集群环境
| IP | Hostname | 用途 |
|---|---|---|
| 10.20.1.139 | k8s-master01 | Master节点 |
| 10.20.1.140 | k8s-node01 | Node节点 |
| 10.20.1.141 | k8s-node02 | Node节点 |
| 10.20.1.142 | k8s-node03 | Node节点 |
一、配置容器级别的安全控制
1. 共享主机网络
通常情况下,Pod中的容器会使用 Kubernetes 网络插件提供的网络,这些插件确保了 Pod 之间的网络通信。然而,有时候可能需要 Pod 直接使用主机(节点)的网络,直接使用主机的IP地址和端口,可以通过在 Pod 的配置中设置 hostNetwork: true 来实现。
直接使用主机网络可以减少网络转发的开销,提高网络性能,但同时也需要注意Pod直接使用主机端口可能会存在部分冲突。
1.1 案例
资源清单:host-network.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
nodeName: k8s-master01 # 选择 Pod 运行的节点的名字
hostNetwork: true # 主机共享网络
containers:
- name: nginx
image: nginx:1.29.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80执行资源清单
# 执行资源清单
$ kubectl apply -f host-network.yaml
# 查看Pod详情
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-76985c7d59-pzlpk 1/1 Running 0 11s 10.20.1.139 k8s-master01 <none> <none>
# 使用物理机IP访问Nginx
$ curl http://10.20.1.139:80
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
</head>
<body>
<h1>Welcome to nginx!</h1>
</body>
</html>1.2 hostNetwork 使用注意事项
Pod 直接使用主机的网络会占用宿主机的端口,Pod 的 IP 就是宿主机的 IP,使用时需要考虑是否与主机上的端口冲突,因此一般情况下除非某个特定应用必须占用宿主机上的特定端口,否则不建议使用主机网络。
由于Pod使用主机网络,访问Pod需要直接通过节点端口,因此要 注意放通节点安全组端口 ,否则会出现访问不通的情况。
另外由于占用主机端口,使用 Deployment 部署 hostNetwork 类型 Pod 时,要注意 Pod的副本数不要超过节点数量 ,否则会导致一个节点上调度了多个Pod,Pod 启动时端口冲突无法创建。例如上面例子中的 nginx,如果服务数为 2,并部署在只有1个节点的集群上,就会有一个Pod无法创建,查询Pod日志会发现是由于端口占用导致 nginx 无法启动。
请避免在同一个节点上调度多个使用主机网络的 Pod,否则在创建 ClusterIP 类型的 Service 访问 Pod 时,会出现访问 ClusterIP 不通的情况。
2. 共享主机端口
在 Kubernetes 中,hostPort 是一种用于将主机上的特定端口映射到运行在 Pod 内部容器的端口的配置选项。通过使用 hostPort,你可以在主机上暴露容器的服务,从而允许外部网络通过主机的 IP 地址和指定的端口访问容器内的应用程序。
2.1 案例
资源清单:host-port.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.29.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
hostPort: 8080 # 主机端口
protocol: TCP执行资源清单
# 执行资源清单,创建Pod
$ kubectl apply -f host-port.yaml
deployment.apps/nginx created
# 查看Pod运行情况
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-585b8dd6d-9tzl6 1/1 Running 0 8s 171.20.85.209 k8s-node01 <none> <none>
# 通过Pod运行节点的物理机IP和映射端口 8080 访问Nginx
$ curl 10.20.1.140:8080
<!DOCTYPE html>
<html>
<body>
<h1>Welcome to nginx!</h1>
</body>
</html>2.2 hostPort 与 NodePort 的区别
