一、设计模式的目的
编写软件过程中,程序员面临着来自耦合性,内聚性以及可维护性,可扩展性,重用性,灵活性 等多方面的 挑战,设计模式是为了让程序(软件) ,具有更好的
- 代码重用性 (即:相同功能的代码,不用多次编写)
- 可读性 (即:编程规范性, 便于其他程序员的阅读和理解)
- 可扩展性 (即:当需要增加新的功能时,非常的方便,称为可维护)
- 可靠性 (即:当我们增加新的功能后,对原来的功能没有影响)
- 可靠性 (即:当我们增加新的功能后,对原来的功能没有影响)
二、单一职责原则(Single Responsibility Principle)
1. 基本介绍
就一个类而言,应该仅有一个引起它变化的原因。应该只有一个职责。如果一个类有一个以上的职责,这些职责就耦合在了一起。一个职责的变化可能会削弱或者抑制这个类完成其他职责的能力。这会导致脆弱的设计。当一个职责发生变化时,可能会影响其它的职责。另外,多个职责耦合在一起,会影响复用性。想要避免这种现象的发生,就要尽可能的遵守单一职责原则。
单一职责原则的核心就是解耦和增强内聚性。
2. 为什么要遵守单一职责原则?
提高类的可维护性和可读写性
一个类的职责少了,复杂度降低了,代码就少了,可读性也就好了,可维护性自然就高了。
提高系统的可维护性
系统是由类组成的,每个类的可维护性高,相对来讲整个系统的可维护性就高。当然,前提是系统的架构没有问题。
降低变更的风险
一个类的职责越多,变更的可能性就越大,变更带来的风险也就越大
如果在一个类中可能会有多个发生变化的东西,这样的设计会带来风险, 我们尽量保证只有一个可以变化,其他变化的就放在其他类中,这样的好处就是 提高内聚,降低耦合。
3. 单一职责原则应用的范围
单一职责原则适用的范围有接口、方法类。按大家的说法,接口和方法必须保证单一职责,类就不必保证,只要符合业务就行。
3.1 【方法层面】单一职责原则的应用
现在有一个场景, 需要修改用户的用户名和密码. 就针对这个功能我们可以有多种实现.
第一种:
/**
* 操作的类型
*/
public enum OperateEnum {
UPDATE_USERNAME,
UPDATE_PASSWORD;
}
public interface UserOperate {
void updateUserInfo(OperateEnum type, UserInfo userInfo);
}
public class UserOperateImpl implements UserOperate{
public void updateUserInfo(OperateEnum type, UserInfo userInfo) {
if (type == OperateEnum.UPDATE_PASSWORD) {
// 修改密码
} else if(type == OperateEnum.UPDATE_USERNAME) {
// 修改用户名
}
}
}第二种方法:
public interface UserOperate {
void updateUserName(UserInfo userInfo);
void updateUserPassword(UserInfo userInfo);
}
public class UserOperateImpl implements UserOperate {
public void updateUserName(UserInfo userInfo) {
// 修改用户名逻辑
}
public void updateUserPassword(UserInfo userInfo) {
// 修改密码逻辑
}
}来看看这两种实现的区别:
- 第一种实现是根据操作类型进行区分, 不同类型执行不同的逻辑. 把修改用户名和修改密码这两件事耦合在一起了. 如果客户端在操作的时候传错了类型, 那么就会发生错误.
- 第二种实现是我们推荐的实现方式. 修改用户名和修改密码逻辑分开. 各自执行各自的职责, 互不干扰. 功能清晰明了.
由此可见, 第二种设计是符合单一职责原则的. 这是在方法层面实现单一职责原则.
3.2 【接口层面】单一职责原则的应用
我们假设一个场景, 大家一起做家务, 张三扫地, 李四买菜. 李四买完菜回来还得做饭. 这个逻辑怎么实现呢?
方式一
/**
* 做家务
*/
public interface HouseWork {
// 扫地
void sweepFloor();
// 购物
void shopping();
}
public class Zhangsan implements HouseWork{
public void sweepFloor() {
// 扫地
}
public void shopping() {
}
}
public class Lisi implements HouseWork{
public void sweepFloor() {
}
public void shopping() {
// 购物
}
}首先定义了一个做家务的接口, 定义两个方法扫地和买菜. 张三扫地, 就实现扫地接口. 李四买菜, 就实现买菜接口. 然后李四买完菜回来还要做饭, 于是就要在接口类中增加一个方法cooking. 张三和李四都重写这个方法, 但只有李四有具体实现.
这样设计本身就是不合理的. 首先: 张三只扫地, 但是他需要重写买菜方法, 李四不需要扫地, 但是李四也要重写扫地方法. 第二: 这也不符合开闭原则. 增加一种类型做饭, 要修改3个类. 这样当逻辑很复杂的时候, 很容易引起意外错误.
上面这种设计不符合单一职责原则, 修改一个地方, 影响了其他不需要修改的地方.
方法二
/**
* 做家务
*/
public interface Hoursework {
}
public interface Shopping extends Hoursework{
// 购物
void shopping();
}
public interface SweepFloor extends Hoursework{
// 扫地
void sweepFlooring();
}
public class Zhangsan implements SweepFloor{
public void sweepFlooring() {
// 张三扫地
}
}
public class Lisi implements Shopping{
public void shopping() {
// 李四购物
}
}上面做家务不是定义成一个接口, 而是将扫地和做家务分开了. 张三扫地, 那么张三就实现扫地的接口. 李四购物, 李四就实现购物的接口. 后面李四要增加一个功能做饭. 那么就新增一个做饭接口, 这次只需要李四实现做饭接口就可以了.
public interface Cooking extends Hoursework{
void cooking();
}
public class Lisi implements Shopping, Cooking{
public void shopping() {
// 李四购物
}
public void cooking() {
// 李四做饭
}
}如上, 我们看到张三没有实现多余的接口, 李四也没有. 而且当新增功能的时候, 只影响了李四, 并没有影响张三. 这就是符合单一职责原则. 一个类只做一件事. 并且他的修改不会带来其他的变化.
4. 如何遵守单一职责原则
4.1 合理的职责分解
相同的职责放到一起,不同的职责分解到不同的接口和实现中去,这个是最容易也是最难运用的原则,关键还是要从业务出发,从需求出发,识别出同一种类型的职责。
例子:人的行为分析,包括了生活和工作等行为的分析,生活行为包括吃、跑、睡等行为,工作行为包括上下班,开会等行为,如下图所示:
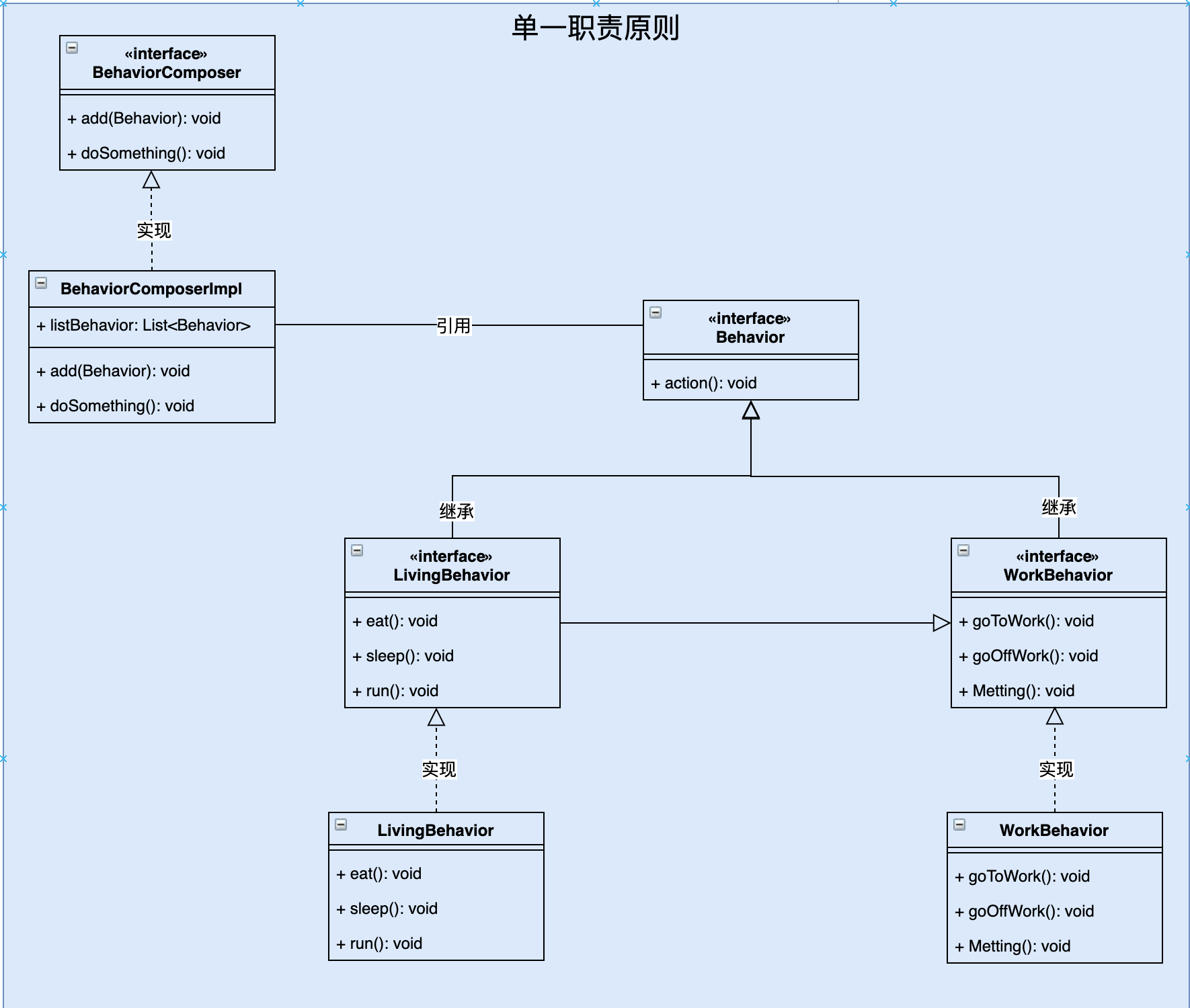
人类的行为分成了两个接口:生活行为接口、工作行为接口,以及两个实现类。如果都用一个实现类来承担这两个接口的职责,就会导致代码臃肿,不易维护,如果以后再加上其他行为,例如学习行为接口,将会产生变更风险(这里还用到了组合模式)。
4.2 代码实现
第一步: 定义一个行为接口
/**
* 人的行为
* 人的行为包括两种: 生活行为, 工作行为
*/
public interface IBehavior {
}这里面定义了一个空的接口, 行为接口. 具体这个行为接口下面有哪些接口呢?有生活和工作两方面的行为.
