系统环境
操作系统:Ubuntu18.04.6
Docker:24.0.2
Neo4j: 3.5.35(社区版)
一、下载并启动Neo4j
1. 修改Docker配置文件
neo4j镜像在国外服务器,国内直接pull会超时失败,这里需要配置一下代理。
创建docker默认的配置文件路径
mkdir -p /etc/docker
内容如下:直接拷贝粘贴
tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://docker-proxy.741001.xyz","https://registry.docker-cn.com"]
}
EOF
重启docker服务
systemctl daemon-reload
systemctl restart docker2. 启动neo4j
拉取镜像
拉取镜像 docker pull neo4j:3.5.35 查看本地镜像,检验是否拉取成功 docker images创建挂载目录
mkdir -p /opt/module /opt/software mkdir -p /opt/module/neo4j cd /opt/module/neo4j/ mkdir -p data logs conf import plugins启动容器
docker run -itd \ --name neo4j \ -p 7474:7474 -p 7687:7687 \ -v /opt/module/neo4j/data:/data \ -v /opt/module/neo4j/logs:/logs \ -v /opt/module/neo4j/conf:/var/lib/neo4j/conf \ -v /opt/module/neo4j/import:/var/lib/neo4j/import \ -v /opt/module/neo4j/plugins:/var/lib/neo4j/plugins \ --env NEO4J_AUTH=neo4j/123456 \ --restart=always \ neo4j:3.5.35命令解析
docker run -itd --name container_name \ //-d表示容器后台运行 --name指定容器名字 -p 7474:7474 -p 7687:7687 \ //映射容器的端口号到宿主机的端口号 -v /opt/module/neo4j/data:/data \ //把容器内的数据目录挂载到宿主机的对应目录下 -v /opt/module/neo4j/logs:/logs \ //挂载日志目录 -v /opt/module/neo4j/conf:/var/lib/neo4j/conf //挂载配置目录 -v /opt/module/neo4j/import:/var/lib/neo4j/import \ //挂载数据导入目录 -v /opt/module/neo4j/plugins:/var/lib/neo4j/plugins \ // neo4j插件安装目录 --env NEO4J_AUTH=neo4j/123456 \ //设定数据库的名字的访问密码 --restart=always \ // 设置开机自启 neo4j:3.5.35 //指定使用的镜像
挂载目录可根据实际情况替换,neo4j密码不设置,默认为:
neo4j, 这里设置成:123456。如果希望neo4j没有密码,可以使用命令:
--env NEO4J_AUTH=none