hostPort 与 NodePort 的区别是,NodePort 服务默认是把请求转发到随机的一个运行的 Pod 上,而 hostPort 是直接转发到本 Node 上的指定 Pod。
| 特性 | nodePort(Service) | hostPort(Pod) |
|---|---|---|
| 作用范围 | 集群所有节点 | 单个Pod所在节点 |
| 端口范围 | 默认30000-32767(可配置) | 任意可用端口 |
| 安全性 | 推荐生产环境使用 | 存在端口冲突风险 |
| 负载均衡 | 自动负载均衡 | 需手动实现负载均衡 |
2.3 注意事项
一个 Node 只能启动一个 hostPort,所以最初是用于把守护进程集(DaemonSets)部署到每个 Node (确保一个 Node 只有一个 hostPort )。如下图所示,3个 Node 上部署4个带 hostPort 的 Pod,会有一个不成功。
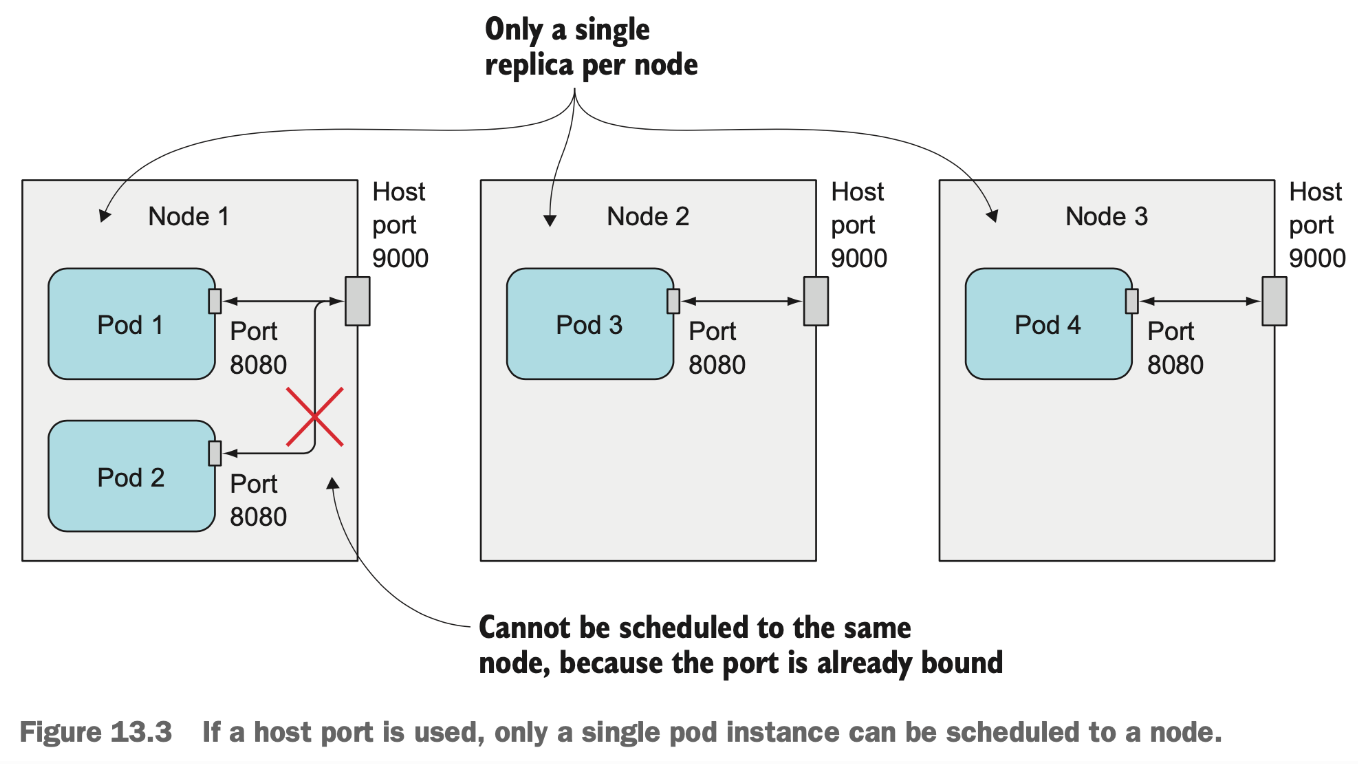
即便是3个 Node 上部署3个带 hostPort 的 Pod 滚动升级时也会有问题,所以使用 hostPort 的服务在升级的时候一定要保障先停掉旧版本的 Pod 实例再启动新版本的 Pod 实例。
3. 共享主机IPC和PID
PID
当 Pod 的 hostPID 设置为 true 时,Pod 内的容器将与宿主机共享相同的 PID 命名空间。这意味着容器可以看到宿主机上运行的所有进程(通过 ps 命令等),并且可以与宿主机的进程进行交互(例如发送信号)。
使用场景:常用于需要监控或管理宿主机进程的场景,例如运行监控代理或安全工具。
IPC
- 当 Pod 的 hostIPC 设置为 true 时,Pod 内的容器将与宿主机共享相同的 IPC(进程间通信)命名空间,允许容器使用宿主机的 IPC 机制。这意味着容器内的进程可以直接访问宿主机的 IPC 资源(例如宿主机的共享内存、消息队列等),也可以与宿主机上的进程或其他共享同一 IPC 命名空间的容器进程进行通信。
3.1 案例
资源清单:host-ipc-pid.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-ipc-pid
spec:
replicas: 1
selector:
matchLabels:
app: nginx-ipc-pid
template:
metadata:
labels:
app: nginx-ipc-pid
spec:
hostIPC: true # 主机共享 IPC 命名空间
hostPID: true # 主机共享 PID 命名空间
containers:
- name: nginx
image: nginx:1.29.0
imagePullPolicy: IfNotPresent执行资源清单
# 执行资源清单,创建Deployment
$ kubectl apply -f host-ipc-pid.yaml
# 查看Pod运行详情
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-ipc-pid-d9f877dbd-hq2vp 1/1 Running 0 14s 171.20.85.210 k8s-node01 <none> <none>
# 进入容器
$ kubectl exec -it nginx-ipc-pid-d9f877dbd-hq2vp -- /bin/bash
# 在容器内查看进程,可以看到,把系统进程也一并打印出来了
root@nginx-ipc-pid-d9f877dbd-hq2vp:/# ls -l /proc/
total 0
drwxrwxrwt 2 root root 40 Sep 6 02:19 acpi
-r--r--r-- 1 root root 0 Sep 6 02:38 bootconfig
-r--r--r-- 1 root root 0 Sep 6 02:38 buddyinfo
dr-xr-xr-x 4 root root 0 Sep 6 02:19 bus
-r--r--r-- 1 root root 0 Sep 6 02:38 cgroups
-r--r--r-- 1 root root 0 Sep 6 02:38 cmdline
-r--r--r-- 1 root root 0 Sep 6 02:38 consoles
-r--r--r-- 1 root root 0 Sep 6 02:38 cpuinfo
-r--r--r-- 1 root root 0 Sep 6 02:38 crypto
-r--r--r-- 1 root root 0 Sep 6 02:38 devices
-r--r--r-- 1 root root 0 Sep 6 02:38 diskstats
-r--r--r-- 1 root root 0 Sep 6 02:38 dma
dr-xr-xr-x 4 root root 0 Sep 6 02:38 driver