第二步: 定义生活和工作接口, 并且他们都是行为接口的子类
生活行为接口:
public interface LivingBehavior extends IBehavior{
/** 吃饭 */
void eat();
/** 跑步 */
void running();
/** 睡觉 */
void sleeping();
}工作行为接口:
public interface WorkingBehavior extends IBehavior{
/** 上班 */
void goToWork();
/** 下班 */
void goOffWork();
/** 开会 */
void meeting();
}第三步: 定义工作行为接口和生活行为接口的实现类
生活行为接口实现类:
public class LivingBehaviorImpl implements LivingBehavior{
public void eat() {
System.out.println("吃饭");
}
public void running() {
System.out.println("跑步");
}
public void sleeping() {
System.out.println("睡觉");
}
}工作行为接口实现类:
public class WorkingBehaviorImpl implements WorkingBehavior{
public void goToWork() {
System.out.println("上班");
}
public void goOffWork() {
System.out.println("下班");
}
public void meeting() {
System.out.println("开会");
}
}第四步: 行为组合调用
行为接口定义好了. 接下来会定义一个行为集合. 不同的用户拥有的行为是不一样 , 有的用户只用生活行为, 有的用户既有生活行为又有工作行为. 我们并不知道具体用户到底会有哪些行为, 所以,通常使用一个集合来接收用户的行为. 用户有哪些行为, 就往里面添加哪些行为.
行为组合接口BehaviorComposer
public interface BehaviorComposer { void add(IBehavior behavior); }行为组合接口实现类IBehaviorComposerImpl
public class IBehaviorComposerImpl implements BehaviorComposer { private List<IBehavior> behaviors = new ArrayList<>(); public void add(IBehavior behavior) { System.out.println("添加行为"); behaviors.add(behavior); } public void doSomeThing() { behaviors.forEach(b->{ if(b instanceof LivingBehavior) { LivingBehavior li = (LivingBehavior)b; // 处理生活行为 } else if(b instanceof WorkingBehavior) { WorkingBehavior wb = (WorkingBehavior) b; // 处理工作行为 } }); } }
第五步: 客户端调用
用户在调用的时候, 根据实际情况调用就可以了, 比如下面的代码: 张三是全职妈妈, 只有生活行为, 李四是职场妈妈, 既有生活行为又有工作行为.
public static void main(String[] args) {
// 张三--全职妈妈
LivingBehavior zslivingBehavior = new LivingBehaviorImpl();
BehaviorComposer zsBehaviorComposer = new IBehaviorComposerImpl();
zsBehaviorComposer.add(zslivingBehavior);
// 李四--职场妈妈
LivingBehavior lsLivingBehavior = new LivingBehaviorImpl();
WorkingBehavior lsWorkingBehavior = new WorkingBehaviorImpl();
BehaviorComposer lsBehaviorComposer = new IBehaviorComposerImpl();
lsBehaviorComposer.add(lsLivingBehavior);
lsBehaviorComposer.add(lsWorkingBehavior);
}5. 单一职责原则的优缺点
- 类的复杂性降低: 一个类实现什么职责都有清晰明确的定义了, 复杂性自然就降低了
- 可读性提高: 复杂性降低了,可读性自然就提高了
- 可维护性提高: 可读性提高了,代码就更容易维护了
- 变更引起的风险降低: 变更是必不可少的,如果接口的单一职责做得好,一个接口修改只对相应的实现类有影响,对其他的接口和类无影响,这对系统的扩展性、维护性都有非常大的帮助
三、接口隔离原则(Interface Segregation Principle)
1. 接口隔离原则的定义
客户端只依赖于它所需要的接口;它需要什么接口就提供什么接口,把不需要的接口剔除掉。
类间的依赖关系应建立在最小的接口上。
也就是说: 接口尽量细化,接口中的方法尽量少
2. 接口隔离原则和单一职责原则
功能上来看,接口隔离原则和单一职责原则都是为了提高类的内聚, 降低类之间的耦合, 体现了封装的思想。但二者还是有区别的。
- 从原则约束来看: 接口隔离原则更关注的是接口依赖程度的隔离;而单一职责原则更加注重的是接口职责的划分。
- 从接口的细化程度来看: 单一职责原则对接口的划分更加精细,而接口隔离原则注重的是相同功能的接口的隔离。接口隔离里面的最小接口有时可以是多个单一职责的公共接口。
- 单一职责原则更加偏向对业务的约束: 接口隔离原则更加偏向设计架构的约束。这个应该好理解,职责是根据业务功能来划分的,所以单一原则更加偏向业务;而接口隔离更多是为了“高内聚”,偏向架构的设计。
3. 接口隔离原则的优点
接口隔离原则是为了约束接口、降低类对接口的依赖性,遵循接口隔离原则有以下 5 个优点。
- 将臃肿庞大的接口分解为多个粒度小的接口,可以预防外来变更的扩散,提高系统的灵活性和可维护性。
- 接口隔离提高了系统的内聚性,减少了对外交互,降低了系统的耦合性。
- 如果接口的粒度大小定义合理,能够保证系统的稳定性;然而,如果定义过小,则会造成接口数量过多,使设计复杂化;如果定义太大,灵活性降低,无法提供定制服务,给整体项目带来无法预料的风险。
- 使用多个专门的接口能够体现对象的层次,因为可以通过接口的继承,实现对总接口的定义。
- 能减少项目工程中的代码冗余。过大的大接口里面通常放置许多不用的方法,当实现这个接口的时候,被迫设计冗余的代码。
4. 接口隔离原则的实现方法
在具体应用接口隔离原则时,应该根据以下几个规则来衡量。
接口要尽量小
不能出现Fat Interface;但是要有限度,首先不能违反单一职责原则(不能一个接口对应半个职责)。
接口要高内聚
在接口中尽量少公布public方法。 接口是对外的承诺,承诺越少对系统的开发越有利。
定制服务
只提供访问者需要的方法。例如,为管理员提供IComplexSearcher接口,为公网提供ISimpleSearcher接口。
接口的设计是有限度的
了解环境,拒绝盲从。每个项目或产品都有选定的环境因素,环境不同,接口拆分的标准就不同, 需要深入了解业务逻辑。
5. 接口隔离原则的建议
- 一个接口只服务于一个子模块或业务逻辑;
- 通过业务逻辑压缩接口中的public方法;
- 已被污染了的接口,尽量去修改;若变更的风险较大,则采用适配器模式转化处理;
- 拒绝盲从
6. 案例分析
下面以学生成绩管理为例来说明接口隔离原则:
分析:学生成绩管理程序一般包含查询成绩、新增成绩、删除成绩、修改成绩、计算总分、计算平均分、打印成绩信息等功能,通常我们会怎么做呢?
6.1 最初的设计
通常我们设计接口的方式如下:
public interface IStudentScore {
// 查询成绩
public void queryScore();
// 修改成绩
public void updateScore();
// 添加成绩
public void saveScore();
// 删除成绩
public void delete();
// 计算总分
public double sum();
// 计算平均分
public double avg();
// 打印成绩单
public void printScore();
}我们会吧所有的功能都放在一个接口里面. 这会产生什么样的问题呢?
首先, 接口的方法很多, 不利于扩展. 比如: 学生只有查看成绩,打印成绩单的权限, 没有增删改的权限; 老师拥有所有的权限.