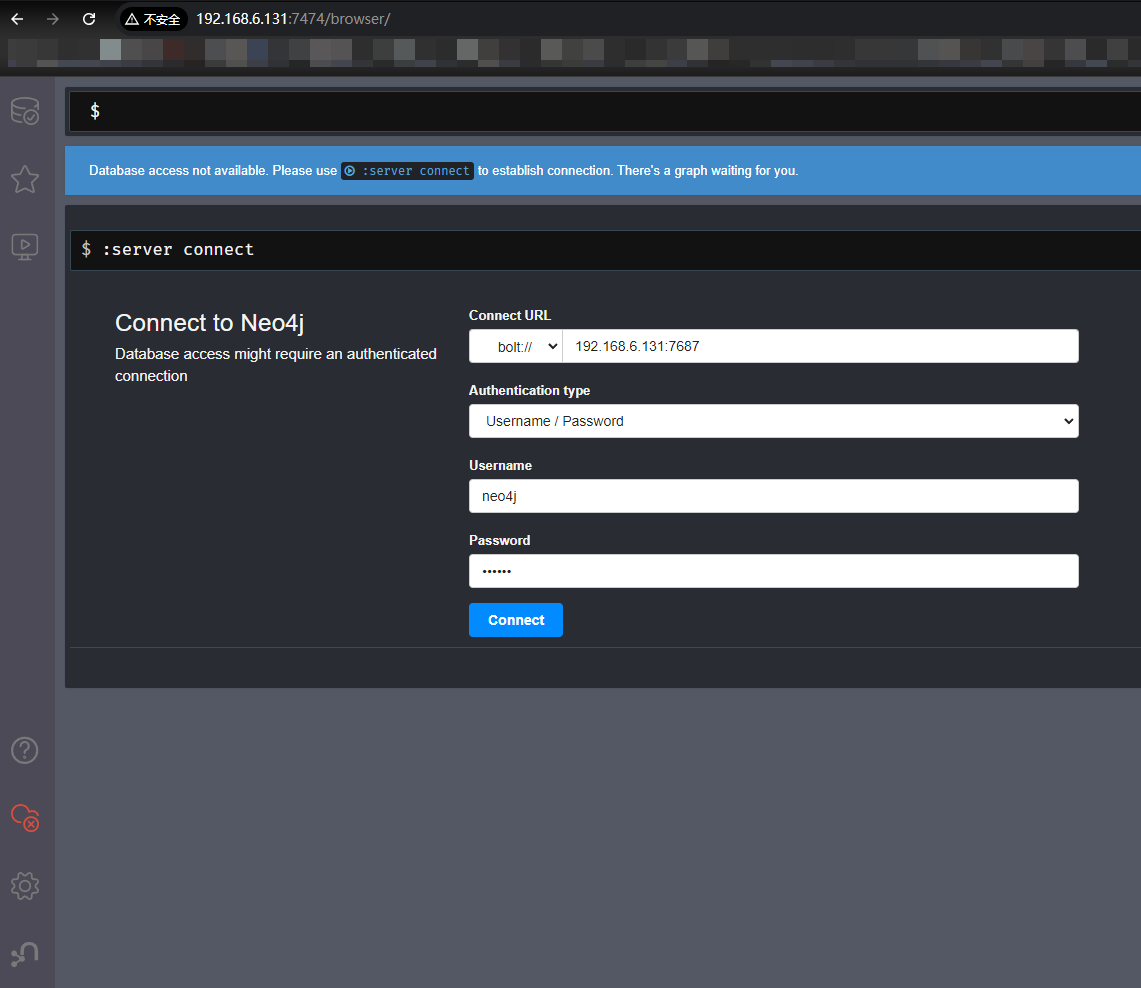
3. 浏览器访问测试
浏览器访问地址:http://Neo4j服务地址:7474
- 数据库默认用户名:neo4j
- 密码:启动命令设置的密码
4. Neo4j配置文件解读
宿主机目录:/opt/module/neo4j/conf/neo4j.conf
启动后,配置文件会自动创建到挂在目录,默认内容如下:
事务保留策略,超过100MB会进行轮换
dbms.tx_log.rotation.retention_policy=100M size
设置了 Neo4j 的页面缓存大小为 512MB,页面缓存用于存储从磁盘加载到内存中的节点和关系数据,以提高数据库查询的性能。
dbms.memory.pagecache.size=512M
允许任何ip连接到数据库
dbms.connectors.default_listen_address=0.0.0.0
https请求的监听 地址:端口
dbms.connector.https.listen_address=0.0.0.0:7473
http请求的监听 地址:端口
dbms.connector.http.listen_address=0.0.0.0:7474
bolt请求的监听 地址:端口
dbms.connector.bolt.listen_address=0.0.0.0:7687
这是一个 Java 运行时参数,表明 Neo4j 是运行在 Docker 环境下的
wrapper.java.additional=-Dneo4j.ext.udc.source=docker
指定了 Neo4j 日志文件的存储目录为 /logs
dbms.directories.logs=/logs二、CSV数据的导入导出
1. 数据准备
上面只是通过docker启动了一个Neo4j数据库实例,此时还没有数据,在演示neo4j数据的导入、导出之前,需要先模拟一些数据到Neo4j中。
删除所有的节点和关系
MATCH(n) OPTIONAL MATCH (n)-[r]-() DELETE n,r;
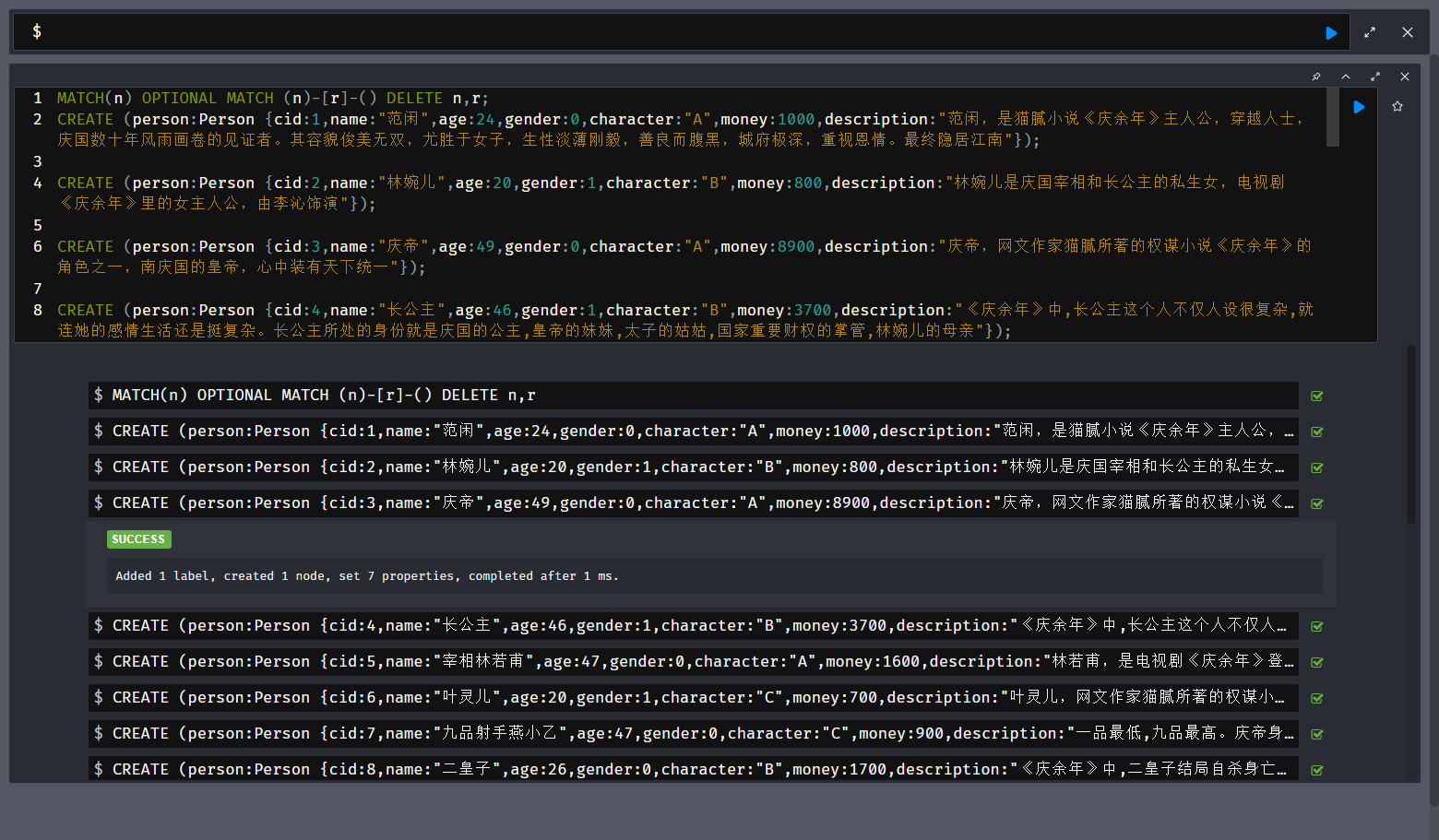
创建Person 的节点
CREATE (person:Person {cid:1,name:"范闲",age:24,gender:0,character:"A",money:1000,description:"范闲,是猫腻小说《庆余年》主人公,穿越人士,庆国数十年风雨画卷的见证者。其容貌俊美无双,尤胜于女子,生性淡薄刚毅,善良而腹黑,城府极深,重视恩情。最终隐居江南"});
CREATE (person:Person {cid:2,name:"林婉儿",age:20,gender:1,character:"B",money:800,description:"林婉儿是庆国宰相和长公主的私生女,电视剧《庆余年》里的女主人公,由李沁饰演"});
CREATE (person:Person {cid:3,name:"庆帝",age:49,gender:0,character:"A",money:8900,description:"庆帝,网文作家猫腻所著的权谋小说《庆余年》的角色之一,南庆国的皇帝,心中装有天下统一"});
CREATE (person:Person {cid:4,name:"长公主",age:46,gender:1,character:"B",money:3700,description:"《庆余年》中,长公主这个人不仅人设很复杂,就连她的感情生活还是挺复杂。长公主所处的身份就是庆国的公主,皇帝的妹妹,太子的姑姑,国家重要财权的掌管,林婉儿的母亲"});
