系统环境
RockyLinux:9.3
K8s版本:1.29
Docker版本:27.4.1
1、Pod生命周期概述
Pod 的生命周期如下图:
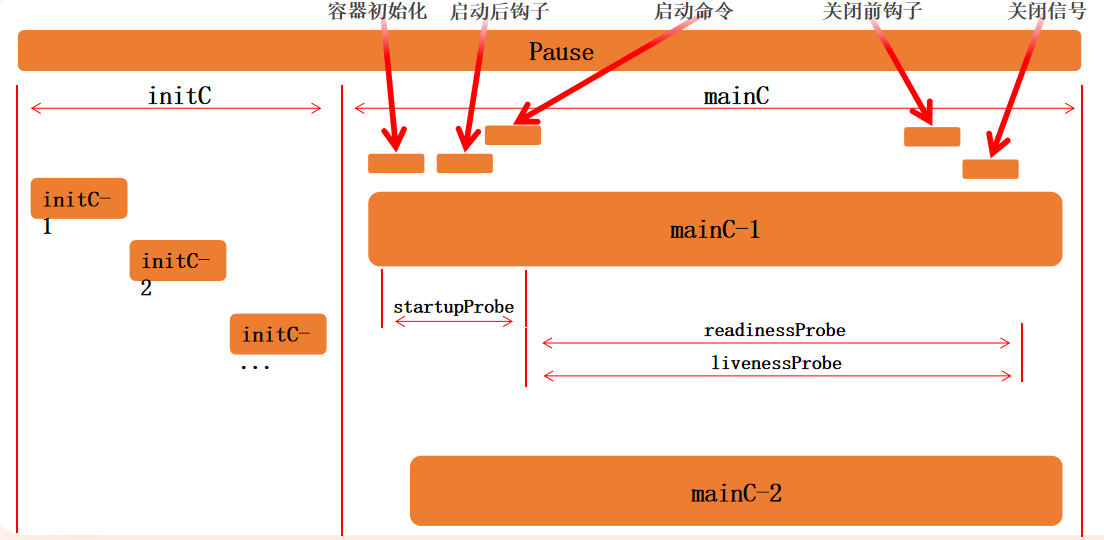
2、initC
2.1 initC概述
init 容器与普通的容器非常像,除了如下三点:
- init 容器总是运行到成功完成为止
- 每个 init 容器都必须在下一个 init 容器启动之前成功完成
- initC 无法定义 readinessProbe,其它以外同应用容器定义无异
如果 Pod 的 Init 容器失败,Kubernetes 会不断地重启该 Pod,直到 Init 容器成功为止。然而,如果 Pod 对应的 restartPolicy 为 Never,它不会重新启动
在主容器 [mainC] 启动前,可以定义 initC 作为前置容器,用于检测主容器所需要的环境是否已准备完成(当然initC的定义不是必须的)。当在配置中定义了 initC ,则必须所有的initC都启动完成后,mainC 才能启动,否则 mainC 会一直处于阻塞中。
另外 initC 会按照 yaml文件中定义的顺序启动,只有当第一个 initC 容器启动完成后,第二个 initC 才能启动,否则第二个 initC 也会处于阻塞中。
下面是 initC 阻塞性检测的示例:
2.2 pod yaml文件
2.2.1 yaml文件内容
001-initC.yaml
apiVersion: v1 # API版本
kind: Pod # 资源类型
metadata:
name: init-1 # Pod名称
labels: # 标签
app: initc
spec: # Pod 期望
containers: # 容器定义
- name: myapp-container # 容器名
image: gcr.io/google-containers/busybox:1.27 # 该容器使用的镜像
command: ['sh', '-c', 'echo The app is running! && sleep 3600']
initContainers: # 初始化容器全部成功后,myapp-container容器才能启动成功
- name: init-myservice # 第一个初始化容器,等待 myservice 的 DNS 解析成功。
image: gcr.io/google-containers/busybox:1.27
command:
- 'sh'
- '-c'
- 'until nslookup myservice; do echo waiting for myservice; sleep 2; done;'
- name: init-mydb # 第二个初始化容器,等待 mydb 的 DNS 解析成功。 然后才会启动主容器 myapp-container。
image: gcr.io/google-containers/busybox:1.27
command: ['sh', '-c', 'until nslookup mydb; do echo waiting for mydb; sleep 2; done;']2.2.2 pod yaml文件解析
containers: # 容器定义
- name: myapp-container # 容器名
image: gcr.io/google-containers/busybox:1.27 # 该容器使用的镜像
command: ['sh', '-c', 'echo The app is running! && sleep 3600']主容器 myapp-container 启动成功后会打印内容:The app is running! ,并且 sleep 3600 秒
- name: init-myservice # 第一个初始化容器,等待 myservice 的 DNS 解析成功。
image: gcr.io/google-containers/busybox:1.27
command:
- 'sh'
- '-c'
- 'until nslookup myservice; do echo waiting for myservice; sleep 2; done;'第一个初始化容器:init-myservice 启动时会解析 DNS 域名:myservice, 解析成功则该初始化容器成功启动,解析失败则打印日志:waiting for myservice, 然后 sleep 2秒后,继续解析,直到成功为止。
- name: init-mydb # 第二个初始化容器,等待 mydb 的 DNS 解析成功。 然后才会启动主容器 myapp-container。
image: gcr.io/google-containers/busybox:1.27
command: ['sh', '-c', 'until nslookup mydb; do echo waiting for mydb; sleep 2; done;']第一个初始化容器:init-mydb 启动时会解析 DNS 域名:mydb, 解析成功则该初始化容器成功启动,解析失败则打印日志:waiting for mydb, 然后 sleep 2秒后,继续解析,直到成功为止。
2.3 启动Pod测试
2.3.1 启动pod
kubectl apply -f /opt/k8s/04/001-initC.yaml此时观察Pod 启动情况
[root@k8s-master01 ~]$ kubectl get pods
NAME READY STATUS RESTARTS AGE
init-1 0/1 Init:0/2 0 2m42s
或者动态监控
[root@k8s-master01 ~]$ kubectl get pods -o wide -w
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
init-1 0/1 Init:0/2 0 3m6s 192.168.85.193 k8s-node01 <none> <none>此时可以看到 主容器未启动,且初始化容器未启动。