查询成绩单:
package com.lxl.www.designPatterns.sixPrinciple.interfaceSegregationPrinciple.score;
public class QueryScore implements IStudentScore{
public void queryScore() {
// 查询成绩
}
public void updateScore() {
// 没有权限
}
public void saveScore() {
// 没有权限
}
public void delete() {
// 没有权限
}
public double sum() {
// 没有权限
return 0;
}
public double avg() {
// 没有权限
return 0;
}
public void printScore() {
//打印成绩单
}
}操作成绩单
package com.lxl.www.designPatterns.sixPrinciple.interfaceSegregationPrinciple.score;
public class Operate implements IStudentScore{
public void queryScore() {
}
public void updateScore() {
}
public void saveScore() {
}
public void delete() {
}
public double sum() {
return 0;
}
public double avg() {
return 0;
}
public void printScore() {
}
}可以看出问题. 查询成绩单, 我们只会用到两个方法, 可是因为实现了接口, 不得不重写所有的方法.
如果这时候增加需求–发送给家长, 只有老师才有这个权限, 学生没有这个权限. 可是, 在接口中增加一个抽象方法以后, 所有的实现类都要重写这个方法. 这就违背了开闭原则.
6.2 使用接口隔离原则的设计
采用接口隔离原则设计的接口, 代码如下:
public interface IQueryScore {
// 查询成绩
public void queryScore();
// 打印成绩单
public void printScore();
}
public interface IOperateScore {
// 修改成绩
public void updateScore();
// 添加成绩
public void saveScore();
// 删除成绩
public void delete();
// 计算总分
public double sum();
// 计算平均分
public double avg();
}
public class StudentOperate implements IQueryScore{
public void queryScore() {
// 查询成绩
}
public void printScore() {
//打印成绩单
}
}
public class TeacherOperate implements IQueryScore, IOperateScore{
public void queryScore() {
}
public void updateScore() {
}
public void saveScore() {
}
public void delete() {
}
public double sum() {
return 0;
}
public double avg() {
return 0;
}
public void printScore() {
}
}我们将原来的一个接口进行了接口拆分. 分为查询接口和操作接口. 这样学生端就不需要重写和他不相关的接口了.
如果将这些功能全部放到一个接口中显然不太合理,正确的做法是将它们分别放在输入模块、统计模块和打印模块等 3 个模块中。
四、依赖倒转原则(Dependence Inversion Principle)
1. 概念
依赖倒置原则(Dependence Inversion Principle, DIP), 其含义:
- 高层模块不应该依赖低层模块,两者都应该依赖其抽象
- 抽象不应该依赖细节, 细节应该依赖于抽象
- 要针对接口编程,不要针对实现编程
2. 什么是依赖?
这里的依赖关系我们理解为UML关系中的依赖。简单的说就是A use B,那么A对B产生了依赖。具体请看下面的例子。
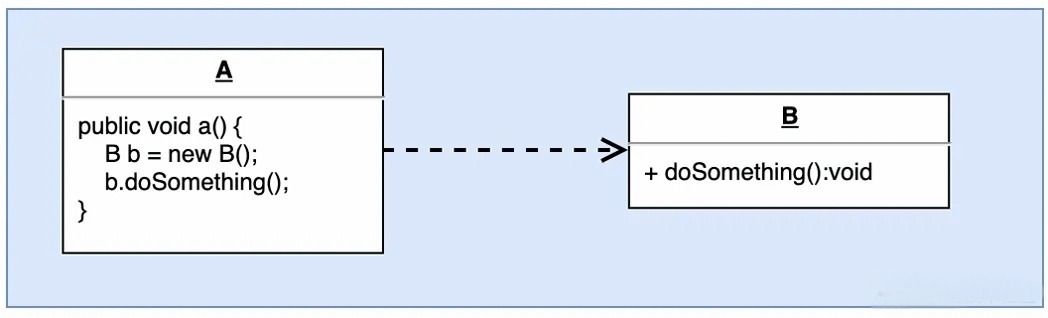
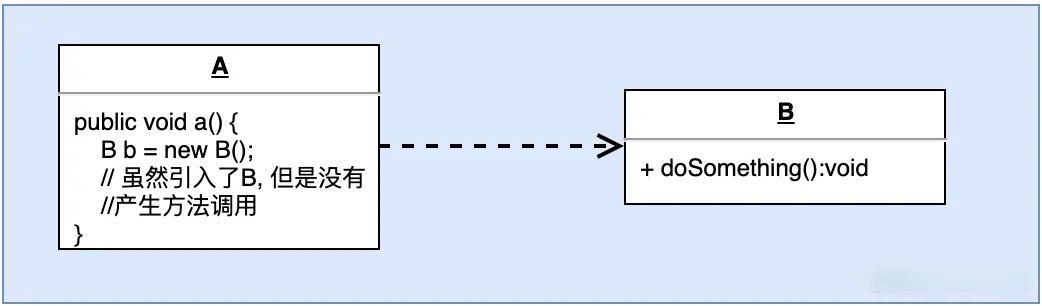
从上图中我们可以发现, 类A中的方法a()里面用到了类B, 其实这就是依赖关系, A依赖了B. 需要注意的是: 并不是说A中声明了B就叫依赖, 如果引用了但是没有真实调用方法, 那么叫做零耦合关系. 如下图:
3. 依赖的关系种类
1、零耦合关系:如果两个类之间没有耦合关系,称之为零耦合
2、直接耦合关系: 具体耦合发生在两个具体类(可实例化的)之间,经由一个类对另一个类的直接引用造成。
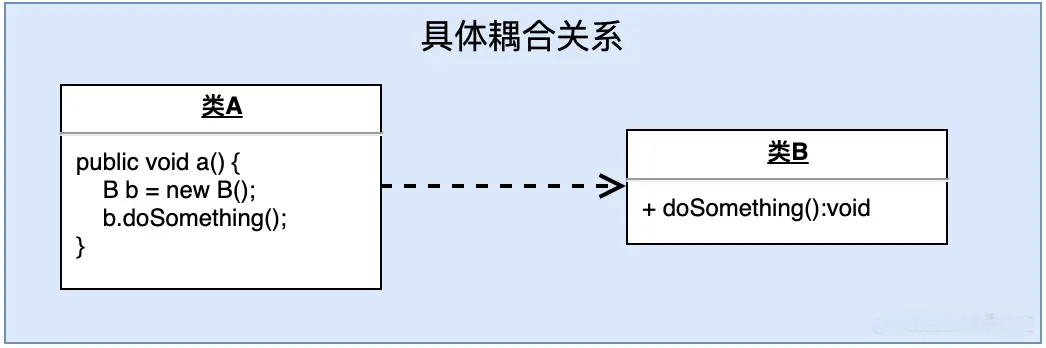
3、抽象耦合关系: 抽象耦合关系发生在一个具体类和一个抽象类(或者java接口)之间,使两个必须发生关系的类之间存在最大的灵活性。
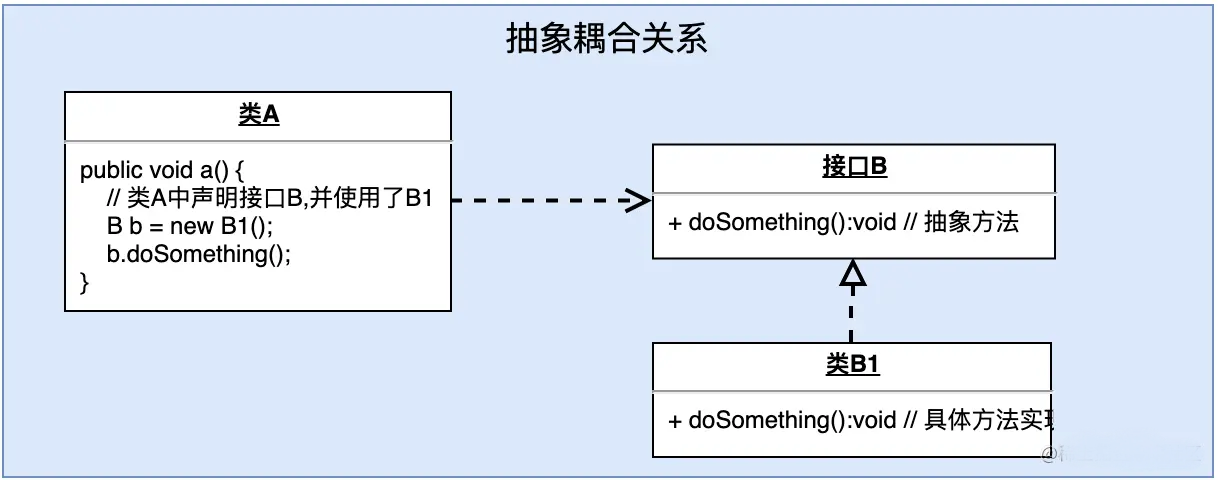
依赖倒转原则就是要针对接口编程,不要针对实现编程。这就是说,应当使用接口或者抽象类进行变量的类型声明,参数的类型声明,方法的返回类型说明,以及数据类型的转换等。
4. 依赖倒置的案例
4.1 初步设计方案
public class Benz {
public void run() {
System.out.println("奔驰跑起来了!");
}
}
public class Driver {
private String name;
public Driver(String name) {
this.name = name;
}
public void driver(Benz benz) {
benz.run();
}
}
public class CarTest {
public static void main(String[] args) {
Benz benz = new Benz();
Driver driver = new Driver("张三");
driver.driver(benz);
}
}有一个驾驶员张三可以驾驶奔驰汽车, 于是最开始我们思考, 会有一个驾驶员类, 有一个奔驰汽车类. 随着业务的发展, 我们发现, 驾驶员张三还可以驾驶宝马.