CREATE (person:Person {cid:5,name:"宰相林若甫",age:47,gender:0,character:"A",money:1600,description:"林若甫,是电视剧《庆余年》登场的虚拟人物之一,南庆当朝宰相,林婉儿的亲生父亲。"});
CREATE (person:Person {cid:6,name:"叶灵儿",age:20,gender:1,character:"C",money:700,description:"叶灵儿,网文作家猫腻所著的权谋小说《庆余年》的角色之一,林婉儿的好友,最后嫁给了二皇子"});
CREATE (person:Person {cid:7,name:"九品射手燕小乙",age:47,gender:0,character:"C",money:900,description:"一品最低,九品最高。庆帝身边的燕小乙便是九品,而且是庆国独一无二的神射手,臂力、眼力、听力惊人"});
CREATE (person:Person {cid:8,name:"二皇子",age:26,gender:0,character:"B",money:1700,description:"《庆余年》中,二皇子结局自杀身亡。二皇子对庆帝也是意见很大,但以他的实力还掀不起什么水花,所以只能慢慢等待时机"});
CREATE (person:Person {cid:9,name:"靖王世子",age:25,gender:0,character:"A",money:1600,description:"在《庆余年》中,此靖王非彼靖王,但是同音之美也会让人会对靖王世子李弘成这个角色产生好感,而靖王世子李弘成的出场的确是帮助了范闲逃脱太子势力的纠缠"});
CREATE (person:Person {cid:10,name:"王启年",age:46,gender:0,character:"C",money:1700,description:"王启年,网文作家猫腻所著的权谋小说《庆余年》的角色之一,庆国监察院一处的文书,擅长追踪之术。"});
CREATE (person:Person {cid:11,name:"北齐圣女海棠朵朵",age:21,gender:1,character:"A",money:2600,description:"海棠朵朵是北齐国的才女,被人尊称为圣女,而且是北齐大宗师苦荷的关门弟子,在北齐国也算是举足轻重的人物"});
CREATE (person:Person {cid:12,name:"北齐小皇帝战豆豆",age:20,gender:0,character:"A",money:4600,description:"很多人想知道剧中的北齐小皇帝是谁呢?让小编告诉你们吧。 战豆豆是北齐第二任皇帝,乃前北魏一代大将战清风之孙,大宗师苦荷的叔侄女兼徒孙"});
创建关系
match(person:Person {name:"范闲"}),(person2:Person {name:"林婉儿"}) create(person)-[r:Couple]->(person2);
match(person:Person {name:"范闲"}),(person2:Person {name:"王启年"}) create(person)-[r:Friends]->(person2);
