供 Kubernetes 特定指标,如 Pod 运行状态、Kubelet 的健康状况和 API 请求统计。
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt # k8s 自动为pod挂载的证书文件路径,在pod内部
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token # k8s 自动为pod挂载的token文件路径,在pod内部
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+) # 将 Kubernetes 节点的标签(__meta_kubernetes_node_label_<key>)映射为 Prometheus 指标的标签
- job_name: 'kubernetes-cadvisor' # 抓取任务名称为 kubernetes-cadvisor,用于监控 Kubernetes 节点的 cAdvisor 指标
kubernetes_sd_configs:
- role: node
scheme: https # 指定使用 HTTPS 协议访问目标(Kubernetes API 服务器的 443 端口)
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt # 使用 Pod 内部的服务账号卷挂载的 CA 证书
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token # 使用服务账号的 Bearer 令牌
relabel_configs: # 定义标签重写规则,修改服务发现的目标地址和路径
- action: labelmap # 规则1:将节点的标签(如 kubernetes.io/hostname)映射到 Prometheus 指标标签
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443 # 规则2:将抓取目标地址设置为 kubernetes.default.svc:443,即 Kubernetes API 服务器的 ClusterIP 服务(默认命名空间 default,端口 443)
- source_labels: [__meta_kubernetes_node_name] # 规则3:使用节点名称(__meta_kubernetes_node_name,如 node01)动态构造指标路径
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
- job_name: 'kubernetes-apiservers' # 抓取任务名称为 kubernetes-apiservers,用于监控 Kubernetes API 服务器的指标,包括请求速率、延迟、错误率等(如 apiserver_request_total, apiserver_request_duration_seconds)
kubernetes_sd_configs:
- role: endpoints # 使用 Kubernetes 服务发现,角色为 endpoints,发现集群中的所有 Endpoints 对象
scheme: https # Kubernetes API 服务器默认通过 HTTPS(端口 443)暴露 /metrics 端点
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt # 使用 Prometheus Pod 内部的服务账号卷挂载的 CA 证书(位于 /var/run/secrets/kubernetes.io/serviceaccount/ca.crt)验证 API 服务器的 TLS 证书
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token # 使用服务账号的 Bearer 令牌(位于 /var/run/secrets/kubernetes.io/serviceaccount/token)进行身份验证