dr-xr-xr-x 3 root root 0 Sep 6 02:38 dynamic_debug
-r--r--r-- 1 root root 0 Sep 6 02:38 execdomains
-r--r--r-- 1 root root 0 Sep 6 02:38 fb
-r--r--r-- 1 root root 0 Sep 6 02:19 filesystems
dr-xr-xr-x 4 root root 0 Sep 6 02:19 fs
-r--r--r-- 1 root root 0 Sep 6 02:38 interrupts
-r--r--r-- 1 root root 0 Sep 6 02:38 iomem
-r--r--r-- 1 root root 0 Sep 6 02:38 ioports
dr-xr-xr-x 35 root root 0 Sep 6 02:19 irq
-r--r--r-- 1 root root 0 Sep 6 02:38 kallsyms
crw-rw-rw- 1 root root 1, 3 Sep 6 02:19 kcore
-r--r--r-- 1 root root 0 Sep 6 02:38 key-users
crw-rw-rw- 1 root root 1, 3 Sep 6 02:19 keys
-r-------- 1 root root 0 Sep 6 02:38 kmsg
-r-------- 1 root root 0 Sep 6 02:38 kpagecgroup
-r-------- 1 root root 0 Sep 6 02:38 kpagecount
-r-------- 1 root root 0 Sep 6 02:38 kpageflags
-r--r--r-- 1 root root 0 Sep 6 02:38 loadavg
-r--r--r-- 1 root root 0 Sep 6 02:38 locks
-r--r--r-- 1 root root 0 Sep 6 02:38 mdstat
-r--r--r-- 1 root root 0 Sep 6 02:38 meminfo
-r--r--r-- 1 root root 0 Sep 6 02:38 misc
-r--r--r-- 1 root root 0 Sep 6 02:38 modules
lrwxrwxrwx 1 root root 11 Sep 6 02:38 mounts -> self/mounts
-rw-r--r-- 1 root root 0 Sep 6 02:38 mtrr
lrwxrwxrwx 1 root root 8 Sep 6 02:19 net -> self/net
-r-------- 1 root root 0 Sep 6 02:38 pagetypeinfo
-r--r--r-- 1 root root 0 Sep 6 02:38 partitions
-r--r--r-- 1 root root 0 Sep 6 02:38 schedstat
drwxrwxrwt 2 root root 40 Sep 6 02:19 scsi
lrwxrwxrwx 1 root root 0 Sep 6 02:19 self -> 3214631
-r-------- 1 root root 0 Sep 6 02:38 slabinfo
-r--r--r-- 1 root root 0 Sep 6 02:38 softirqs
-r--r--r-- 1 root root 0 Sep 6 02:38 stat
-r--r--r-- 1 root root 0 Sep 6 02:38 swaps
dr-xr-xr-x 1 root root 0 Sep 6 02:19 sys
--w------- 1 root root 0 Sep 6 02:19 sysrq-trigger
dr-xr-xr-x 5 root root 0 Sep 6 02:38 sysvipc
lrwxrwxrwx 1 root root 0 Sep 6 02:19 thread-self -> 3214631/task/3214631
crw-rw-rw- 1 root root 1, 3 Sep 6 02:19 timer_list
dr-xr-xr-x 6 root root 0 Sep 6 02:38 tty
-r--r--r-- 1 root root 0 Sep 6 02:38 uptime
-r--r--r-- 1 root root 0 Sep 6 02:38 version
-r-------- 1 root root 0 Sep 6 02:38 vmallocinfo
-r--r--r-- 1 root root 0 Sep 6 02:38 vmstat
-r--r--r-- 1 root root 0 Sep 6 02:38 zoneinfo3.2 Linux Namespace 中的 IPC 是什么 ?