于是,我们定义一个BM类,
public class BM {
public void run() {
System.out.println("宝马跑起来了!");
}
}这时, 张三如果想要开宝马, 就要将宝马注册在他名下.
public class Driver {
private String name;
public Driver(String name) {
this.name = name;
}
public void driver(Benz benz) {
benz.run();
}
public void driver(BM bm) {
bm.run();
}
}
public class CarTest {
public static void main(String[] args) {
Benz benz = new Benz();
BM bm = new BM();
Driver driver = new Driver("张三");
driver.driver(benz);
driver.driver(bm);
}
}似乎这样就可以了, 但是这样有什么问题呢?
- 如果张三有一天要开大众, 还要增加一个大众车类, 同时还得挂载司机名下.
- 不是所有的人都要开奔驰, 开宝马. 开大众.
这就是面向实现编程的问题, 接下来我们就要考虑面向接口编程.
4.2 改进后的方案
public interface ICar {
public void run();
}
public class Benz implements ICar{
public void run() {
System.out.println("奔驰跑起来了!");
}
}
public class BM implements ICar{
public void run() {
System.out.println("宝马跑起来了!");
}
}
public interface IDriver {
public void driver(ICar car);
}
public class Driver implements IDriver{
public void driver(ICar car) {
car.run();
}
}
public class CarTest {
public static void main(String[] args) {
IDriver driver = new Driver();
driver.driver(new Benz());
driver.driver(new BM());
}
}修改后的代码, 提炼出来一个IDriver接口和ICar接口, 面向接口编程. IDriver的实现类驾驶员可以driver任何类型的汽车, 所以传入参数也是一个接口ICar. 任何类型的汽车, 都可以通过实现ICar接口注册为一种新的汽车类型. 当客户端调用的时候, 将对应的汽车传入就可以了.
5.依赖的方式
5.1 依赖注入主要有三种方式
构造注入
在构造的时候注入依赖
Setter方法注入
接口方法中注入(汽车的例子使用的就是此方法)
5.2 依赖倒置原则在设计模式中的体现
- 简单工厂设计模式, 使用的是接口方法中注入
- 策略设计模式: 在构造函数中注入
五、里氏替换原则(Liskov Substitution Principle)
1. 什么是里式替换原则
1.1 里式替换原则定义
里式替换原则是用来帮助我们在继承关系中进行父子类的设计。
里氏替换原则(Liskov Substitution principle)是对子类型的特别定义的. 为什么叫里式替换原则呢?因为这项原则最早是在1988年,由麻省理工学院的一位姓里的女士(Barbara Liskov)提出来的。
里氏替换原则主要阐述了有关继承的一些原则,也就是什么时候应该使用继承,什么时候不应该使用继承,以及其中蕴含的原理。里氏替换原是继承复用的基础,它反映了基类与子类之间的关系,是对开闭原则的补充,是对实现抽象化的具体步骤的规范。
里式替换原则有两层定义:
定义1:
If S is a subtype of T, then objects of type T may be replaced with objects of type S, without breaking the program。 如果S是T的子类,则T的对象可以替换为S的对象,而不会破坏程序。
定义2:
Functions that use pointers of references to base classes must be able to use objects of derived classes without knowing it。
所有引用其父类对象方法的地方,都可以透明的替换为其子类对象
这两种定义方式其实都是一个意思,即:应用程序中任何父类对象出现的地方,我们都可以用其子类的对象来替换,并且可以保证原有程序的逻辑行为和正确性。
1.2 里氏替换原则有至少有两种含义
- 里氏替换原则是针对继承而言的,如果继承是为了实现代码重用,也就是为了共享方法,那么共享的父类方法就应该保持不变,不能被子类重新定义。子类只能通过新添加方法来扩展功能,父类和子类都可以实例化,而子类继承的方法和父类是一样的,父类调用方法的地方,子类也可以调用同一个继承得来的,逻辑和父类一致的方法,这时用子类对象将父类对象替换掉时,当然逻辑一致,相安无事。
- 如果继承的目的是为了多态,而多态的前提就是子类覆盖并重新定义父类的方法,为了符合LSP,我们应该将父类定义为抽象类,并定义抽象方法,让子类重新定义这些方法,当父类是抽象类时,父类就是不能实例化,所以也不存在可实例化的父类对象在程序里。也就不存在子类替换父类实例(根本不存在父类实例了)时逻辑不一致的可能。
不符合LSP的最常见的情况是,父类和子类都是可实例化的非抽象类,且父类的方法被子类重新定义,这一类的实现继承会造成父类和子类间的强耦合,也就是实际上并不相关的属性和方法牵强附会在一起,不利于程序扩展和维护。
2. 使用里式替换原则的目的
采用里氏替换原则就是为了减少继承带来的缺点,增强程序的健壮性,版本升级时也可以保持良好的兼容性。即使增加子类,原有的子类也可以继续运行。
3. 里式替换原则与继承多态之间的关系
里式替换原则和继承多态有关系, 但是他俩并不是一回事. 我们来看看下面的案例
public class Cache {
public void set(String key, String value) {
}
}
public class Redis extends Cache {
public void set(String key, String value) {
}
}
public class Memcache extends Cache {
public void set(String key, String value) {
}
}
public class CacheTest {
public static void main(String[] args) {
// 父类对象都可以接收子类对象
Cache cache = new Cache();
cache.set("key123", "key123");
cache = new Redis();
cache.set("key123", "key123");
cache = new Memcache();
cache.set("key123", "key123");
}
}通过上面的例子, 可以看出Cache是父类, Redis 和 Memcache是子类, 他们继承自Cache. 这是继承和多态的思想. 而且这两个子类目前为止也都符合里式替换原则.可以替换父类出现的任何位置,并且原来代码的逻辑行为不变且正确性也没有被破坏。 看最后的CacheTest类, 我们使用父类的cache可以接收任何一种类型的缓存对象, 包括父类和子类.
但如果我们对Redis中的set方法做了长度校验
public class Redis extends Cache{
public void set(String key, String value) {
if (key == null || key.length() < 10 || key.length() > 100) {
System.out.println("key的长度不符合要求");
throw new IllegalArgumentException(key的长度不符合要求);
}
}
}
public class CacheTest {
public static void main(String[] args) {
// 父类对象都可以接收子类对象
Cache cache = new Cache();
cache.set("key123", "key123");
cache = new Redis();
cache.set("key123", "key123");
}
}如上情况, 如果我们使用父类对象时替换成子类对象, 那么就会抛出异常. 程序的逻辑行为就发生了变化,虽然改造之后的代码仍然可以通过子类来替换父类 ,但是,从设计思路上来讲,Redis子类的设计是不符合里式替换原则的。
继承和多态是面向对象语言所提供的一种语法,是代码实现的思路,而里式替换则是一种思想,一种设计原则,是用来指导继承关系中子类该如何设计的,子类的设计要保证在替换父类的时候,不改变原有程序的逻辑以及不破坏原有程序的正确性。
4. 里式替换的规则
里式替换原则的核心就是“约定”,父类与子类的约定。里氏替换原则要求子类在进行设计的时候要遵守父类的一些行为约定。这里的行为约定包括:函数所要实现的功能,对输入、输出、异常的约定,甚至包括注释中一些特殊说明等。
4.1 子类方法不能违背父类方法对输入输出异常的约定
1、前置条件不能被加强
前置条件即输入参数是不能被加强的,就像上面Cache的示例,Redis子类对输入参数Key的要求进行了加强,此时在调用处替换父类对象为子类对象就可能引发异常。
也就是说,子类对输入的数据的校验比父类更加严格,那子类的设计就违背了里式替换原则。
2、后置条件不能被削弱
后置条件即输出,假设我们的父类方法约定输出参数要大于0,调用父类方法的程序根据约定对输出参数进行了大于0的验证。而子类在实现的时候却输出了小于等于0的值。此时子类的涉及就违背了里氏替换原则
3、不能违背对异常的约定
在父类中,某个函数约定,只会抛出 ArgumentNullException 异常, 那子类的设计实现中只允许抛出 ArgumentNullException 异常,任何其他异常的抛出,都会导致子类违背里式替换原则。
4.2 子类方法不能违背父类方法定义的功能
public class Product {
private BigDecimal amount;
private Calendar createTime;
public BigDecimal getAmount() {
return amount;
}
public void setAmount(BigDecimal amount) {
this.amount = amount;
}
public Calendar getCreateTime() {
return createTime;
}
public void setCreateTime(Calendar createTime) {
this.createTime = createTime;
}
}
public class ProductSort extends Sort<Product> {
public void sortByAmount(List<Product> list) {
//根据时间进行排序
list.sort((h1, h2)->h1.getCreateTime().compareTo(h2.getCreateTime()));
}
}父类中提供的 sortByAmount() 排序函数,是按照金额从小到大来进行排序的,而子类重写这个 sortByAmount() 排序函数之后,却是是按照创建日期来进行排序的。那子类的设计就违背里式替换原则。
实际上对于如何验证子类设计是否符合里氏替换原则其实有一个小技巧,那就是你可以使用父类的单测来运行子类的代码,如果不可以正常运行,那么你就要考虑一下自己的设计是否合理了!