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] # 断点所在的名称空间,断点所在的 Service, 断点端口名称
action: keep # 仅保留匹配正则表达式的端点,未匹配的端点被丢弃。
regex: default;kubernetes;https # 确保 Prometheus 只抓取 default 命名空间中 kubernetes 服务的 HTTPS 端点(即 API 服务器的 /metrics)
- job_name: 'kubernetes-service-endpoints' # 抓取任务名称为 kubernetes-service-endpoints,用于监控 Kubernetes Service 的 Endpoints 指标。
kubernetes_sd_configs:
- role: endpoints # 使用 Kubernetes 服务发现,角色为 endpoints,发现集群中所有 Service 的 Endpoints 对象
relabel_configs: # 定义标签重写规则,过滤和配置服务发现的目标,确保只抓取符合条件的 Service Endpoints
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep # 仅保留注解 prometheus.io/scrape: "true" 的 Service Endpoints,未匹配的被丢弃
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace # 将匹配的值替换到 __scheme__ 标签,决定抓取协议(http 或 https),允许 Service 指定是否通过 HTTPS 抓取指标,适用于需要安全连接的场景
target_label: __scheme__
regex: (https?) # 匹配 http 或 https,若注解未设置,默认使用 http
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace # 检查 Service 的注解 prometheus.io/path,将匹配的值替换到 __metrics_path__ 标签,指定指标端点的路径
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace # 将地址和端口组合替换到 __address__ 标签,允许 Service 指定抓取端口(如 prometheus.io/port: "8080"),覆盖 Endpoints 的默认端口
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap # 将 Service 的标签(如 app=my-app)映射到 Prometheus 指标标签
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace] # 将 Service 的命名空间(__meta_kubernetes_namespace)写入指标标签 kubernetes_namespace
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name] # 将 Service 名称(__meta_kubernetes_service_name)写入指标标签 kubernetes_name
action: replace
target_label: kubernetes_name
alerting: # 定义 Prometheus 与 Alertmanager 的连接,用于发送告警
alertmanagers: # 指定 Alertmanager 实例的地址
- static_configs:
- targets: ["prometheus.kube-ops.svc.cluster.local:9093"] # <service-name>.<namespace>.svc.<cluster-domain>,注意 这里Service名称是 prometheus执行资源清单
$ kubectl apply -f prometheus-cm.yaml3. 修改 Prometheus Service