IPC (Inter-Process Communication) Namespace 是 Linux 容器隔离的一种命名空间,用于隔离进程间通信(IPC)资源,包括 System V IPC 和 POSIX IPC。
在 Linux 中,进程间通信机制可以使用不同的 IPC 方法。这些方法包括管道、套接字、消息队列、信号量和共享内存等。这些 IPC 机制可以在系统全局范围内使用,也可以在特定的命名空间内使用。
当一个容器启动时,如果该容器运行在它自己的 IPC Namespace 中,那么将为该容器分配一个独立的 IPC 句柄。这意味着该容器内部的进程和外部的进程将无法相互通信。
IPC Namespace 具有以下两个主要特性:
- 隔离:IPC Namespace 可以将特定容器中的进程隔离并限制进程之间在 IPC 资源上的共享。这样就可以避免其他容器或主机干扰到该容器中的进程,或者该容器中的进程干扰到其他容器或主机。
- 共享:如果多个容器运行在同一个 IPC Namespace 中,它们将共享容器之间的 IPC 资源,这使得在同一 IPC Namespace 中的容器之间通信变得更加容易和高效。
总的来说,IPC Namespace 可以有效地保护容器内的进程,避免不必要的干扰。同时,在多个容器需要通信时,将它们加入同一个 IPC Namespace 可以更好地共享资源,从而实现更好的协作和协同工作。
二、配置pod的安全上下文
针对于container级别的控制
1. 指定运行容器的用户
资源清单:user-id-pod.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: alpine-user-id
spec:
replicas: 1
selector:
matchLabels:
app: alpine-user-id
template:
metadata:
labels:
app: alpine-user-id
spec:
containers:
- name: alpine
image: alpine:3.22.1
imagePullPolicy: IfNotPresent
command: # 容器启动命令
- /bin/sleep
- "3600"
securityContext:
runAsUser: 405 # 运行用户 ID运行资源清单
# 执行资源清单
$ kubectl apply -f user-id-pod.yaml
# 查看Pod
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
alpine-user-id-687f8f598b-dcj8f 1/1 Running 0 5m15s
# 进入容器,查看当前用户ID
$ kubectl exec -it alpine-user-id-687f8f598b-dcj8f -- /bin/sh
/ $ id
uid=405(guest) gid=100(users) groups=100(users)2. 阻止容器以root用户运行
有的应用在容器中设置了运行用户,然后可能会有黑客上传一个以root用户运行的镜像到我们的镜像仓库。然后在容器中利用root用户
的权限,这样是很危险的,所以我们可以禁用容器中的root用户,让他不能以root用户启动容器
2.1 创建一个非 Root 运行的 Nginx 镜像
Dockerfile
FROM nginx:1.29.0
# 修改 Nginx 配置:移除 'user' 指令(避免权限警告),并将默认监听端口改为 8080
RUN sed -i '/^user /d' /etc/nginx/nginx.conf && \
sed -i 's/listen 80;/listen 8080;/' /etc/nginx/conf.d/default.conf
# 创建必要的临时目录和 PID 文件,并调整权限给 nginx 用户
RUN mkdir -p /var/cache/nginx/client_temp /var/cache/nginx/proxy_temp /var/cache/nginx/fastcgi_temp /var/cache/nginx/uwsgi_temp /var/cache/nginx/scgi_temp && \
chown -R nginx:nginx /var/cache/nginx /var/log/nginx /etc/nginx/conf.d /var/run && \
chmod -R 755 /var/cache/nginx /var/log/nginx /etc/nginx/conf.d /var/run && \
touch /var/run/nginx.pid && \
chown -R nginx:nginx /var/run/nginx.pid
# 切换到非 root 用户(使用镜像内置的 nginx 用户)
USER nginx
# 暴露端口(非特权端口)
EXPOSE 8080
# 启动命令
CMD ["nginx", "-g", "daemon off;"]构建镜像
docker build -t nginx-nonroot:1.0 .测试镜像
# 运行 nginx-nonroot 容器
$ docker run -d -p 8080:8080 nginx-nonroot:1.0
# 访问 nginx-nonroot
$ curl http://localhost:8080
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
</head>
<body>
<h1>Welcome to nginx!</h1>
</body>
</html>
# 查看当前nginx容器,启动命令的用户
nginx@b094f1470b19:/$ id
uid=101(nginx) gid=101(nginx) groups=101(nginx)
# 查看Nginx容器内的所有用户,可以看到 101 对应的就是用户 nginx,也是 Dockerfile 中指定的用户
nginx@b094f1470b19:/$ cat /etc/passwd
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
sync:x:4:65534:sync:/bin:/bin/sync
games:x:5:60:games:/usr/games:/usr/sbin/nologin
man:x:6:12:man:/var/cache/man:/usr/sbin/nologin
lp:x:7:7:lp:/var/spool/lpd:/usr/sbin/nologin
mail:x:8:8:mail:/var/mail:/usr/sbin/nologin
news:x:9:9:news:/var/spool/news:/usr/sbin/nologin
uucp:x:10:10:uucp:/var/spool/uucp:/usr/sbin/nologin