4.3 子类必须完全实现父类的抽象方法
如果你设计的子类不能完全实现父类的抽象方法那么你的设计就不满足里式替换原则。
// 定义抽象类枪
public abstract class AbstractGun{
// 射击
public abstract void shoot();
// 杀人
public abstract void kill();
}比如我们定义了一个抽象的枪类,可以射击和杀人。无论是步枪还是手枪都可以射击和杀人,我们可以定义子类来继承父类
// 定义手枪,步枪,机枪
public class Handgun extends AbstractGun{
public void shoot(){
// 手枪射击
}
public void kill(){
// 手枪杀人
}
}
public class Rifle extends AbstractGun{
public void shoot(){
// 步枪射击
}
public void kill(){
// 步枪杀人
}
}但是如果我们在这个继承体系内加入一个玩具枪,就会有问题了,因为玩具枪只能射击,不能杀人。但是很多人写代码经常会这么写。
public class ToyGun extends AbstractGun{
public void shoot(){
// 玩具枪射击
}
public void kill(){
// 因为玩具枪不能杀人,就返回空,或者直接throw一个异常出去
throw new Exception("我是个玩具枪,惊不惊喜,意不意外,刺不刺激?");
}
}这时,我们如果把使用父类对象的地方替换为子类对象,显然是会有问题的。
而这种情况不仅仅不满足里氏替换原则,也不满足接口隔离原则,对于这种场景可以通过 接口隔离+委托 的方式来解决。
5. 里氏替换原则的作用
- 里氏替换原则是实现开闭原则的重要方式之一。
- 它克服了继承中重写父类造成的可复用性变差的缺点。
- 它是动作正确性的保证。即类的扩展不会给已有的系统引入新的错误,降低了代码出错的可能性。
- 加强程序的健壮性,同时变更时可以做 到非常好的兼容性,提高程序的维护性、可扩展性,降低需求变更时引入的风险。
尽量不要从可实例化的父类中继承,而是要使用基于抽象类和接口的继承。
6. 里氏替换原则的实现方法
里氏替换原则通俗来讲就是:子类可以扩展父类的功能,但不能改变父类原有的功能。也就是说:子类继承父类时,除添加新的方法完成新增功能外,尽量不要重写父类的方法。
根据上述理解,对里氏替换原则的定义可以总结如下:
- 子类可以实现父类的抽象方法,但不能覆盖父类的非抽象方法
- 子类中可以增加自己特有的方法
- 当子类的方法重载父类的方法时,方法的前置条件(即方法的输入参数)要比父类的方法更宽松
- 当子类的方法实现父类的方法时(重写/重载或实现抽象方法),方法的后置条件(即方法的的输出/返回值)要比父类的方法更严格或相等
通过重写父类的方法来完成新的功能写起来虽然简单,但是整个继承体系的可复用性会比较差,特别是运用多态比较频繁时,程序运行出错的概率会非常大。
如果程序违背了里氏替换原则,则继承类的对象在基类出现的地方会出现运行错误。这时其修正方法是:取消原来的继承关系,重新设计它们之间的关系。
7. 案例分析
7.1 案例一: 两数相减
当使用继承时,遵循里氏替换原则。类B继承类A时,除添加新的方法完成新增功能P2外,尽量不要重写父类A的方法,也尽量不要重载父类A的方法。
继承包含这样一层含义:父类中凡是已经实现好的方法(相对于抽象方法而言),实际上是在设定一系列的规范和契约,虽然它不强制要求所有的子类必须遵从这些契约,但是如果子类对这些非抽象方法任意修改,就会对整个继承体系造成破坏。而里氏替换原则就是表达了这一层含义。
继承作为面向对象三大特性之一,在给程序设计带来巨大便利的同时,也带来了弊端。比如使用继承会给程序带来侵入性,程序的可移植性降低,增加了对象间的耦合性,如果一个类被其他的类所继承,则当这个类需要修改时,必须考虑到所有的子类,并且父类修改后,所有涉及到子类的功能都有可能会产生故障。
class A{
public int func1(int a, int b){
return a-b;
}
}
public class Client{
public static void main(String[] args){
A a = new A();
System.out.println("100-50="+a.func1(100, 50));
System.out.println("100-80="+a.func1(100, 80));
}
}运行结果:
100-50=50
100-80=20后来,我们需要增加一个新的功能:完成两数相加,然后再与100求和,由类B来负责。即类B需要完成两个功能:
- 两数相减。
- 两数相加,然后再加100。
由于类A已经实现了第一个功能,所以类B继承类A后,只需要再完成第二个功能就可以了,代码如下:
class B extends A{
public int func1(int a, int b){
return a+b;
}
public int func2(int a, int b){
return func1(a,b)+100;
}
}
public class Client{
public static void main(String[] args){
B b = new B();
System.out.println("100-50="+b.func1(100, 50));
System.out.println("100-80="+b.func1(100, 80));
System.out.println("100+20+100="+b.func2(100, 20));
}
}类B完成后,运行结果:
100-50=150
100-80=180
100+20+100=220我们发现原本运行正常的相减功能发生了错误。原因就是类B在给方法起名时无意中重写了父类的方法,造成所有运行相减功能的代码全部调用了类B重写后的方法,造成原本运行正常的功能出现了错误。在本例中,引用基类A完成的功能,换成子类B之后,发生了异常。在实际编程中,我们常常会通过重写父类的方法来完成新的功能,这样写起来虽然简单,但是整个继承体系的可复用性会比较差,特别是运用多态比较频繁时,程序运行出错的几率非常大。如果非要重写父类的方法,比较通用的做法是:原来的父类和子类都继承一个更通俗的基类,原有的继承关系去掉,采用依赖、聚合,组合等关系代替。
7.2 案例二: “几维鸟不是鸟”
需求分析: 鸟通常都是会飞的, 比如燕子每小时120千米, 但是新西兰的几维鸟由于翅膀退化不会飞. 假如要设计一个实例,计算这两种鸟飞行 300 千米要花费的时间。显然,拿燕子来测试这段代码,结果正确,能计算出所需要的时间;但拿几维鸟来测试,结果会发生“除零异常”或是“无穷大”,明显不符合预期,其类图如图 下 所示。