资源清单:prometheus.yaml
# Service
apiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: kube-ops
labels:
app: prometheus
spec:
selector:
app: prometheus
type: NodePort
ports:
- name: prometheus # 端口名称
port: 9090 # service 对外端口 9090
targetPort: 9090 # 内部名为 http 的端口 (9090)
- name: alertmanager # altermanager 端口配置
port: 9093
targetPort: 90934. 合并 altermanager 至 prometheus deploy 文件
资源清单:prometheus.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus
namespace: kube-ops
labels:
app: prometheus
spec:
replicas: 1 # Pod 副本数为1
selector:
matchLabels:
app: prometheus
template:
metadata:
labels:
app: prometheus
spec:
serviceAccountName: prometheus # 指定 Pod 使用的 Kubernetes 服务账号(ServiceAccount)为 prometheus
containers:
- name: alertmanager
image: prom/alertmanager:v0.28.0
imagePullPolicy: IfNotPresent
args:
- "--config.file=/etc/alertmanager/config.yml"
- "--storage.path=/alertmanager/data"
ports:
- containerPort: 9093
name: alertmanager
volumeMounts:
- mountPath: "/etc/alertmanager"
name: alertcfg
resources:
requests:
cpu: 300m
memory: 512Mi
limits:
cpu: 300m
memory: 512Mi
- name: prometheus
image: prom/prometheus:v2.54.1
imagePullPolicy: IfNotPresent
command:
- "/bin/prometheus" # 指定容器启动时运行的命令为 /bin/prometheus,这是 Prometheus 的主可执行文件
args:
- "--config.file=/etc/prometheus/prometheus.yml" # 指定 Prometheus 的配置文件路径为 /etc/prometheus/prometheus.yml,这个文件由 ConfigMap(prometheus-config)提供,挂载到容器内
- "--storage.tsdb.path=/prometheus" # 指定 Prometheus 时间序列数据库(TSDB)的存储路径为 /prometheus,这个路径由 PVC(prometheus)提供,持久化存储数据
- "--storage.tsdb.retention=24h" # 设置数据保留时间为 24 小时,意味着 Prometheus 只保留最近 24 小时的监控数据,旧数据将被删除。生产环境建议 15-30天
- "--web.enable-admin-api" # 启用 Prometheus 的 Admin HTTP API,允许执行管理操作(如删除时间序列)
- "--web.enable-lifecycle" # 启用生命周期 API,支持通过 HTTP 请求(如 localhost:9090/-/reload)动态重新加载配置文件。
ports:
- containerPort: 9090 # 指定 Prometheus 监听端口,用于提供 Web UI 和 API
protocol: TCP
name: http
volumeMounts: # 定义容器内的挂载点,将卷挂载到指定路径
- mountPath: "/prometheus" # 将名为 data 的卷挂载到容器内的 /prometheus 路径,用于存储 TSDB 数据
subPath: prometheus # 表示使用卷中的子路径 prometheus,避免覆盖整个卷的其他内容
name: data # 卷由 PVC(prometheus)提供
- mountPath: "/etc/prometheus" # 将名为 config-volume 的卷挂载到容器内的 /etc/prometheus 路径,用于存储配置文件
name: config-volume # 由 ConfigMap(prometheus-config)提供
resources:
requests:
cpu: 500m # 请求 100 毫核(0.1 CPU 核心),表示容器需要的最小 CPU 资源
memory: 1024Mi # 请求 512 MiB 内存,表示容器需要的最小内存
limits:
cpu: 500m # 限制容器最多使用 100 毫核 CPU,防止过量占用
memory: 1024Mi # 限制容器最多使用 512 MiB 内存,防止内存溢出
securityContext: # 定义 Pod 的安全上下文,控制容器运行时的权限
runAsUser: 0 # 指定容器以用户 ID 0(即 root 用户)运行
volumes: # 定义 Pod 使用的卷,供容器挂载
- name: data
persistentVolumeClaim: # 指定挂载的PVC
claimName: prometheus
- name: config-volume
configMap: # 指定挂载的 configMap
name: prometheus-config
- name: alertcfg # 挂载AlertManager ConfigMap
configMap:
name: alert-config这里要注意 prometheus 和 alertmanager 不能太旧,否则无法适配当前的 SMTP 协议。
执行资源清单
# 执行资源清单,重新加载 Service 和 Deployment
$ kubectl apply -f prometheus.yaml5. 添加报警演示
修改 Prometheus ConfigMap,添加监控 内存使用量
资源清单:prometheus-cm.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: kube-ops
data:
rules.yml: | # 配置Prometheus告警规则,内存使用超过 20% 就告警
groups:
- name: test-rule
rules:
- alert: NodeMemoryUsage
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 20
for: 2m # 告警条件需持续满足 2 分钟(2m)才会触发
labels: # 为告警添加标签 team=node,用于路由和分组
team: node
annotations: # 提供告警的附加信息,显示在通知(如邮件)中
summary: "{{$labels.instance}}: High Memory usage detected"
description: "{{$labels.instance}}: Memory usage is above 20% (current value is: {{ $value }}"
prometheus.yml: | # 使用 | 表示 YAML 中的多行文本
global: # 定义 Prometheus 的全局配置,适用于所有抓取任务(除非在具体任务中被覆盖)
scrape_interval: 15s # 表示 prometheus 抓取指标数据的频率,默认是 15s
scrape_timeout: 15s # 表示 prometheus 抓取指标数据的超时时间,默认是 15s