proxy:x:13:13:proxy:/bin:/usr/sbin/nologin
www-data:x:33:33:www-data:/var/www:/usr/sbin/nologin
backup:x:34:34:backup:/var/backups:/usr/sbin/nologin
list:x:38:38:Mailing List Manager:/var/list:/usr/sbin/nologin
irc:x:39:39:ircd:/run/ircd:/usr/sbin/nologin
_apt:x:42:65534::/nonexistent:/usr/sbin/nologin
nobody:x:65534:65534:nobody:/nonexistent:/usr/sbin/nologin
nginx:x:101:101:nginx user:/nonexistent:/bin/false2.2 Pod 以非 root 用户运行
资源清单:non-root-pod.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: default
name: non-root-pod
spec:
replicas: 1
selector:
matchLabels:
app: non-root-pod
template:
metadata:
labels:
app: non-root-pod
spec:
containers:
- name: nginx-nonroot
image: nginx-nonroot:1.0
imagePullPolicy: IfNotPresent
securityContext:
runAsNonRoot: true # 以非root用户运行
runAsUser: 101 # 运行用户 ID, 以非root用户运行,最好指定运行的用户id执行资源清单
# 执行资源清单,创建Pod
$ kubectl apply -f non-root-pod.yaml
# 查看Pod详情
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
non-root-pod-589bdf555b-c6925 1/1 Running 0 57s 171.20.85.214 k8s-node01 <none> <none>
# 进入Pod容器,查看当前容器运行的 User id
$ kubectl exec -it non-root-pod-589bdf555b-c6925 -- /bin/bash
nginx@non-root-pod-589bdf555b-c6925:/$ id
uid=101(nginx) gid=101(nginx) groups=101(nginx)2.3 使用特权模式启动容器
使得容器内的进程以 root 用户运行,并具有宿主机的几乎所有权限(如访问所有设备、挂载文件系统、修改内核参数等)。
容器内的 root 用户几乎等同于宿主机的 root,具有访问宿主机设备(/dev)、文件系统、内核功能等的权限。
注意:privileged: true 仅影响容器,而非整个 Pod。如果 Pod 有多个容器,需要为每个需要特权的容器单独设置。
资源清单: privileged-pod.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: default
name: privileged-pod
spec:
replicas: 1
selector:
matchLabels:
app: privileged-pod
template:
metadata:
labels:
app: privileged-pod
spec:
containers:
- name: nginx-privileged
image: nginx:1.29.0
imagePullPolicy: IfNotPresent
securityContext:
privileged: true # 启用特权模式执行资源清单
# 执行资源清单,创建Pod
$ kubectl apply -f privileged-pod.yaml
# 查看Pod详情
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
privileged-pod-86bdcd8565-lx5ff 1/1 Running 0 74s 171.20.85.216 k8s-node01 <none> <none>
# 进入Pod
$ kubectl exec -it privileged-pod-86bdcd8565-lx5ff -- /bin/bash
# 查看运行容器的用户id
root@privileged-pod-86bdcd8565-lx5ff:/# id
uid=0(root) gid=0(root) groups=0(root)
# 查看 /dev 目录,容器内可以查看到宿主机所有的挂载设备
root@privileged-pod-86bdcd8565-lx5ff:/# ls /dev
autofs dm-1 hidraw0 mcelog ppp sda1 snd tty0 tty15 tty21 tty28 tty34 tty40 tty47 tty53 tty6 tty9 uinput vcs1 vcsa1 vcsu1 vga_arbiter
bsg dma_heap hpet mem ptmx sda2 sr0 tty1 tty16 tty22 tty29 tty35 tty41 tty48 tty54 tty60 ttyS0 urandom vcs2 vcsa2 vcsu2 vhci
bus dri hwrng mqueue pts sda3 stderr tty10 tty17 tty23 tty3 tty36 tty42 tty49 tty55 tty61 ttyS1 usbmon0 vcs3 vcsa3 vcsu3 vhost-net
core fb0 input net random sg0 stdin tty11 tty18 tty24 tty30 tty37 tty43 tty5 tty56 tty62 ttyS2 usbmon1 vcs4 vcsa4 vcsu4 vhost-vsock
cpu fd kmsg null rfkill sg1 stdout tty12 tty19 tty25 tty31 tty38 tty44 tty50 tty57 tty63 ttyS3 usbmon2 vcs5 vcsa5 vcsu5 vmci
cpu_dma_latency full loop-control nvram rtc0 shm termination-log tty13 tty2 tty26 tty32 tty39 tty45 tty51 tty58 tty7 udmabuf userfaultfd vcs6 vcsa6 vcsu6 zero