2.3.2 查看初始化容器日志
[root@k8s-master01 ~]$ kubectl logs -f --tail=100 init-1 -c init-myservice
nslookup: can't resolve 'myservice'
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
waiting for myservice
nslookup: can't resolve 'myservice'
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.localinit-myservice DNS未能解析名为 myservice 的服务,而此时初始化容器 init-mydb 还未启动。
[root@k8s-master01 ~]$ kubectl logs -f --tail=100 init-1 -c init-mydb
Error from server (BadRequest): container "init-mydb" in pod "init-1" is waiting to start: PodInitializing2.3.3 创建Service:myservice
kubectl create svc clusterip myservice --tcp=80:80创建Service,名为 myservice,在k8s中默认名称即为域名,这样在集群中就有了一个域名为:myservice 的服务了。
此时再观察 Pod 的启动情况:
[root@k8s-master01 ~]$ kubectl get pods
NAME READY STATUS RESTARTS AGE
init-1 0/1 Init:1/2 0 13m初始化容器1已启动。
2.3.4 观察初始化容器2:init-mydb
[root@k8s-master01 ~]$ kubectl logs -f --tail=100 init-1 -c init-mydb
Server: 10.96.0.10
nslookup: can't resolve 'mydb'
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
waiting for mydb
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.localinit-mydb 容器未启动,因为无法解析域名:mydb,此时主容器 myapp-container 未启动,需要等待初始化容器都启动成功后才能启动主容器。
2.3.5 创建Service:mydb
kubectl create svc clusterip mydb --tcp=80:80此时再观察Pod启动情况
[root@k8s-master01 ~]$ kubectl get pods -o wide -w
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
init-1 1/1 Running 0 18m 192.168.85.193 k8s-node01 <none> <none>初始化容器启动完成,主容器启动完成。
2.3.6 查看容器启动日志
[root@k8s-master01 ~]$ kubectl logs -f --tail=100 init-1 -c myapp-container
The app is running!结论:
- 初始化容器必须全部启动完成后,主容器才能启动
- 初始化容器启动是有顺序的
3、探针
3.1 探针概述
探针是由 kubelet 对容器执行的定期诊断。要执行诊断,kubelet 调用由容器实现的 Handler。有三种类型的处理程序:
ExecAction:在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功TCPSocketAction:对指定端口上的容器的 IP 地址进行 TCP 检查。如果端口打开,则诊断被认为是成功的HTTPGetAction:对指定的端口和路径上的容器的 IP 地址执行 HTTP Get 请求。如果响应的状态码大于等于200 且小于 400,则诊断被认为是成功的
每次探测都将获得以下三种结果之一:
- 成功:容器通过了诊断。
- 失败:容器未通过诊断。
- 未知:诊断失败,因此不会采取任何行动
3.2 探针分类
startupProbe:启动探测,用于检测容器是否已启动livenessProbe:存活探测,用于检测容器是否还存活readinessProbe:就绪探测,检查容器是否已就绪,可以对外提供服务了。
4、readinessProbe 就绪探针
介绍:k8s 通过添加就绪探针,解决尤其是在扩容时保证提供给用户的服务都是可用的。
4.1 选项说明
initialDelaySeconds:容器启动后要等待多少秒后就探针开始工作,单位“秒”,默认是 0 秒,最小值是 0periodSeconds:执行探测的时间间隔(单位是秒),默认为 10s,单位“秒”,最小值是 1timeoutSeconds:探针执行检测请求后,等待响应的超时时间,默认为 1s,单位“秒”,最小值是 1successThreshold:探针检测失败后认为成功的最小连接成功次数,默认值为 1。必须为 1 才能激活和启动。最小值为1failureThreshold:探测失败的重试次数,重试一定次数后将认为失败,默认值为 3 ,最小值为 1。
4.2 案例:基于HTTP Get 方式
002-readiness-http.yaml
apiVersion: v1
kind: Pod
metadata:
name: readiness-httpget-pod # pod 名
namespace: default # 名称空间
labels: # 定义多个标签
app: myapp
env: test
spec:
containers: # 定义主容器
- name: readiness-httpget-container