scrape_configs:
- job_name: 'prometheus' # 定义任务名,这里监控 prometheus 自身
static_configs:
- targets: ['localhost:9090']
- job_name: 'ingressnginx140' # 10.20.1.140 Ingress-nginx 指标数据抓取
static_configs:
- targets: ['10.20.1.140:10254']
- job_name: 'ingressnginx141' # 10.20.1.141 Ingress-nginx 指标数据抓取
static_configs:
- targets: ['10.20.1.141:10254']
- job_name: 'ingressnginx142' # 10.20.1.142 Ingress-nginx 指标数据抓取
static_configs:
- targets: ['10.20.1.142:10254']
- job_name: 'kubernetes-nodes' # 基于Node自动发现节点,并抓取指标信息。Node Exporter:提供系统级指标,适合监控节点的硬件和操作系统状态(如磁盘 I/O、网络流量)。
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__] # 默认抓取节点的 Kubelet 端点(端口 10250,/metrics),但这里通过 relabel_configs 修改为 Node Exporter 的端口(9100)
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- action: labelmap # 将 Kubernetes 节点的标签(__meta_kubernetes_node_label_<key>)映射为 Prometheus 指标的标签
regex: __meta_kubernetes_node_label_(.+)
- job_name: 'kubernetes-kubelet' # 基于Node发现,从 Kubelet 抓取指标信息。Kubelet:提供 Kubernetes 特定指标,如 Pod 运行状态、Kubelet 的健康状况和 API 请求统计。
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt # k8s 自动为pod挂载的证书文件路径,在pod内部
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token # k8s 自动为pod挂载的token文件路径,在pod内部
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+) # 将 Kubernetes 节点的标签(__meta_kubernetes_node_label_<key>)映射为 Prometheus 指标的标签
- job_name: 'kubernetes-cadvisor' # 抓取任务名称为 kubernetes-cadvisor,用于监控 Kubernetes 节点的 cAdvisor 指标
kubernetes_sd_configs:
- role: node
scheme: https # 指定使用 HTTPS 协议访问目标(Kubernetes API 服务器的 443 端口)
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt # 使用 Pod 内部的服务账号卷挂载的 CA 证书
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token # 使用服务账号的 Bearer 令牌
relabel_configs: # 定义标签重写规则,修改服务发现的目标地址和路径
- action: labelmap # 规则1:将节点的标签(如 kubernetes.io/hostname)映射到 Prometheus 指标标签