dm-0 fuse mapper port sda snapshot tty tty14 tty20 tty27 tty33 tty4 tty46 tty52 tty59 tty8 uhid vcs vcsa vcsu vfio2.4 为容器 添加/禁用 linux 内核的功能
使用特权模式启动的容器被赋予了过大的权限,我们可以根据需求给予容器所需的 linux 内核的能力。
在 Kubernetes 中,可以通过配置 Pod 的 securityContext 来为容器添加或禁用 Linux 内核功能(Capabilities)。Linux Capabilities 是 Linux 内核提供的一种机制,将 root 用户的权限细分为多个独立的功能,允许以更精细的方式控制容器进程的权限,而不是简单地以 root 或非 root 用户运行。这种方式可以增强安全性,遵循最小权限原则。
什么是 Linux Capabilities
Linux Capabilities 是 Linux 内核将特权操作拆分成多个独立权限的机制,例如:
- CAP_SYS_ADMIN:允许执行高权限操作(如挂载文件系统、修改系统配置)。
- CAP_NET_ADMIN:允许配置网络(如修改网络接口、设置防火墙规则)。
- CAP_SYS_PTRACE:允许跟踪其他进程(结合 hostPID: true 可用于调试宿主机进程)。
- CAP_CHOWN:允许更改文件的所有者。
- 完整 Capabilities 列表见 Linux man page。
默认情况下:
- 容器以非特权模式运行时,只有部分 Capabilities(例如 CAP_CHOWN、CAP_SETUID 等)。
- 特权模式(privileged: true)授予容器所有 Capabilities,等同于宿主机 root。
- 通过 securityContext.capabilities,可以显式添加(add)或禁用(drop)特定 Capabilities。
资源清单: capabilities-pod.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: default
name: capabilities-pod
spec:
replicas: 1
selector:
matchLabels:
app: capabilities-pod
template:
metadata:
labels:
app: capabilities-pod
spec:
containers:
- name: nginx-capabilities
image: nginx:1.29.0
imagePullPolicy: IfNotPresent
securityContext:
privileged: false # 禁用特权模式
capabilities:
add:
- NET_ADMIN # 添加网络管理能力
- SYS_PTRACE # 添加跟踪进程的能力(适用于 hostPID: true)
drop:
# - CHOWN # 禁用更改文件所有者的能力(Nginx启动需要修改文件所有者,因此不能禁用)
- SYS_ADMIN # 禁用高危的系统管理能力注意:在linux中内核功能通常以CAP_开头,这里需要省略掉
执行资源清单
# 执行资源清单,创建Pod
$ kubectl apply -f capabilities-pod.yaml
# 查看Pod
$ kubectl get pods -w
NAME READY STATUS RESTARTS AGE
capabilities-pod-787896d744-p6ptf 0/1 ContainerCreating 0 12s
capabilities-pod-787896d744-p6ptf 1/1 Running 0 13s2.5 阻止对容器根文件系统的写入
资源清单:read-only-root-filesystem-pod.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: default
name: read-only-root-filesystem-pod
spec:
selector:
matchLabels:
app: read-only-root-filesystem-pod
template:
metadata:
labels:
app: read-only-root-filesystem-pod
spec:
containers:
- name: alpine
image: alpine:3.22.1
imagePullPolicy: IfNotPresent
securityContext:
readOnlyRootFilesystem: true # 只读根文件系统
command: # 容器启动命令
- /bin/sleep
- "3600"
volumeMounts:
- name: read-only-root-filesystem-pod # # 挂载了一个可写的 emptyDir 卷到 /volume 路径,允许容器写入数据
mountPath: /volume
readOnly: false
volumes:
- name: read-only-root-filesystem-pod # 定义一个 emptyDir 卷,是一种临时存储卷,卷在 Pod 创建时分配,初始为空,生命周期与 Pod 绑定(Pod 删除时卷被销毁)
emptyDir: {}执行资源清单
# 执行资源清单,创建Pod
$ kubectl apply -f read-only-root-filesystem-pod.yaml
# 查看Pod
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
read-only-root-filesystem-pod-77bc855c7f-t9nsh 1/1 Running 0 39s
# 进入Pod容器
$ kubectl exec -it read-only-root-filesystem-pod-77bc855c7f-t9nsh -- /bin/sh
# 在根路径下创建文件失败,因为 Pod 禁止了根路径下的文件写入
/ # touch a.txt
touch: a.txt: Read-only file system
# 在挂载路径下创建文件
/ # touch /volume/a.txtreadOnlyRootFilesystem: true
作用:将容器根文件系统(/, 包括 /etc、/usr 等)设为只读。
详情:
- 容器无法在根文件系统上写入文件(如修改 /etc/passwd 或创建 /tmp/testfile),增强安全性。
- 防止恶意或意外修改关键文件,降低容器被攻击的风险。
- 影响:
- 某些应用(如需要写日志或缓存到根文件系统的)可能失败,除非提供可写路径(如通过卷)。