image: wangyanglinux/myapp:v1.0
imagePullPolicy: IfNotPresent # 镜像拉取策略,如果存在则不拉取
readinessProbe: # 定义就绪探测
httpGet: # http请求
port: 80 # 请求端口
path: /index1.html # 访问资源地址
initialDelaySeconds: 1 # 容器启动后要等待多少秒后就探针开始工作,单位“秒”,默认是 0 秒,最小值是 0
periodSeconds: 30 # 执行探测的时间间隔(单位是秒),默认为 10s,单位“秒”,最小值是 1
timeoutSeconds: 1 # 探针执行检测请求后,等待响应的超时时间,默认为 1s,单位“秒”,最小值是 1
successThreshold: 1 # 探针检测失败后认为成功的最小连接成功次数,默认值为 1。必须为 1 才能激活和启动。最小值为1
failureThreshold: 10 # 探测失败的重试次数,重试一定次数后将认为失败,默认值为 3 ,最小值为 1创建Pod
创建Pod
kubectl apply -f /opt/k8s/04/002-readiness-http.yaml
查看Pod运行情况
[root@k8s-master01 /opt/k8s/04]$ kubectl get pods
NAME READY STATUS RESTARTS AGE
readiness-httpget-pod 0/1 Running 0 8sPod已启动,但是未就绪,下面查看日志,直到Pod未就绪的原因
查看Pod日志
查看Pod日志
kubectl logs -f readiness-httpget-pod
日志内容如下
192.168.142.202 - - [22/Mar/2025:23:59:58 +0800] "GET /index1.html HTTP/1.1" 404 153 "-" "kube-probe/1.29"
2025/03/22 23:59:58 [error] 7#7: *1 open() "/usr/local/nginx/html/index1.html" failed (2: No such file or directory), client: 192.168.142.202, server: localhost, request: "GET /index1.html HTTP/1.1", host: "192.168.58.196:80"可以发现Pod在做就绪检测,访问 http://192.168.58.196:80/index1.html 结果404,就绪检测未通过,因此Pod处于未就绪状态。
进入Pod内容,创建资源文件,让Pod就绪检测通过
进入Pod容器内部
[root@k8s-master01 /opt/k8s/04]$ kubectl exec -it readiness-httpget-pod /bin/bash
创建资源文件
readiness-httpget-pod:/# cd /usr/local/nginx/html/
readiness-httpget-pod:/usr/local/nginx/html# ls
50x.html hostname.html index.html
readiness-httpget-pod:/usr/local/nginx/html# cp index.html index1.html
readiness-httpget-pod:/usr/local/nginx/html# exit
exit
再次查看Pod运行状态,Pod已处于就绪状态
[root@k8s-master01 /opt/k8s/04]$ kubectl get pods
NAME READY STATUS RESTARTS AGE
readiness-httpget-pod 1/1 Running 0 95s4.3 案例:基于EXEC方式
就绪检测在容器从启动到关闭的整个周期内都是有效的,例如容器刚启动时,就绪检测通过了,
003-readiness-exec.yaml
apiVersion: v1
kind: Pod
metadata:
name: readiness-exec-pod
namespace: default
labels:
app: myapp
env: test
spec:
containers:
- name: readiness-exec-container
image: wangyanglinux/myapp:v1.0
imagePullPolicy: IfNotPresent # 镜像拉取策略,如果存在则不拉取
# 主容器启动成功后自动创建目录 /tmp/live, 60秒后删除该目录,
command: ['/bin/sh', '-c', 'touch /tmp/live; sleep 60; rm -rf /tmp/live; sleep 3600']
readinessProbe:
exec:
command:
- 'test'
- '-e'
- '/tmp/live'
initialDelaySeconds: 2 # 容器启动后要等待多少秒后就探针开始工作,单位“秒”,默认是 0 秒,最小值是 0
periodSeconds: 3 # 执行探测的时间间隔(单位是秒),默认为 10s,单位“秒”,最小值是 1启动Pod
启动Pod
kubectl apply -f 003-readiness-exec.yaml
查看Pod运行状态
[root@k8s-master01 /opt/k8s/04]$ kubectl get pods
NAME READY STATUS RESTARTS AGE
readiness-exec-pod 1/1 Running 0 5s由于主容器 readiness-exec-container 在启动成功后创建目录 /tmp/live ,因此 exec 就绪检测在容器刚启动时会通过。但在容器启动60秒后会删除目录 /tmp/live,由于就绪检测会持续不断的进行,因此此时就绪检测会失败。
再次查看Pod运行状态