match(person:Person {name:"范闲"}),(person2:Person {name:"北齐圣女海棠朵朵"}) create(person)-[r:Friends]->(person2);
match(person:Person {name:"范闲"}),(person2:Person {name:"庆帝"}) create(person)-[r:Father]->(person2);
match(person:Person {name:"范闲"}),(person2:Person {name:"长公主"}) create(person)-[r:Wife_Mother]->(person2);
match(person:Person {name:"庆帝"}),(person2:Person {name:"二皇子"}) create(person)-[r:Son]->(person2);
match(person:Person {name:"庆帝"}),(person2:Person {name:"长公主"}) create(person)-[r:BrotherSister]->(person2);
match(person:Person {name:"二皇子"}),(person2:Person {name:"靖王世子"}) create(person)-[r:Friends]->(person2);
match(person:Person {name:"北齐圣女海棠朵朵"}),(person2:Person {name:"北齐小皇帝战豆豆"}) create(person)-[r:Friends]->(person2);
match(person:Person {name:"林婉儿"}),(person2:Person {name:"叶灵儿"}) create(person)-[r:Friends]->(person2);
match(person:Person {name:"林婉儿"}),(person2:Person {name:"宰相林若甫"}) create(person)-[r:Father]->(person2);
match(person:Person {name:"林婉儿"}),(person2:Person {name:"长公主"}) create(person)-[r:Mother]->(person2);
match(person:Person {name:"长公主"}),(person2:Person {name:"九品射手燕小乙"}) create(person)-[r:Friends]->(person2);将上面的CQL语句,复制到Neo4j执行语句输入框中,注意:不能有注释内容。
2. 安装 apoc 插件
APOC(Awesome Procedures on Cypher)是Neo4j图数据库的一个插件,它提供了一组强大的过程和函数,扩展了Cypher查询语言的功能。APOC可以帮助你进行更高级的数据处理和操作,例如导入和导出数据、动态创建节点和关系、执行事务操作等。
使用APOC插件需要先下载并安装它,然后在Neo4j的配置文件中启用它。一旦启用,你就可以在Cypher查询中使用APOC提供的各种过程和函数了。
2.1 下载插件
neo4j这里使用的是 3.5社区版,所以 apoc 插件也选择3.5版本的。
下载地址:https://github.com/neo4j-contrib/neo4j-apoc-procedures/releases
找到对应的版本后,下载到服务器的 plugins 文件夹中