- 在 alpine 镜像中,/bin/sleep 不需要写根文件系统,因此运行正常。
- 注意:与之前的 nginx:1.29.0 配置不同,Nginx 默认需要写日志(/var/log/nginx)和缓存(/var/cache/nginx),启用 readOnlyRootFilesystem: true 可能导致 Nginx 失败,除非将这些路径挂载到可写卷。
如果想将此配置应用于 nginx:1.29.0,需添加多个可写卷:
apiVersion: v1
kind: Pod
metadata:
name: nginx-readonly
spec:
containers:
- name: nginx
image: nginx:1.29.0
securityContext:
readOnlyRootFilesystem: true
volumeMounts:
- name: log-volume
mountPath: /var/log/nginx
readOnly: false
- name: cache-volume
mountPath: /var/cache/nginx
readOnly: false
- name: run-volume
mountPath: /var/run
readOnly: false
volumes:
- name: log-volume
emptyDir: {}
- name: cache-volume
emptyDir: {}
- name: run-volume
emptyDir: {}2.6 容器使用不同用户运行时共享存储卷
当一个 pod 中的两个容器都使用 root 用户运行时,他们之前可以互相读取对方的挂载卷。但是,当我们为每个容器配置其他的启动用户时,
可以会出现一些访问权限的问题。
在 kubernetes 中,可以为 pod 中的容器指定一个 supplemental 组,以允许他们无论通过哪个用户启动容器都可以共享文件。
spec:
securityContext:
# 用户组id设置为555,则创建存储卷时存储卷属于用户ID为555的用户组
fsGroup: 555
# 定义了某个用户所关联的额外的用户组
supplementalGroups:
- 666
- 777
containers:
- name: test-A
image: test-container
imagePullPolicy: IfNotPresent
securityContext:
runAsUser: 01
volumeMounts:
- mountPath: /volume
name: test-volume
readOnly: false
- name: test-B
image: test-container
imagePullPolicy: IfNotPresent
securityContext:
runAsUser: 02
volumeMounts:
- mountPath: /volume
name: test-volume
readOnly: false
volumes:
- name: test-volume
emptyDir: {}在pod级别指定 fsGroup 与 supplementalGroups 属性,然后分别指定两个容器的启动用户为 01、02。然后在启动容器,在容器中执行id命令
可以查看容器的用户和用户组,然后就可以看到两个容器虽然用户不同,但是都属于“555、666、777”这三个组中。
三、Pod Security Admission
1. PodSecurityPolicy 概念(过时)
PodSecurityPolicy 在 kubernetes 中简称为 psp,主要定义了用户能否在 pod 中使用各种安全相关的特性。
当有人调用 api server创建pod时,PodSecurityPolicy 会拿到这个 pod 的信息与自己个规则做比较。如果符合规则,就运行其存入 etcd;否则会被拒绝。
因为是在创建 pod 时校验的,所以修改 psp,不会对已创建的 pod 采取措施。也可以设置默认值,就是用 psp 中配置的默认值替换掉 pod 中的值。
Pod Security Policy 是一个赋予集群管理员控制 Pod 安全规范的内置准入控制器,可以让管理人员控制Pod实例安全的诸多方面,例如禁止采用root权限、防止容器逃逸等等。Pod Security Policy 定义了一组 Pod 运行时必须遵循的条件及相关字段的默认值,Pod 必须满足这些条件才能被成功创建,Pod Security Policy 对象 Spec 包含以下字段也即是 Pod Security Policy 能够控制的方面:
| 控制的角度 | 字段名称 |
|---|---|
| 运行特权容器 | privileged |
| 使用宿主名字空间 | hostPID,hostIPC |
| 使用宿主的网络和端口 | hostNetwork, hostPorts |
| 控制卷类型的使用 | volumes |
| 使用宿主文件系统 | allowedHostPaths |
| 允许使用特定的 FlexVolume 驱动 | allowedFlexVolumes |
| 分配拥有 Pod 卷的 FSGroup 账号 | fsGroup |
| 以只读方式访问根文件系统 | readOnlyRootFilesystem |
| 设置容器的用户和组 ID | runAsUser, runAsGroup, supplementalGroups |
| 限制 root 账号特权级提升 | allowPrivilegeEscalation, defaultAllowPrivilegeEscalation |
| Linux 功能(Capabilities) | defaultAddCapabilities, requiredDropCapabilities, allowedCapabilities |
| 设置容器的 SELinux 上下文 | seLinux |
| 指定容器可以挂载的 proc 类型 | allowedProcMountTypes |
| 指定容器使用的 AppArmor 模版 | annotations |
| 指定容器使用的 seccomp 模版 | annotations |
| 指定容器使用的 sysctl 模版 | forbiddenSysctls,allowedUnsafeSysctls |
其中AppArmor 和seccomp 需要通过给PodSecurityPolicy对象添加注解的方式设定:
seccomp.security.alpha.kubernetes.io/allowedProfileNames: 'docker/default'
seccomp.security.alpha.kubernetes.io/defaultProfileNames: 'docker/default'
apparmor.security.beta.kubernetes.io/allowedProfileNames: 'runtime/default'