[root@k8s-master01 /opt/k8s/04]$ kubectl get pods
NAME READY STATUS RESTARTS AGE
readiness-exec-pod 0/1 Running 0 15mPod此时处于未就绪状态
4.4 案例:基于 TCP Check 方式
004-readiness-tcp.yaml
apiVersion: v1
kind: Pod
metadata:
namespace: default
name: readiness-tcp-pod
spec:
containers:
- name: readiness-exec-container
image: wangyanglinux/myapp:v1.0
imagePullPolicy: IfNotPresent
readinessProbe: # 定义就绪检测
initialDelaySeconds: 3
timeoutSeconds: 1
tcpSocket: # 探测 tcp 端口
port: 80启动Pod
启动Pod
kubectl apply -f 004-readiness-tcp.yaml
查看Pod运行状态
[root@k8s-master01 /opt/k8s/04]$ kubectl get pods
NAME READY STATUS RESTARTS AGE
readiness-tcp-pod 1/1 Running 0 10s5、livenessProbe 存活探针
介绍:k8s 通过添加存活探针,解决虽然活着但是已经死了的问题。
5.1 选项说明:
initialDelaySeconds:容器启动后要等待多少秒后就探针开始工作,单位“秒”,默认是 0 秒,最小值是 0periodSeconds:执行探测的时间间隔(单位是秒),默认为 10s,单位“秒”,最小值是 1timeoutSeconds:探针执行检测请求后,等待响应的超时时间,默认为 1s,单位“秒”,最小值是 1successThreshold:探针检测失败后认为成功的最小连接成功次数,默认值为 1。必须为 1 才能激活和启动。最小值为1failureThreshold:探测失败的重试次数,重试一定次数后将认为失败,默认值为 3 ,最小值为 1。
5.2 案例:基于 HTTP Get 方式
005-liveness-httpget.yaml
apiVersion: v1
kind: Pod
metadata:
name: liveness-httpget-pod
namespace: default
labels:
app: myapp
spec:
containers:
- name: liveness-httpget-container
image: wangyanglinux/myapp:v1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80 # 指定容器暴露的端口,这里是 80 端口(通常用于 HTTP 服务)
name: http # 为这个端口命名,方便引用(例如在 Service 中)。
livenessProbe: # 定义存活探针(Liveness Probe),用于检查容器是否健康。如果探针失败,Kubernetes 会重启容器。
initialDelaySeconds: 2 # 容器启动后,探针延迟 2 秒开始首次检查。这给应用留出启动时间。
periodSeconds: 3 # 探针检查的频率,每 3 秒执行一次。
successThreshold: 1 # 探针成功的次数阈值,设置为 1 表示一次成功即认为容器健康。
failureThreshold: 3 # 探针失败的次数阈值,设置为 3 表示连续 3 次失败后,Kubernetes 会重启容器。
httpGet: # 定义探针类型为 HTTP GET 请求。
port: 80 # 请求的目标端口,这里是容器的 80 端口。
path: /index1.html # 请求的路径,探针会访问 http://<容器IP>:80/index1.html。如果返回状态码 200-399,则认为容器健康。启动Pod
启动Pod
kubectl apply -f 005-liveness-httpget.yaml
查看Pod运行状态
[root@k8s-master01 /opt/k8s/04]$ kubectl get pods -o wide -w
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
liveness-httpget-pod 1/1 Running 5 (65s ago) 100s 192.168.85.198 k8s-node01 <none> <none>
liveness-httpget-pod 0/1 CrashLoopBackOff 5 (23s ago) 109s 192.168.85.198 k8s-node01 <none> <none>
liveness-httpget-pod 1/1 Running 6 (113s ago) 3m19s 192.168.85.198 k8s-node01 <none> <none>
liveness-httpget-pod 0/1 CrashLoopBackOff 6 (23s ago) 3m28s 192.168.85.198 k8s-node01 <none> <none>Pod由最开始的 Running 状态,然后容器启动2秒后存活探针开始工作,检测 http://<容器IP>:80/index1.html 资源不存在,于是间隔 periodSeconds 时长再次检测,连续失败 failureThreshold 次,容器重启。循环这个操作。
5.3 案例:基于 Exec 方式
006-liveness-exec.yaml
apiVersion: v1
kind: Pod
metadata:
name: readiness-exec-pod
namespace: default
labels:
app: myapp
env: test
spec:
containers:
- name: readiness-exec-container
image: wangyanglinux/myapp:v1.0
imagePullPolicy: IfNotPresent # 镜像拉取策略,如果存在则不拉取
# 主容器启动成功后自动创建目录 /tmp/live, 60秒后删除该目录,
command: ['/bin/sh', '-c', 'touch /tmp/live; sleep 30; rm -rf /tmp/live; sleep 3600']
livenessProbe:
exec:
command:
- 'test'
- '-e'
- '/tmp/live'
initialDelaySeconds: 2
periodSeconds: 3启动Pod,查看运行状态
启动Pod
kubectl apply -f 006-liveness-exec.yaml
监控Pod运行状态
[root@k8s-master01 /opt/k8s/04]$ kubectl get pods -o wide -w
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
readiness-exec-pod 1/1 Running 0 12s 192.168.85.199 k8s-node01 <none> <none>
readiness-exec-pod 1/1 Running 1 (23s ago) 71s 192.168.85.199 k8s-node01 <none> <none>Pod刚启动时,会自动创建目录 /tmp/live, initialDelaySeconds 秒后开始存活探测,此时Pod的存活探测是通过的。30秒后容器把目录 /tmp/live 删掉了,由于存活探测是持续轮询执行的,这时的存活探测就是失败的,当连续3次(默认failureThreshold是3)的探测失败后,容器会重启。
5.4 案例:基于 TCP Check 方式
007-liveness-tcp.yaml
apiVersion: v1
kind: Pod
metadata:
namespace: default
name: readiness-tcp-pod
spec:
containers:
- name: readiness-exec-container
image: wangyanglinux/myapp:v1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
name: http
livenessProbe:
initialDelaySeconds: 2
timeoutSeconds: 1
tcpSocket:
port: 80启动Pod,查看状态
启动Pod
kubectl apply -f 007-liveness-tcp.yaml
查看Pod的运行状态
[root@k8s-master01 /opt/k8s/04]$ kubectl get pods -o wide -w
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
readiness-tcp-pod 1/1 Running 0 14s 192.168.85.200 k8s-node01 <none> <none>6、startupProbe 启动探针
介绍:k8s 在 1.16 版本后增加 startupProbe 探针,主要解决在复杂的程序中 readinessProbe、livenessProbe 探针无法更好的判断程序是否启动、是否存活。
6.1 选项说明
- initialDelaySeconds:容器启动后要等待多少秒后就探针开始工作,单位“秒”,默认是 0 秒,最小值是 0
- periodSeconds:执行探测的时间间隔(单位是秒),默认为 10s,单位“秒”,最小值是 1
- timeoutSeconds:探针执行检测请求后,等待响应的超时时间,默认为 1s,单位“秒”,最小值是 1
- successThreshold:探针检测失败后认为成功的最小连接成功次数,默认值为 1。必须为 1 才能激活和启动。最小值为1
- failureThreshold:探测失败的重试次数,重试一定次数后将认为失败,默认值为 3 ,最小值为 1。
6.2 案例:基于 HTTP Get 方式
008-startup-probe.yaml
apiVersion: v1
kind: Pod
metadata:
name: startup-probe-pod
namespace: default
spec:
containers:
- name: startup-probe-container
image: wangyanglinux/myapp:v1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
name: http
startupProbe: # 定义启动探针
initialDelaySeconds: 0
successThreshold: 1
failureThreshold: 30
periodSeconds: 10
httpGet:
port: 80
path: /index1.html启动Pod
启动Pod
kubectl apply -f 008-startup-probe.yaml
监控Pod运行状态
[root@k8s-master01 ~]$ kubectl get pods -o wide -w
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
startup-probe-pod 0/1 Running 0 97s 192.168.85.201 k8s-node01 <none> <none>由于容器内没有 index1.html 资源,启动探测失败,因此Pod处于未就绪状态。
进入容器,创建 index1.html
进入容器
[root@k8s-master01 /opt/k8s/04]$ kubectl exec -it startup-probe-pod /bin/bash