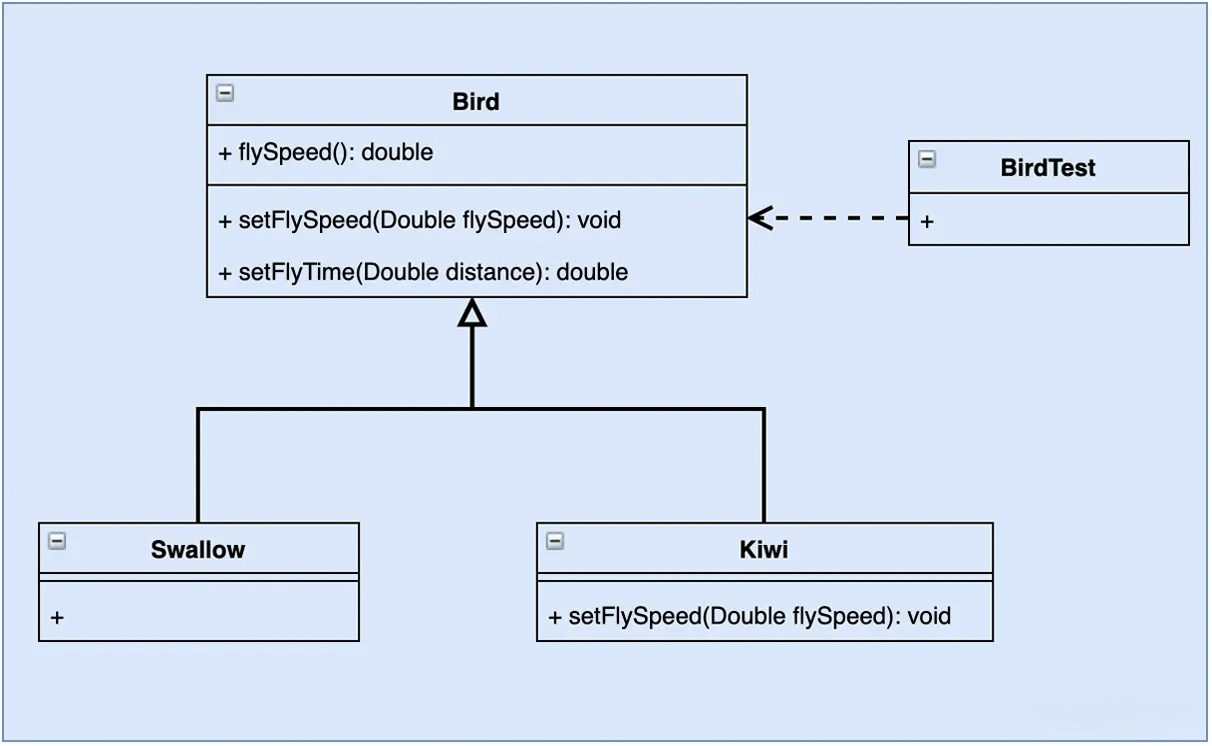
源码如下:
/**
* 鸟
*/
public class Bird {
// 飞行的速度
private double flySpeed;
public void setFlySpeed(double flySpeed) {
this.flySpeed = flySpeed;
}
public double getFlyTime(double distance) {
return distance/flySpeed;
}
}
/**
* 燕子
*/
public class Swallow extends Bird{
}
/**
* 几维鸟
*/
public class Kiwi extends Bird {
public void setFlySpeed(double flySpeed) {
flySpeed = 0;
}
}
/**
* 测试飞行耗费时间
*/
public class BirdTest {
public static void main(String[] args) {
Bird bird1 = new Swallow();
Bird bird2 = new Kiwi();
bird1.setFlySpeed(120);
bird2.setFlySpeed(120);
System.out.println("如果飞行300公里:");
try {
System.out.println("燕子花费" + bird1.getFlyTime(300) + "小时.");
System.out.println("几维花费" + bird2.getFlyTime(300) + "小时。");
} catch (Exception err) {
System.out.println("发生错误了!");
}
}
}运行结果:
如果飞行300公里: 燕子花费2.5小时. 几维花费Infinity小时。程序运行错误的原因是:几维鸟类重写了鸟类的 setSpeed(double speed) 方法,这违背了里氏替换原则。正确的做法是:取消几维鸟原来的继承关系,定义鸟和几维鸟的更一般的父类,如动物类,它们都有奔跑的能力。几维鸟的飞行速度虽然为 0,但奔跑速度不为 0,可以计算出其奔跑 300 千米所要花费的时间。其类图如图 下所示。
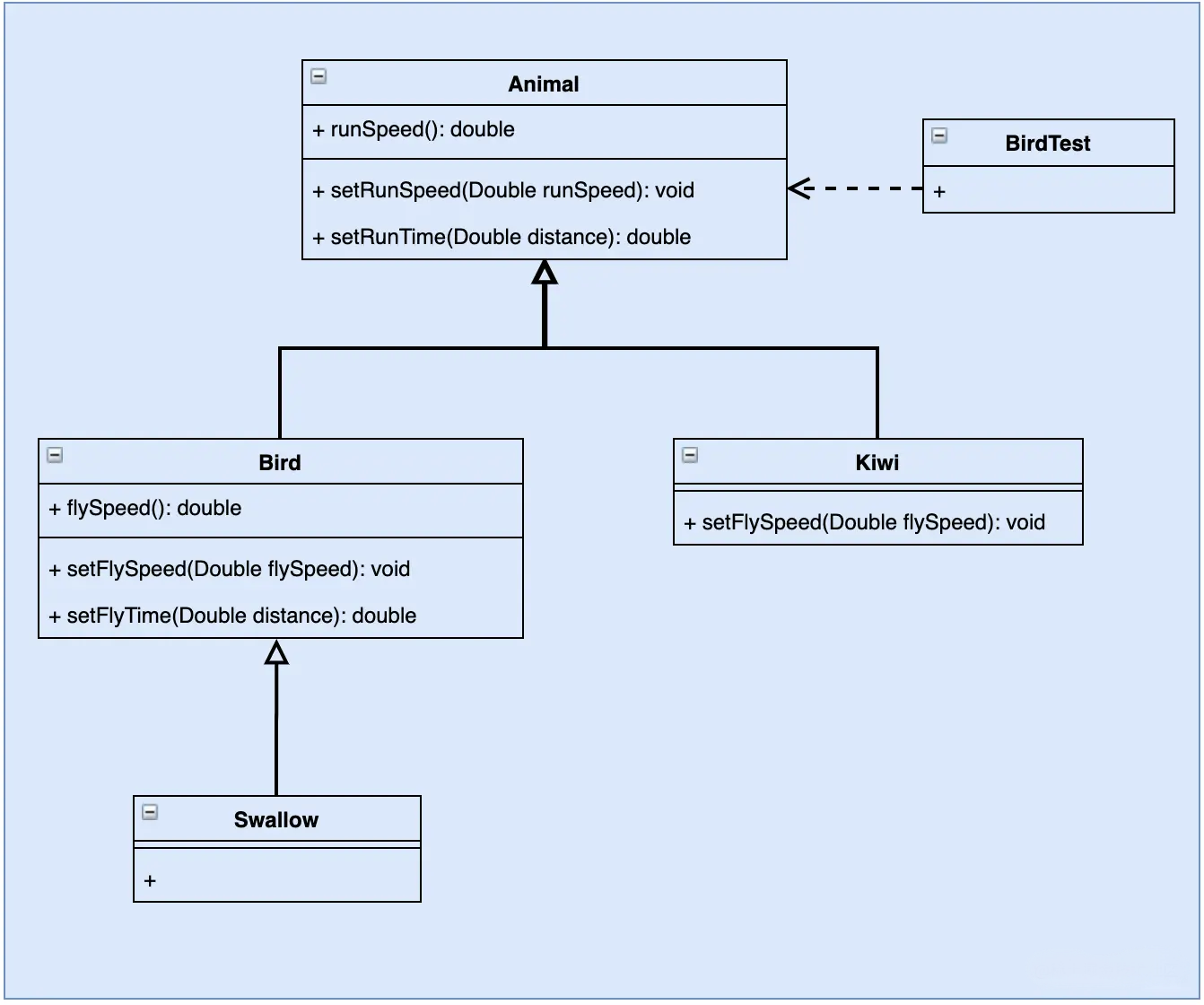
源代码实现如下
/**
* 动物
*/
public class Animal {
private double runSpeed;
public double getRunTime(double distance) {
return distance/runSpeed;
}
public void setRunSpeed(double runSpeed) {
this.runSpeed = runSpeed;
}
}
/**
* 鸟
*/
public class Bird {
// 飞行的速度
private double flySpeed;
public void setFlySpeed(double flySpeed) {
this.flySpeed = flySpeed;
}
public double getFlyTime(double distance) {
return distance/flySpeed;
}
}
/**
* 燕子
*/
public class Swallow extends Bird {
}
/**
* 几维鸟
*/
public class Kiwi extends Animal {
public void setRunSpeed(double runSpeed) {
super.setRunSpeed(runSpeed);
}
}
/**
* 测试飞行耗费时间
*/
public class BirdTest {
public static void main(String[] args) {
Bird bird1 = new Swallow();
Animal bird2 = new Kiwi();
bird1.setFlySpeed(120);
bird2.setRunSpeed(110);
System.out.println("如果飞行300公里:");
try {
System.out.println("燕子花费" + bird1.getFlyTime(300) + "小时.");
System.out.println("几维鸟花费" + bird2.getRunTime(300) + "小时。");
} catch (Exception err) {
System.out.println("发生错误了!");
}
}
}运行结果
如果飞行300公里: 燕子花费2.5小时. 几维鸟花费2.727272727272727小时。总结:
面向对象的编程思想中提供了继承和多态是我们可以很好的实现代码的复用性和可扩展性,但继承并非没有缺点,因为继承的本身就是具有侵入性的,如果使用不当就会大大增加代码的耦合性,而降低代码的灵活性,增加我们的维护成本,然而在实际使用过程中却往往会出现滥用继承的现象,而里式替换原则可以很好的帮助我们在继承关系中进行父子类的设计。
六、开闭原则(Open Closed Principle)
1. 什么是开闭原则
开放封闭原则(OCP,Open Closed Principle)是所有面向对象原则的核心。软件设计本身所追求的目标就是封装变化、降低耦合,而开放封闭原则正是对这一目标的最直接体现。其他的设计原则,很多时候是为实现这一目标服务的.
1.1 开闭原则的定义
Software entities like classes,modules and functions should be open for extension but closed for modifications 一个软件实体, 如类, 模块, 函数等应该对扩展开放, 对修改封闭.
这也是开放封闭原则的核心思想:对扩展开放,对修改封闭.
- 对扩展开放,意味着有新的需求或变化时,可以对现有代码进行扩展,以适应新的情况。
- 对修改封闭,意味着类一旦设计完成,就可以独立完成其工作,而不要对已有代码进行任何修改
2. 如何实现开放封闭原则
“需求总是变化”、“世界上没有一个软件是不变的”。这里投射出的意思是:需求总是变化的, 可是对于软件设计者来说, 如何才能做到不对原有系统修改的前提下, 实现灵活的扩展. 这就是开闭原则要实现的.
我们在设计系统的时候, 不可能设想一次性把需求确定后, 后面就不改变了.这不科学也不现实的. 既然需求是一定会变化的, 那么我们要如何优雅的面对这种变化呢? 如何设计可以使软件相对容易修改, 不至于需求一变, 就要把整个程序推到重来?
开封-封闭原则. 设计软件要容易维护且不容易出问题的最好办法, 就是多扩展, 少修改.