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443 # 规则2:将抓取目标地址设置为 kubernetes.default.svc:443,即 Kubernetes API 服务器的 ClusterIP 服务(默认命名空间 default,端口 443)
- source_labels: [__meta_kubernetes_node_name] # 规则3:使用节点名称(__meta_kubernetes_node_name,如 node01)动态构造指标路径
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
- job_name: 'kubernetes-apiservers' # 抓取任务名称为 kubernetes-apiservers,用于监控 Kubernetes API 服务器的指标,包括请求速率、延迟、错误率等(如 apiserver_request_total, apiserver_request_duration_seconds)
kubernetes_sd_configs:
- role: endpoints # 使用 Kubernetes 服务发现,角色为 endpoints,发现集群中的所有 Endpoints 对象
scheme: https # Kubernetes API 服务器默认通过 HTTPS(端口 443)暴露 /metrics 端点
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt # 使用 Prometheus Pod 内部的服务账号卷挂载的 CA 证书(位于 /var/run/secrets/kubernetes.io/serviceaccount/ca.crt)验证 API 服务器的 TLS 证书
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token # 使用服务账号的 Bearer 令牌(位于 /var/run/secrets/kubernetes.io/serviceaccount/token)进行身份验证
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] # 断点所在的名称空间,断点所在的 Service, 断点端口名称
action: keep # 仅保留匹配正则表达式的端点,未匹配的端点被丢弃。
regex: default;kubernetes;https # 确保 Prometheus 只抓取 default 命名空间中 kubernetes 服务的 HTTPS 端点(即 API 服务器的 /metrics)
- job_name: 'kubernetes-service-endpoints' # 抓取任务名称为 kubernetes-service-endpoints,用于监控 Kubernetes Service 的 Endpoints 指标。
kubernetes_sd_configs:
- role: endpoints # 使用 Kubernetes 服务发现,角色为 endpoints,发现集群中所有 Service 的 Endpoints 对象
relabel_configs: # 定义标签重写规则,过滤和配置服务发现的目标,确保只抓取符合条件的 Service Endpoints
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep # 仅保留注解 prometheus.io/scrape: "true" 的 Service Endpoints,未匹配的被丢弃
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace # 将匹配的值替换到 __scheme__ 标签,决定抓取协议(http 或 https),允许 Service 指定是否通过 HTTPS 抓取指标,适用于需要安全连接的场景
target_label: __scheme__
regex: (https?) # 匹配 http 或 https,若注解未设置,默认使用 http