startup-probe-pod:/# cd /usr/local/nginx/html/
startup-probe-pod:/usr/local/nginx/html# ls
50x.html hostname.html index.html
创建 index1.html
startup-probe-pod:/usr/local/nginx/html# cp index.html index1.html再次查看Pod运行状态
[root@k8s-master01 ~]$ kubectl get pods -o wide -w
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
startup-probe-pod 0/1 Running 0 97s 192.168.85.201 k8s-node01 <none> <none>
startup-probe-pod 1/1 Running 0 111s 192.168.85.201 k8s-node01 <none> <none>
此时Pod变成已就绪状态。由于 008-startup-probe.yaml 文件中没有定义就绪检测,因此启动探测成功后,默认就绪检测成功。
注意:应用程序将会有最多 5 分钟 failureThreshold * periodSeconds(30 * 10 = 300s)的时间来完成其启动过程。
6.3 案例:基于EXEC方式
009-startup-exec.yaml
apiVersion: v1
kind: Pod
metadata:
name: startup-exec-pod
namespace: default
labels:
app: myapp
env: test
spec:
containers:
- name: startup-exec-container
image: wangyanglinux/myapp:v1.0
imagePullPolicy: IfNotPresent # 镜像拉取策略,如果存在则不拉取
# 主容器启动成功后自动创建目录 /tmp/live, 3秒后删除该目录,
command: ['/bin/sh', '-c', 'touch /tmp/live; sleep 3; rm -rf /tmp/live; sleep 3600']
startupProbe:
exec:
command:
- 'test'
- '-e'
- '/tmp/live'
initialDelaySeconds: 4 # 延迟4秒后启动探测,此时 /tmp/live 文件夹已被删除
periodSeconds: 3启动Pod,查看状态
启动Pod
kubectl apply -f 009-startup-exec.yaml
查看Pod运行状态
[root@k8s-master01 ~]$ kubectl get pods -o wide -w
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
startup-exec-pod 0/1 Running 0 6s 192.168.85.203 k8s-node01 <none> <none>
startup-exec-pod 0/1 Running 1 (22s ago) 43s 192.168.85.203 k8s-node01 <none> <none>启动探测失败,Pod未就绪。
7、钩子
7.1 钩子概述
Pod hook(钩子)是由 Kubernetes 管理的 kubelet 发起的,当容器中的**进程启动前(其实是启动后,对应:postStart)或者容器中的进程终止之前(对应:preStop)*运行,这是包含在容器的生命周期之中。可以同时为 Pod 中的所有容器都配置 hook*
Hook 的类型包括两种:
exec:执行一段命令HTTP:发送 HTTP 请求
7.2 案例:基于 Exec 方式
010-hook-exec.yaml
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-exec-pod
namespace: default
labels:
app: myapp
spec:
containers:
- name: lifecycle-exec-container
image: wangyanglinux/myapp:v1
lifecycle:
postStart: # 启动后钩子
exec:
command:
- '/bin/sh'
- '-c'
- 'echo postStart > /usr/share/message'
preStop: # 关闭前钩子
exec:
command: ["/bin/sh", "-c", "echo preStop > /usr/share/message"]启动Pod
启动Pod
kubectl apply -f 010-hook-exec.yaml
查看Pod运行情况
[root@k8s-master01 /opt/k8s/04]$ kubectl get pods -o wide -w
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
lifecycle-exec-pod 0/1 ContainerCreating 0 4s <none> k8s-node02 <none> <none>
lifecycle-exec-pod 0/1 ContainerCreating 0 9s <none> k8s-node02 <none> <none>
lifecycle-exec-pod 1/1 Running 0 16s 172.16.58.195 k8s-node02 <none> <none>Pod已成功启动,并就绪
测试启动后钩子是否生效
进入Pod
kubectl exec -it lifecycle-exec-pod /bin/bash
在容器内查看启动后钩子执行的脚本是否生效
lifecycle-exec-pod:/# cat /usr/share/message