2.1 依赖与抽象
实现开放封闭的核心思想就是面对抽象编程,而不是面对具体编程,因为抽象相对稳定。 让类依赖于固定的抽象,所以对修改是封闭的;而通过面向对象的继承和多态机制,可以实现对抽象体的继承,通过覆写其方法来改变固有行为,实现新的扩展方法,所以对于扩展就是开放的。这是实施开放封闭原则的基本思路。
2.2 如何落地开闭原则
如果当前的设计不符合开放封闭原则,则必须进行重构。常用的设计模式主要有 模板方法(Template Method)设计模式 和 策略(Strategy)设计模式 。而封装变化,是实现这一原则的重要手段,将经常发生变化的部分封装为一个类。
2.3 开闭原则的重要性
开闭原则对测试的影响
开闭原则可是保持原有的测试代码仍然能够正常运行,我们只需要对扩展的代码进行测试就可以了。
开闭原则可以提高复用性
在面向对象的设计中,所有的逻辑都是从原子逻辑组合而来的,而不是在一个类中独立实现一个业务逻辑。只有这样代码才可以复用,粒度越小,被复用的可能性就越大。
开闭原则可以提高可维护性
面向对象开发的要求。
2.4 如何使用开闭原则
抽象约束
- 第一,通过接口或者抽象类约束扩展,对扩展进行边界限定,不允许出现在接口或抽象类中不存在的public方法;
- 第二,参数类型、引用对象尽量使用接口或者抽象类,而不是实现类;
- 第三,抽象层尽量保持稳定,一旦确定即不允许修改。
元数据(metadata)控制模块行为
元数据就是用来描述环境和数据的数据,通俗地说就是配置参数,参数可以从文件中获得,也可以从数据库中获得。
Spring容器就是一个典型的元数据控制模块行为的例子,其中达到极致的就是控制反转(Inversion of Control)
制定项目章程
在一个团队中,建立项目章程是非常重要的,因为章程中指定了所有人员都必须遵守的约定,对项目来说,约定优于配置。
封装变化
对变化的封装包含两层含义:
第一,将相同的变化封装到一个接口或者抽象类中;
第二,将不同的变化封装到不同的接口或抽象类中,不应该有两个不同的变化出现在同一个接口或抽象类中。
3. 案例分析
3.1 案例一: 画形状
需求: 有圆形, 有椭圆形, 根据要求画出相应的形状
public class GraphicEditor {
public void draw(Shape shape) {
if (shape.m_type == 1) {
drawRectangle();
} else if(shape.m_type == 2) {
drawCircle();
}
}
public void drawRectangle() {
System.out.println("画长方形");
}
public void drawCircle() {
System.out.println("画圆形");
}
class Shape {
int m_type;
}
class Rectangle extends Shape {
Rectangle() {
super.m_type=1;
}
}
class Circle extends Shape {
Circle() {
super.m_type=2;
}
}
}我们来看看, 这个代码, 初看是符合要求了, 再想想, 要是我增加一种形状呢? 比如增加三角形.
首先, 要增加一个三角形的类, 继承自Shape ;
第二, 要增加一个画三角形的方法drawTrriage() ;
第三, 在draw方法中增加一种类型type=3的处理方案
这就违背了开闭原则-对扩展开发, 对修改关闭. 增加一个类型, 修改了三处代码.
我们来看看合适的设计
public class GraphicEditor1 {
public void draw(Shape shape) {
shape.draw();
}
interface Shape {
void draw();
}
class Rectangle implements Shape {
public void draw() {
System.out.println("画矩形");
}
}
class Circle implements Shape {
public void draw() {
System.out.println("画圆形");
}
}
}各种类型的形状自己规范自己的行为, 而 GraphicEditor.draw() 只负责画出来. 当增加一种类型三角形. 只需要
第一: 增加一个三角形的类,实现Shape接口
第二, 调用draw方法,划出来就可以了.
整个过程都是在扩展, 而没有修改原来的类. 这个设计是符合开闭原则的.
3.2 案例二
比如现在有一个银行业务, 存钱, 取钱和转账. 最初我们会怎么思考呢?
- 首先有一个银行业务类, 用来处理银行的业务
- 银行有哪些业务呢? 存钱,取钱,转账, 这都是银行要执行的操作
- 那外部说我要存钱, 我要取钱,我要转账, 通过一个类型来告诉我们 代码就生成了
/**
* 银行业务
*/
public class BankBusiness {
public void operate(int type) {
if (type == 1) {
save();
} else if(type == 2) {
take();
} else if(type == 3) {
transfer();
}
}
public void save(){
System.out.println("存钱");
}
public void take(){
System.out.println("取钱");
}
public void transfer() {
System.out.println("转账");
}
}咋一看已经实现了需求. 但是现在有新的需求来了, 银行要增加功能—理财. 理财是银行业务的一种, 自然是新增一个方法. 然后在operate()方法里增加一种类型. 这就是一个糟糕的设计, 增加新功能, 但是却修改了原来的代码.
们设计成接口抽象的形式,源码如下:
public interface Business {
public void operate();
}
public class Save implements Business{
public void operate() {
System.out.println("存钱业务");
}
}
public class Take implements Business {
public void operate() {
System.out.println("取钱业务");
}
}
public class Transfer implements Business {
public void operate() {
System.out.println("转账业务");
}
}
/**
* 银行业务类
*/
public class BankBusinesses {
/**
* 处理银行业务
* @param business
*/
public void operate(Business business) {
System.out.println("处理银行业务");
business.operate();
}
}通过接口抽象的形式方便扩展, 加入要新增理财功能. 只需新增一个理财类, 其他业务代码都不需要修改.
其实, 在日常工作中, 经常会遇到这种情况. 因为我们平时写业务逻辑会更多一些, 而业务就像流水账, 今天一个明天一个一点一点的增加. 所以,当业务增加到3个的时候, 我们就要思考, 如何写能够方便扩展.
总结
- 遵守开闭原则可以提高软件扩展性和维护性。
- 大部分的设计模式和设计原则都是在实现开闭原则。
七、迪米特法则(Demeter Principle)
1. 什么是迪米特法则
迪米特法则(Law of Demeter )又叫做最少知识原则,也就是说,一个对象应当对其他对象尽可能少的了解。不和陌生人说话。英文简写为: LoD。
迪米特法则的目的在于降低类之间的耦合。由于每个类尽量减少对其他类的依赖,因此,很容易使得系统的功能模块功能独立,相互之间不存在(或很少有)依赖关系。
迪米特法则不希望类之间建立直接的联系。如果真的有需要建立联系,也希望能通过它的友元类来转达。因此,应用迪米特法则有可能造成的一个后果就是:系统中存在大量的中介类,这些类之所以存在完全是为了传递类之间的相互调用关系——这在一定程度上增加了系统的复杂度。
2. 为什么要遵守迪米特法则?
在面向对象编程中有一些众所周知的抽象概念,比如封装、内聚和耦合,理论上可以用来生成清晰的设计和良好的代码。虽然这些都是非常重要的概念,但它们不够实用,不能直接用于开发环境,这些概念是比较主观的,非常依赖于使用人的经验和知识。对于其他概念,如单一责任原则、开闭原则等,情况也是一样的。迪米特法则的独特之处在于它简洁而准确的定义,它允许在编写代码时直接应用,几乎自动地应用了适当的封装、低内聚和松耦合。
3. 迪米特法则的广狭义
3.1 狭义的迪米特法则
如果两个类不必彼此直接通信,那么这两个类就不应当发生直接的相互作用。如果其中的一个类需要调用另一个类的某一个方法的话,可以通过第三者转发这个调用。
朋友圈的确定“朋友”条件:
当前对象本身(this)
以参数形式传入到当前对象方法中的对象.
方法入参是一个对象, 这时这个对象和当前类是朋友
当前对象的实例变量直接引用的对象
定义一个类, 里面的属性引用了其他对象, 那么引用对象的实例和当前实例是朋友
当前对象的实例变量如果是一个聚集,那么聚集中的元素也都是朋友
如果属性是一个对象, 那么属性和对象里的元素都是朋友
当前对象所创建的对象
任何一个对象,如果满足上面的条件之一,就是当前对象的“朋友”;否则就是“陌生人”。
狭义的迪米特法则的缺点:
在系统里造出大量的小方法,这些方法仅仅是传递间接的调用,与系统的业务逻辑无关。 遵循类之间的迪米特法则会是一个系统的局部设计简化,因为每一个局部都不会和远距离的对象有直接的关联。但是,这也会造成系统的不同模块之间的通信效率降低,也会使系统的不同模块之间不容易协调。
3.2 广义的迪米特法则在类的设计上的体现
- 优先考虑将一个类设置成不变类。
- 尽量降低一个类的访问权限。
- 谨慎使用Serializable。
- 尽量降低成员的访问权限。
4. 迪米特法则在设计模式中的应用
设计模式的门面模式(Facade)和中介模式(Mediator),都是迪米特法则的应用
下面我们已经租房为例, 来研究迪米特法则. 通常 客户要找房子住, 我们就直接建一个房子类, 建一个客户类, 客户找房子即可.
public interface IHouse {
// 住房子
public void Housing();
}
public class House implements IHouse{
public void Housing() {
System.out.println("住房子");
}
}
public class Customer {
public String name;
public void findHourse(IHouse house) {
house.Housing();
}
}客户找房子住, 逻辑很简单, 这样是ok的. 虽然违背了迪米特法则, 但符合业务逻辑也说得通. 但是, 通常我们找房子, 不是一下子就能找到的, 我们要找很多家, 这就很费劲, 那不如交给中介. 中介有很多房源, 房东吧房子给了中介, 不需要关心租户是谁, 租户将找房的事交给房东, 他也不用管房东是谁, 而且租户+房东都很省事.