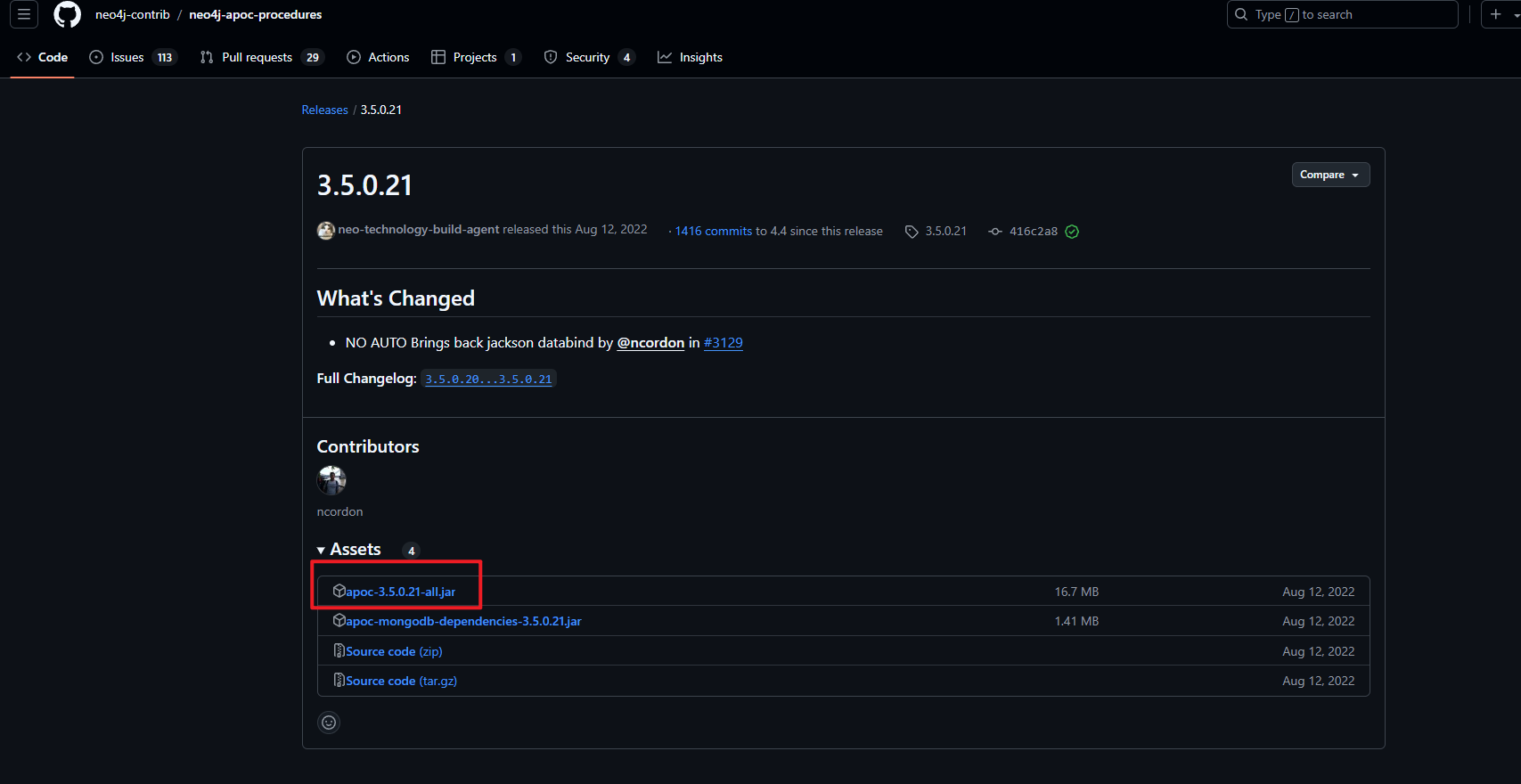
Neo4j的插件安装目录在 plugins 路径下,Docker部署Neo4j时,将宿主机 /opt/module/neo4j/plugins 目录映射到了neo4j的插件安装目录: /var/lib/neo4j/plugins, 因此需要将 apoc 插件下载到此目录中,无需解压。
root@csg-pc1:/opt/module/neo4j/plugins# pwd
/opt/module/neo4j/plugins
root@csg-pc1:/opt/module/neo4j/plugins# ls
apoc-3.5.0.21-all.jar
修改插件jar包的权限(添加执行权限)
chmod 755 apoc-3.5.0.21-all.jar2.2 修改配置文件
修改neo4j配置文件 neo4j.conf , 修改内容如下:
neo4j插件安装路径
dbms.directories.plugins=plugins
配置安全白名单,指定允许所有apoc开头的存储过程
dbms.security.procedures.whitelist=apoc.coll.*,apoc.load.*,apoc.*,gds.*
放宽apoc权限
dbms.security.procedures.unrestricted=apoc.*,algo.*
指定了 Neo4j 的数据导入目录
dbms.directories.import=import
开启文件导出功能
apoc.export.file.enabled=true
开启文件导入功能
apoc.import.file.enabled=true2.3 测试apoc插件是否安装 成功
在浏览器中,执行 cypher-shell:
return apoc.version();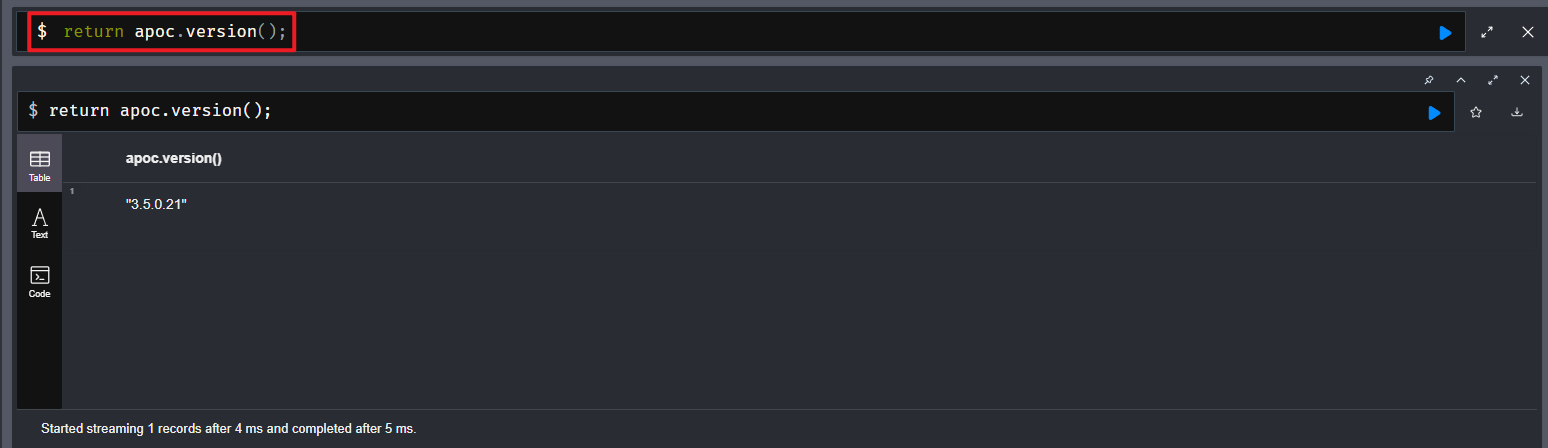
3. 导出CSV数据
3.1 开始导出
neo4j 官方文档有说明,使用 neo4j-admin restore / dump 导出和恢复数据库的时候需要停掉数据,否则会报数据库正在使用的错误:
command failed: the database is in use — stop Neo4j and try again
但问题是docker容器中是没办法停止neo4j进程的,现在进入容器shudown的话,neo4j容器会停掉(docker-run)或者重启数据库(docker-compose),所以这里采用的迂回的方法:
首先停掉neo4j容器
docker stop neo4j启动一个带有TTY新的容器,使用-v参数挂载data目录
docker run -it \ --name neo4j-tmp \ -p 7474:7474 -p 7687:7687 \ -v /opt/module/neo4j/data:/data \ -v /opt/module/neo4j/conf:/var/lib/neo4j/conf \ -v /opt/module/neo4j/import:/var/lib/neo4j/import \ -v /opt/module/neo4j/plugins:/var/lib/neo4j/plugins \ --restart=always \ neo4j:3.5.35 /bin/bash以console方式启动neo4j容器
这里有个坑,如果不用
console启动容器, 而是使用bin/neo4j start启动临时neo4j容器,导出的csv文件格式有问题,会导入不了。bin/neo4j console导出CSV文件