postStart可以发现 “postStart” 已被写入文件中
测试关闭前钩子是否生效
1.进入Pod容器中
kubectl exec -it lifecycle-exec-pod /bin/bash
2.在容器内写一段脚本持续读取输出 /usr/share/message
脚本内容如下:
!/bin/bash
无限循环执行 cat /usr/share/message
while true; do
cat /usr/share/message
done
3.给脚本授权(容器内操作)
chmod +x 123.sh
4.执行脚本(容器内操作)
sh 123.sh
5.新起一个shell终端,执行关闭Pod操作
kubectl delete -f 010-hook-exec.yaml
6.查看脚本打印内容
......
preStop
preStop
preStop
......可以看到关闭前钩子在容器被杀死前,执行了 echo preStop > /usr/share/message
7.3 案例:基于HTTP Get请求
测试容器
开启一个测试 webServer
docker run -itd --rm -p 1234:80 --name=test wangyanglinux/myapp:v1.0
监控测试容器的日志打印情况
docker logs -f --tail 1000 test011-hook-http.yaml
apiVersion: v1
kind: Pod
metadata:
namespace: default
name: lifecycle-http-pod
labels:
app: myApp
spec:
containers:
- name: lifecycle-httpget-container
image: wangyanglinux/myapp:v1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
lifecycle:
postStart: # 启动后钩子
httpGet: # 基于Http Get 请求方式
port: 1234 # http 访问端口
host: 192.168.6.139 # http访问Host地址
path: index.html # http访问资源路径
preStop:
httpGet:
port: 1234
host: 192.168.6.139
path: hostname.html启动Pod
启动Pod
kubectl apply -f 011-hook-http.yaml
查看测试容器的日志
[root@k8s-master01 /opt/k8s/04]$ docker logs -f --tail 1000 test
192.168.6.141 - - [02/Apr/2025:10:26:16 +0800] "GET /index.html HTTP/1.1" 200 48 "-" "kube-lifecycle/1.29"pod启动成功,并执行了 postStart 定义的Http Get请求,访问了 http://192.168.6.139:1234/index.html
停止Pod
删除Pod
kubectl delete -f 011-hook-http.yaml
查看测试容器的日志
[root@k8s-master01 /opt/k8s/04]$ docker logs -f --tail 1000 test
192.168.6.141 - - [02/Apr/2025:10:26:16 +0800] "GET /index.html HTTP/1.1" 200 48 "-" "kube-lifecycle/1.29"
192.168.6.141 - - [02/Apr/2025:10:28:44 +0800] "GET /hostname.html HTTP/1.1" 200 13 "-" "kube-lifecycle/1.29"Pod在关闭前,执行了 preStop 定义的Http Get 请求,访问了 http://192.168.6.139:1234/hostname.html
7.4 关于 preStop 的延伸
在 k8s 中,理想的状态是 pod 优雅释放,但是并不是每一个 Pod 都会这么顺利
- Pod 卡死,处理不了优雅退出的命令或者操作
- 优雅退出的逻辑有 BUG,陷入死循环
- 代码问题,导致执行的命令没有效果
对于以上问题,k8s 的 Pod 终止流程中还有一个 “最多可以容忍的时间”,即 grace period ( 在 pod.spec.terminationGracePeriodSeconds 字段定义),这个值默认是 30 秒,当我们执行 kubectl delete 的时候也可以通过 --grace-period 参数显示指定一个优雅退出时间来覆盖 Pod 中的配置,如果我们配置的 grace period 超过时间之后,k8s 就只能选择强制 kill Pod。值得注意的是,这与preStop Hook和 SIGTERM 信号并行发生。k8s 不会等待 preStop Hook 完成。如果你的应用程序完成关闭并在terminationGracePeriod 完成之前退出,k8s 会立即进入下一步
apiVersion: v1
kind: Pod
metadata:
namespace: default
name: lifecycle-http-pod
labels:
app: myApp
spec:
containers:
- name: lifecycle-httpget-container
image: wangyanglinux/myapp:v1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
lifecycle:
postStart: # 启动后钩子
httpGet: # 基于Http Get 请求方式
port: 1234 # http 访问端口
host: 192.168.6.139 # http访问Host地址
path: index.html # http访问资源路径