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace # 检查 Service 的注解 prometheus.io/path,将匹配的值替换到 __metrics_path__ 标签,指定指标端点的路径
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace # 将地址和端口组合替换到 __address__ 标签,允许 Service 指定抓取端口(如 prometheus.io/port: "8080"),覆盖 Endpoints 的默认端口
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap # 将 Service 的标签(如 app=my-app)映射到 Prometheus 指标标签
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace] # 将 Service 的命名空间(__meta_kubernetes_namespace)写入指标标签 kubernetes_namespace
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name] # 将 Service 名称(__meta_kubernetes_service_name)写入指标标签 kubernetes_name
action: replace
target_label: kubernetes_name
alerting: # 定义 Prometheus 与 Alertmanager 的连接,用于发送告警
alertmanagers: # 指定 Alertmanager 实例的地址
- static_configs:
- targets: ["prometheus.kube-ops.svc.cluster.local:9093"] # <service-name>.<namespace>.svc.<cluster-domain>
rule_files: # 指定告警规则文件路径
- /etc/prometheus/rules.yml执行资源清单
# 执行资源清单,重新加载 ConfigMap
$ kubectl apply -f prometheus-cm.yaml
# 热更新 ConfingMap
$ kubectl get svc -n kube-ops
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
grafana NodePort 10.109.7.30 <none> 3000:30339/TCP 19h
prometheus NodePort 10.102.229.198 <none> 9090:31676/TCP,9093:31878/TCP 44h
$ curl -X POST http://10.102.229.198:9090/-/reload浏览器访问 Prometheus 查看告警规则是否生效
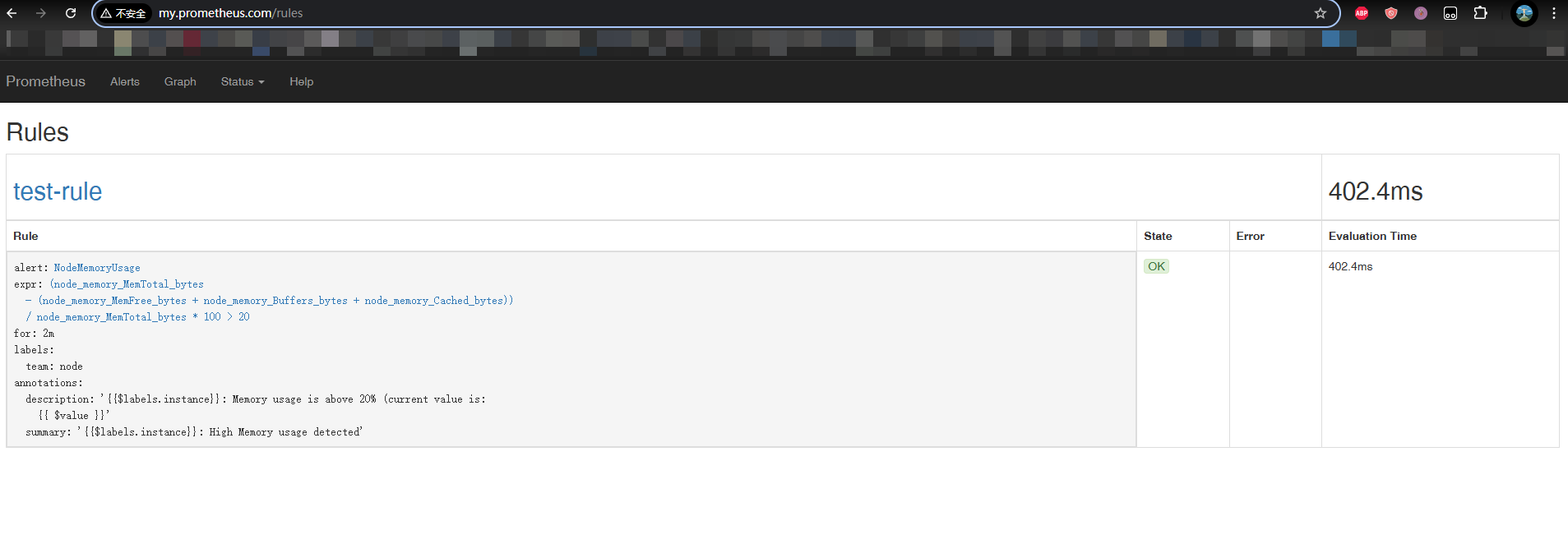
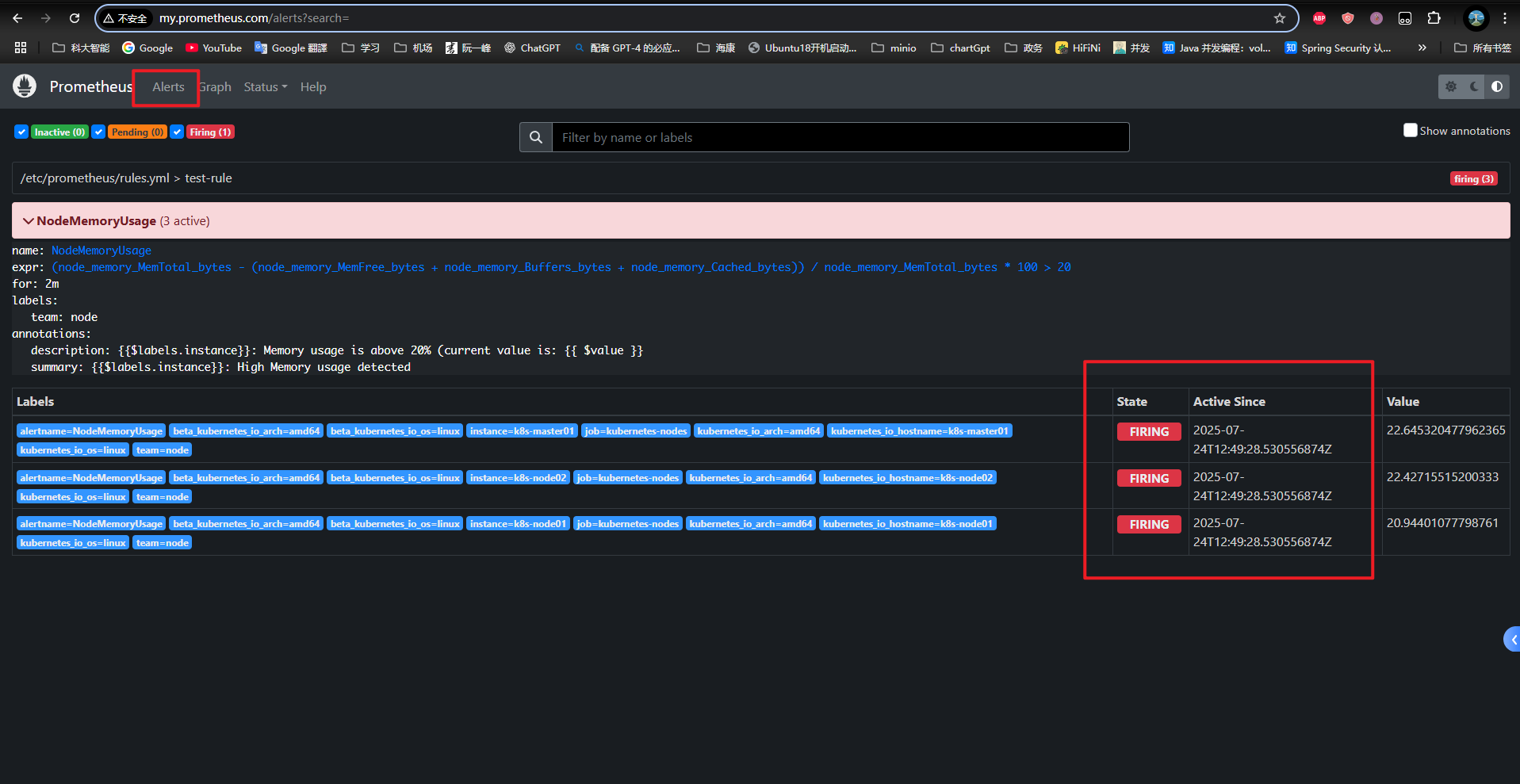
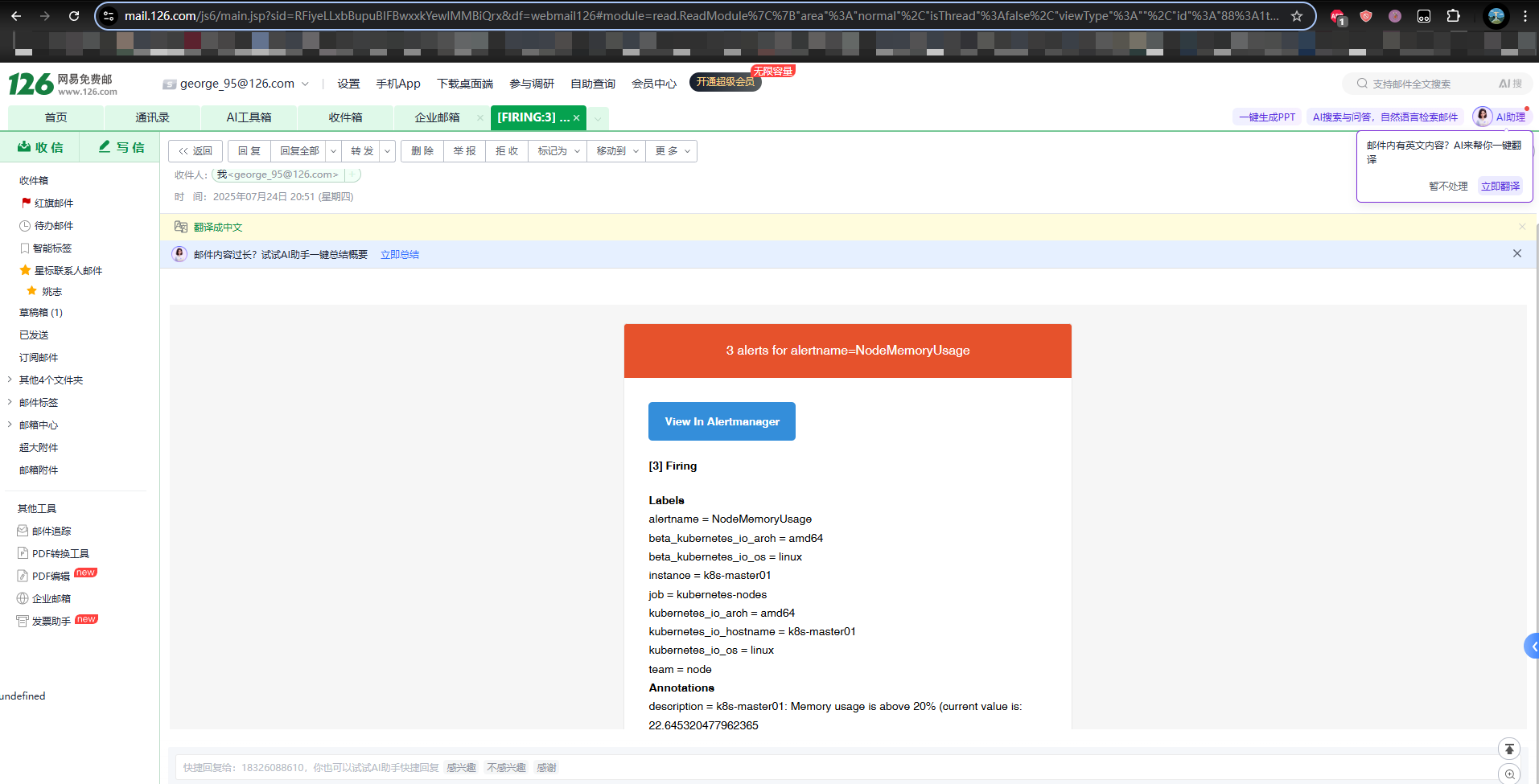
参考链接
https://zhangquan.me/2022/09/04/shi-yong-prometheus-jian-kong-kubernetes-ji-qun-jie-dian/
https://cloudmessage.top/archives/prometheus-shou-dong-pei-zhi-jian-kong-kubernetesji-qun
https://www.cnblogs.com/cyh00001/p/16725312.html
https://csms.tech/202212141608/#%E7%89%88%E6%9C%AC%E4%BF%A1%E6%81%AF
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 george_95@126.com