在浏览器 Neo4j 的
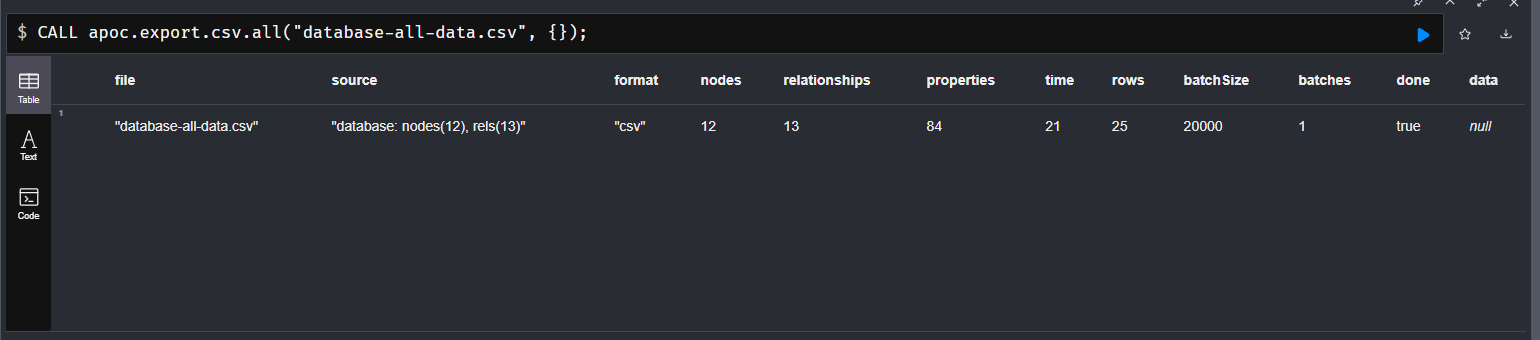
cypher-shell输入框中执行语句方式一:批量导出全部数据到一个csv文件中, 【强烈不建议】
// 导出全部数据(包括了节点和关系)[这个不常用,了解就行] CALL apoc.export.csv.all("database-all-data.csv", {});方式二:批量导出全部数据,但是会自动将
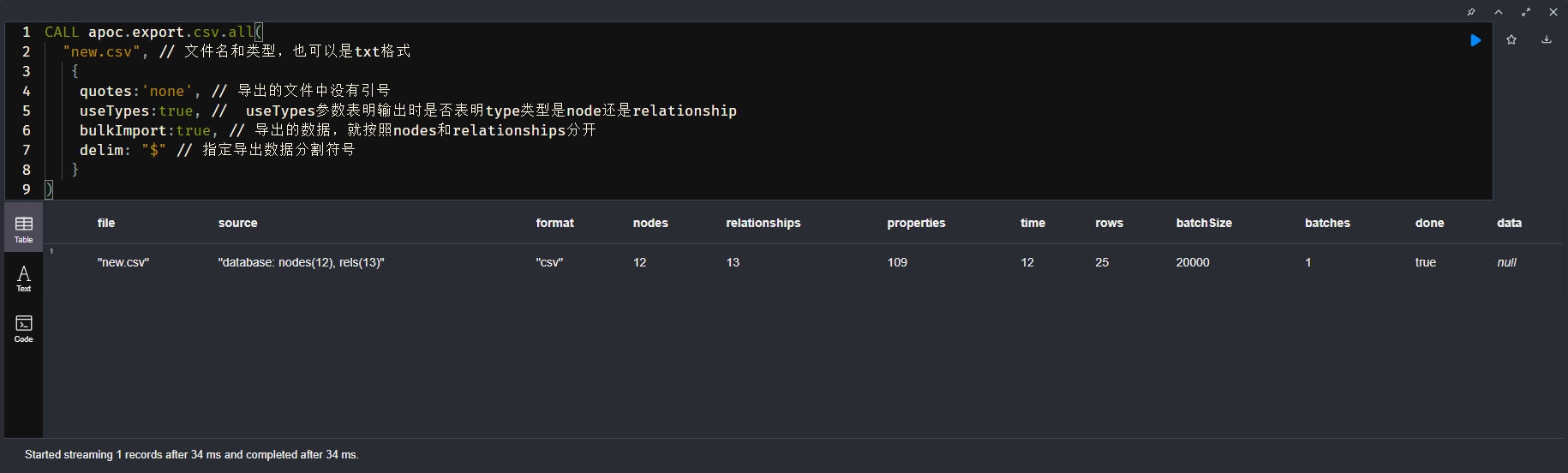
节点数据和关系数据自动分到不同到文件中 【本文采用的就是这种方式】
// 批量导出【建议用这个,亲测可行】 CALL apoc.export.csv.all( "all.csv", // 文件名和类型,也可以是txt格式 { quotes:'none', // 导出的文件中没有引号 useTypes:true, // useTypes参数表明输出时是否表明type类型是node还是relationship bulkImport:true, // 导出的数据,就按照nodes和relationships分开 delim: "$" // 指定导出数据分割符号 } )方式三:手动导出节点数据和关系数据
// 导出所有节点数据,忽略关系 MATCH (person:Person) WITH collect(person) AS people CALL apoc.export.csv.query( "MATCH (p:Person) RETURN id(p) AS `:ID`, p.name AS `name`, p.age AS `age:long`, p.cid AS `cid:long`, p.character AS `character`, p.money AS `money:long`, p.gender AS `gender:long`, p.description AS `description`, head(labels(p)) AS `:LABEL`", "all_nodes.csv", // 导出的文件 { quotes:'none', // 文件中没有引号 delim: "$", // 指定导出数据的分割符号 useTypes:true, // useTypes参数表明输出时是否表明type类型是node还是relationship arrayDelim: ";" } ) YIELD file, source, format, nodes, relationships, properties, time, rows, batchSize, batches, done, data RETURN file, source, format, nodes, relationships, properties, time, rows, batchSize, batches, done, data // 导出特定的关系数据,忽略节点 MATCH (start)-[r:BrotherSister]->(end) WITH start, end, r CALL apoc.export.csv.query( "MATCH (start:Person)-[r:BrotherSister]->(end:Person) RETURN id(start) AS `:START_ID`, id(end) AS `:END_ID`, type(r) AS `:TYPE`", "BrotherSister.csv", { quotes:'none', // 导出的文件中没有引号 useTypes:true, // useTypes参数表明输出时是否表明type类型是node还是relationship delim: "$" // 指定导出数据分割符号 } ) YIELD file, source, format, nodes, relationships, properties, time, rows, batchSize, batches, done, data RETURN file, source, format, nodes, relationships, properties, time, rows, batchSize, batches, done, data
3.2 查看导出文件
导出文件在neo4j的
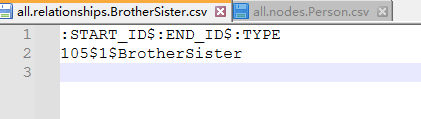
import文件夹中,映射到宿主机:/opt/module/neo4j/import路径,查看该路径:root@csg-pc1:/opt/module/neo4j/import# pwd /opt/module/neo4j/import root@csg-pc1:/opt/module/neo4j/import# ls all.nodes.Person.csv all.relationships.BrotherSister.csv all.relationships.Couple.csv all.relationships.Father.csv all.relationships.Friends.csv all.relationships.Mother.csv all.relationships.Son.csv all.relationships.Wife_Mother.csv查看CSV文件
虽然CSV文件可以用wps、office等工具查看和修改,但是还是如果需要修改的话,用 nodepad++、vsCode等相对简单的文本编辑工具,如果不小心修改了文件编码,或者wps等工具在保存时修改了格式,CSV文件导入就会报错。
文件要使用UTF-8编码,这也是默认的编码格式。

4. 导入CSV数据
前面已经将neo4j数据导出到一个个 CSV 文件中了,导入数据也使用 APOC 插件,但是不需要在 bin/neo4j console 启动环境中导入。可以退出并删除临时容器,启动原有的 ne4j 容器。
删除临时容器
删除临时容器 docker rm -f neo4j-tmp启动原neo4j容器
docker start neo4j清空数据库
在浏览器 Neo4j 的
cypher-shell输入框中执行语句MATCH(n) OPTIONAL MATCH (n)-[r]-() DELETE n,r;将导出的csv文件拷贝到neo4j的 import 文件夹中
使用 APOC 插件导入CSV文件
在浏览器 Neo4j 的
cypher-shell输入框中执行语句方式一:批量导入节点和节点的关系【本文使用的导入方式】 CALL apoc.import.csv( [ {fileName: 'file:/all.nodes.Person.csv', labels: ['Person']} ], [ {fileName: 'file:/all.relationships.Mother.csv', type: 'relationships'}, {fileName: 