preStop:
httpGet:
port: 1234
host: 192.168.6.139
path: hostname.html
terminationGracePeriodSeconds: 30 # 如果执行 kubectl delete 不能顺利将pod关闭,最长30秒强制杀死pod8、Pod生命周期完整演示
012-lifecycle-all.yaml
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-pod
namespace: default
labels:
app: myapp
spec:
containers:
- name: busybox-container # 主容器1
image: wangyanglinux/tools:busybox
imagePullPolicy: IfNotPresent
command: ["/bin/sh","-c","touch /tmp/live ; sleep 600; rm -rf /tmp/live; sleep 3600"]
livenessProbe: # 主容器1存活探针
exec: # 基于 exec执行命令,探测主容器内文件是否存在
command: ["test","-e","/tmp/live"]
initialDelaySeconds: 1 # 容器启动1秒后探测
periodSeconds: 3 # 循环3秒
lifecycle:
postStart:
httpGet:
port: 1234
host: 192.168.6.139
path: index.html
preStop:
httpGet:
port: 1234
host: 192.168.6.139
path: hostname.html
- name: myapp-container
image: wangyanglinux/myapp:v1.0
imagePullPolicy: IfNotPresent
livenessProbe:
httpGet:
port: 80
path: /index.html
initialDelaySeconds: 1
periodSeconds: 3
timeoutSeconds: 3 # http Get 请求超时时间(秒)
readinessProbe:
httpGet:
port: 80
path: /index1.html
initialDelaySeconds: 1
periodSeconds: 3
timeoutSeconds: 3
initContainers:
- name: init-myservice
image: wangyanglinux/tools:busybox
imagePullPolicy: IfNotPresent
command: ['sh', '-c', 'until nslookup myservice; do echo waiting for myservice; sleep 2; done;']
- name: init-mydb
image: wangyanglinux/tools:busybox
command: ['sh', '-c', 'until nslookup mydb; do echo waiting for mydb; sleep 2; done;']启动Pod
启动Pod
kubectl apply -f 012-lifecycle-all.yaml
查看Pod日志
kubectl logs -f --tail=100 lifecycle-pod
查看initC日志
kubectl logs -f --tail=100 lifecycle-pod -c init-myservice
kubectl logs -f --tail=100 lifecycle-pod -c init-mydb
创建initC需要的service
kubectl create svc clusterip myservice --tcp=80:80
kubectl logs -f --tail=100 lifecycle-pod -c init-myservice
kubectl logs -f --tail=100 lifecycle-pod -c init-mydb
kubectl create svc clusterip mydb --tcp=80:80
进入主容器
kubectl exec -it lifecycle-pod -c myapp-container /bin/bash
创建主容器就绪检测所需资源
cd /usr/local/nginx/html/
cp index.html index1.html完成以上操作后,此Pod才能真正完整运行起来。
Pod运行监控
kubectl get pod -o wide -w
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
lifecycle-pod 0/2 Init:0/2 0 43s 172.16.58.197 k8s-node02 <none> <none>
lifecycle-pod 0/2 Init:1/2 0 3m21s 172.16.58.197 k8s-node02 <none> <none>
lifecycle-pod 0/2 Init:1/2 0 3m26s 172.16.58.197 k8s-node02 <none> <none>
lifecycle-pod 0/2 PodInitializing 0 4m7s 172.16.58.197 k8s-node02 <none> <none>
lifecycle-pod 1/2 Running 0 4m17s 172.16.58.197 k8s-node02 <none> <none>
lifecycle-pod 2/2 Running 0 5m45s 172.16.58.197 k8s-node02 <none> <none>转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 george_95@126.com