/**
* 房子
*/
public interface IHouse {
// 住房子
public void Housing();
}
public class House implements IHouse{
public void Housing() {
System.out.println("住房子");
}
}
public interface ICustomer {
void findHourse(IHouse house) ;
}
public class Customer implements ICustomer {
public void findHourse(IHouse house) {
house.Housing();
}
}
/**
* 中介
*/
public class Intermediary {
// 找房子
public IHouse findHouse(ICustomer customer){
// 帮租户找房子
return null;
}
}房子,客户是相互独立的, 彼此之间没有引用. 他们之间建立关系是通过中介. 也就是, 客户找中介租房子, 房东吧房子交给租户, 最后中介将找好的房子给到客户. 客户和房东彼此隔离, 符合迪米特法则.
5. 迪米特法则实践
那么在实践中如何做到一个对象应该对其他对象有最少的了解呢?如果我们把一个对象看作是一个人,那么要实现“一个人应该对其他人有最少的了解”,做到两点就足够了:
- 只和直接的朋友交流;
- 减少对朋友的了解。下面就详细说说如何做到这两点。
5.1 只和直接的朋友交流
迪米特法则还有一个英文解释是:talk only to your immediate friends(只和直接的朋友交流)。
什么是朋友呢?
每个对象都必然会与其他的对象有耦合关系,两个对象之间的耦合就会成为朋友关系。那么什么又是直接的朋友呢?出现在成员变量、方法的输入输出参数中的类就是直接的朋友。迪米特法则要求只和直接的朋友通信。
注意:
只出现在方法体内部的类就不是直接的朋友,如果一个类和不是直接的朋友进行交流,就属于违反迪米特法则。
我们举一个例子说明什么是朋友,什么是直接的朋友。很简单的例子:老师让班长清点全班同学的人数。这个例子中总共有三个类:老师Teacher、班长GroupLeader和学生Student。
public interface ITeacher {
void command(IGroupLeader groupLeader);
}
public class Teacher implements ITeacher{
public void command(IGroupLeader groupLeader) {
// 全班同学
List<Student> allStudent = new ArrayList<>();
allStudent.add(new Student());
allStudent.add(new Student());
allStudent.add(new Student());
allStudent.add(new Student());
allStudent.add(new Student());
// 班长清点人数
groupLeader.count(allStudent);
}
}
**
* 班长类
*/
public interface IGroupLeader {
// 班长清点人数
void count(List<Student> students);
}
/**
* 班长类
*/
public class GroupLeader implements IGroupLeader{
/**
* 班长清点人数
* @param students
*/
public void count(List<Student> students) {
// 班长清点人数
System.out.println("上课的学生人数是: " + students.size());
}
}
/**
* 学生类
*/
public interface IStudent {
}
/**
* 学生类
*/
public class Student implements IStudent {
}
/**
* 客户端
*/
public class Client {
public static void main(String[] args) {
// 老师类
ITeacher wangTeacher = new Teacher();
// 班长
IGroupLeader zhangBanzhang = new GroupLeader();
wangTeacher.command(zhangBanzhang);
}
}运行结果:
上课的学生人数是: 5在这个例子中,我们的Teacher有几个朋友?两个,一个是GroupLeader,它是Teacher的command()方法的入参;另一个是Student,因为在Teacher的command()方法体中使用了Student。
那么Teacher有几个是直接的朋友?按照直接的朋友的定义
出现在成员变量、方法的输入输出参数中的类就是直接的朋友
只有GroupLeader是Teacher的直接的朋友。
Teacher在command()方法中创建了Student的数组,和非直接的朋友Student发生了交流,所以,上述例子违反了迪米特法则。方法是类的一个行为,类竟然不知道自己的行为与其他的类产生了依赖关系,这是不允许的,严重违反了迪米特法则!
为了使上述例子符合迪米特法则,我们可以做如下修改:
public interface ITeacher {
void command(IGroupLeader groupLeader);
}
public class Teacher implements ITeacher {
public void command(IGroupLeader groupLeader) {
// 班长清点人数
groupLeader.count();
}
}
/**
* 班长类
*/
public interface IGroupLeader {
// 班长清点人数
void count();
}
/**
* 班长类
*/
public class GroupLeader implements IGroupLeader {
private List<Student> students;
public GroupLeader(List<Student> students) {
this.students = students;
}
/**
* 班长清点人数
*/
public void count() {
// 班长清点人数
System.out.println("上课的学生人数是: " + students.size());
}
}
/**
* 学生类
*/
public interface IStudent {
}
/**
* 学生类
*/
public class Student implements IStudent {
}
/**
* 客户端
*/
public class Client {
public static void main(String[] args) {
// 老师类
ITeacher wangTeacher = new Teacher();
List<Student> allStudent = new ArrayList(10);
allStudent.add(new Student());
allStudent.add(new Student());
allStudent.add(new Student());
allStudent.add(new Student());
// 班长
IGroupLeader zhangBanzhang = new GroupLeader(allStudent);
wangTeacher.command(zhangBanzhang);
}
}运行结果:
上课的学生人数是: 4这样修改后,每个类都只和直接的朋友交流,有效减少了类之间的耦合
5.2 减少对朋友的了解
如何减少对朋友的了解?即:在一个类中,就是尽量减少一个类对外暴露的方法
举一个简单的例子说明一个类暴露方法过多的情况。一个人用咖啡机煮咖啡的过程,例子中只有两个类,一个是人,一个是咖啡机。
首先是咖啡机类CoffeeMachine,咖啡机制作咖啡只需要三个方法:1.加咖啡豆;2.加水;3.制作咖啡:
/**
* 咖啡机抽象接口
*/
public interface ICoffeeMachine {
//加咖啡豆
void addCoffeeBean();
//加水
void addWater();
//制作咖啡
void makeCoffee();
}
/**
* 咖啡机实现类
*/
public class CoffeeMachine implements ICoffeeMachine{
//加咖啡豆
public void addCoffeeBean() {
System.out.println("放咖啡豆");
}
//加水
public void addWater() {
System.out.println("加水");
}
//制作咖啡
public void makeCoffee() {
System.out.println("制作咖啡");
}
}
/**
* 人, 制作咖啡
*/
public interface IMan {
/**
* 制作咖啡
*/
void makeCoffee();
}
/**
* 人制作咖啡
*/
public class Man implements IMan {
private ICoffeeMachine coffeeMachine;
public Man(ICoffeeMachine coffeeMachine) {
this.coffeeMachine = coffeeMachine;
}
/**
* 制作咖啡
*/
public void makeCoffee() {
coffeeMachine.addWater();
coffeeMachine.addCoffeeBean();
coffeeMachine.makeCoffee();
}
}
/**
* 客户端
*/
public class Client {
public static void main(String[] args) {
ICoffeeMachine coffeeMachine = new CoffeeMachine();
IMan man = new Man(coffeeMachine);
man.makeCoffee();
}
}运行结果:
加水
放咖啡豆
制作咖啡在这个例子中,CoffeeMachine是Man的直接好友,但问题是Man对CoffeeMachine了解的太多了,其实人根本不关心咖啡机具体制作咖啡的过程。所以我们可以作如下优化:
优化后的咖啡机类,只暴露一个work方法,把制作咖啡的三个具体的方法addCoffeeBean、addWater、makeCoffee设为私有.
/**
* 咖啡机抽象接口
*/
public interface ICoffeeMachine {
//咖啡机工作
void work();
}
/**
* 咖啡机实现类
*/
public class CoffeeMachine implements ICoffeeMachine {
//加咖啡豆
public void addCoffeeBean() {
System.out.println("放咖啡豆");
}
//加水
public void addWater() {
System.out.println("加水");
}
//制作咖啡
public void makeCoffee() {
System.out.println("制作咖啡");
}
public void work() {
addCoffeeBean();
addWater();
makeCoffee();
}
}
/**
* 人, 制作咖啡
*/
public interface IMan {
/**
* 制作咖啡
*/
void makeCoffee();
}
/**
* 人制作咖啡
*/
public class Man implements IMan {
private ICoffeeMachine coffeeMachine;
public Man(ICoffeeMachine coffeeMachine) {
this.coffeeMachine = coffeeMachine;
}
/**
* 制作咖啡
*/
public void makeCoffee() {
coffeeMachine.work();
}
}
/**
* 客户端
*/
public class Client {
public static void main(String[] args) {
ICoffeeMachine coffeeMachine = new CoffeeMachine();
IMan man = new Man(coffeeMachine);
man.makeCoffee();
}
}这样修改后,通过减少CoffeeMachine对外暴露的方法,减少Man对CoffeeMachine的了解,从而降低了它们之间的耦合。
注意事项
第一:在类的划分上,应当创建弱耦合的类,类与类之间的耦合越弱,就越有利于实现可复用的目标。
第二:在类的结构设计上,每个类都应该降低成员的访问权限。
第三:在类的设计上,只要有可能,一个类应当设计成不变的类。
第四:在对其他类的引用上,一个对象对其他类的对象的引用应该降到最低。
第五:尽量限制局部变量的有效范围,降低类的访问权限。
参考链接
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 george_95@126.com