'file:/all.relationships.BrotherSister.csv', type: 'relationships'}, {fileName: 'file:/all.relationships.Couple.csv', type: 'relationships'}, {fileName: 'file:/all.relationships.Father.csv', type: 'relationships'}, {fileName: 'file:/all.relationships.Friends.csv', type: 'relationships'}, {fileName: 'file:/all.relationships.Son.csv', type: 'relationships'}, {fileName: 'file:/all.relationships.Wife_Mother.csv', type: 'relationships'} ], { delimiter: '$', // 指定数据分隔符,导出时用的是$符号,导入也得用它 arrayDelimiter: ';', // 指定数组元素分隔符,默认:; stringIds: false } )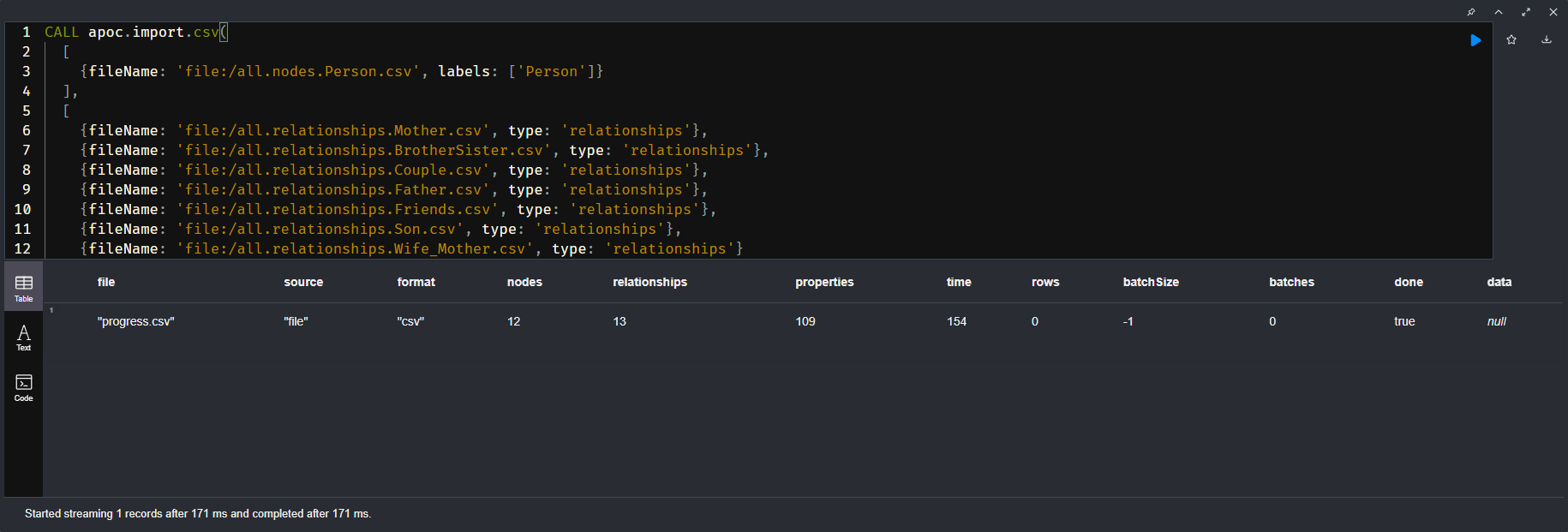
- 方式二,单独导入节点和关系
// 只导入节点,不导入关系 CALL apoc.import.csv( [ {fileName: 'file:/all_nodes.csv', labels: ['Person']} ], [], // 没有关系要在这个步骤中导入 { delimiter: '$', // 指定数据分隔符,导出时用的是$符号,导入也得用它 arrayDelimiter: ';', // 指定数组元素分隔符,默认:; stringIds: false } ) // 只导入关系,不导入节点(我试了,不行,报空指针) CALL apoc.import.csv( [], [ {fileName: 'file:/BrotherSister.csv', type: 'BrotherSister'} ], { delimiter: '$', // 指定数据分隔符,导出时用的是$符号,导入也得用它 arrayDelimiter: ';', // 指定数组元素分隔符,默认:; stringIds: false } ) // 同时导入节点和关系(可以) CALL apoc.import.csv( [ {fileName: 'file:/all_nodes.csv', labels: ['Person']} ], [{fileName: 'file:/BrotherSister.csv', type: 'BrotherSister'}], // 没有关系要在这个步骤中导入 { delimiter: '$', // 指定数据分隔符,导出时用的是$符号,导入也得用它 arrayDelimiter: ';', // 指定数组元素分隔符,默认:; stringIds: false } )
总结
neo4j数据的导出、导入坑很多,相对资料又比较少,以上都是亲自测试的可行方案。
如今neo4j已经出到 5.x 版本了,这篇还是使用的 3.5 版本,主要是因为算法部门他们训练和测试使用的是这个版本,与他们保持一致,后续有时间的话再研究一下新版本。
参考链接
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 george_95@126.com