apparmor.security.beta.kubernetes.io/defaultProfileNames: 'runtime/default'Pod Security Policy是集群级别的资源,它的使用流程:

由于需要创建 ClusterRole/Role 和 ClusterRoleBinding/RoleBinding 绑定服务账号来使用 PSP,这使得我们不能很容易的看出究竟使用了哪些 PSP,更难看出 Pod 的创建被哪些安全规则限制。
2. 关于 Pod Security Admission
通过对 PodSecurityPolicy 使用,应该也会发现它的问题,例如没有 dry-run 和审计模式、不方便开启和关闭等,并且使用起来也不那么清晰。种种缺陷造成的结果是 PodSecurityPolicy 在 Kubernetes v1.21 被标记为弃用,并且将在 v1.25中被移除,在 kubernets v1.22 中则增加了新特性 Pod Security Admission。
pod security admission 是 kubernetes 内置的一种准入控制器,在 kubernetes v1.23 版本中这一特性门是默认开启的,在v1.22中需要通过 kube-apiserver 参数 --feature-gates="...,PodSecurity=true" 开启。在低于v1.22的 kuberntes 版本中也可以自行安装 Pod Security Admission Webhook。
Pod Security Admission 机制在易用性和灵活性上都有了很大提升,从使用角度有以下三点显著不同:
- 可以在集群中默认开启,只要不设置约束条件就不会触发对 pod 的校验
- 只在命名空间级别生效,可以为不同命名空间通过添加标签的方式设置不同的安全限制
- 根据实践预设了三种安全等级,不需要由用户单独去设置每一项安全条件
为了广泛的覆盖安全应用场景, Pod Security Standards渐进式的定义了三种不同的Pod安全标准策略:
| Profile | 描述 |
|---|---|
| Privileged | 不受限制的策略,提供最大可能范围的权限许可。此策略允许已知的特权提升。 |
| Baseline | 限制性最弱的策略,禁止已知的策略提升。允许使用默认的(规定最少)Pod 配置。 |
| Restricted | 限制性非常强的策略,遵循当前的保护 Pod 的最佳实践。 |
详细内容参见 Pod Security Standards。
3. Pod Security Standards 实施方法
在kubernetes集群中开启了pod security admission特性门之后,就可以通过给namespace设置label的方式来实施Pod Security Standards。其中有三种设定模式可选用:
| Mode | Description |
|---|---|
| enforce | 违反安全标准策略的 Pod 将被拒绝。 |
| audit | 违反安全标准策略触发向审计日志中记录的事件添加审计注释,但其他行为被允许。 |
| warn | 违反安全标准策略将触发面向用户的警告,但其他行为被允许。 |
label设置模板解释:
# 设定模式及安全标准策略等级
# MODE必须是 `enforce`, `audit`或`warn`其中之一。
# LEVEL必须是`privileged`, `baseline`或 `restricted`其中之一
pod-security.kubernetes.io/<MODE>: <LEVEL>
# 此选项是非必填的,用来锁定使用哪个版本的的安全标准
# MODE必须是 `enforce`, `audit`或`warn`其中之一。
# VERSION必须是一个有效的kubernetes minor version(例如v1.23),或者 `latest`
pod-security.kubernetes.io/<MODE>-version: <VERSION>一个 namesapce 可以设定任意种模式或者不同的模式设定不同的安全标准策略。
通过准入控制器配置文件,可以为pod security admission设置默认配置:
apiVersion: apiserver.config.k8s.io/v1
kind: AdmissionConfiguration # 准入控制
plugins:
- name: PodSecurity
configuration:
apiVersion: pod-security.admission.config.k8s.io/v1beta1
kind: PodSecurityConfiguration
# Defaults applied when a mode label is not set.
#
# Level label values must be one of:
# - "privileged" (default)
# - "baseline"
# - "restricted"
#
# Version label values must be one of:
# - "latest" (default)
# - specific version like "v1.23"
defaults: # 默认执行最宽松的检验策略
enforce: "privileged"
enforce-version: "latest" # latest 表示使用最新的 PSS 版本(基于集群版本,例如 Kubernetes 1.25 可能是 v1.25)
audit: "privileged"
audit-version: "latest"
warn: "privileged"
warn-version: "latest"
exemptions:
# 指定免除检查的认证用户名,空数组表示没有用户豁免,所有用户创建的 Pod 都受策略约束。
usernames: []
# 指定免除检查的 RuntimeClass 名称。空数组表示没有 RuntimeClass 豁免,适用于所有运行时(如 containerd、CRI-O)
runtimeClassNames: []
# 指定免除检查的命名空间
namespaces: []pod security admission 可以从 username,runtimeClassName,namespace 三个维度对pod进行安全标准检查的豁免。
4. Pod Security Standards实施演示
- 环境: kubernetes v1.29
运行时的容器面临很多攻击风险,例如容器逃逸,从容器发起资源耗尽型攻击。
4.1 Baseline策略
Baseline策略目标是应用于常见的容器化应用,禁止已知的特权提升,在官方的介绍中此策略针对的是应用运维人员和非关键性应用开发人员,在该策略中包括:
必须禁止共享宿主机命名空间、禁止容器特权、 限制Linux能力、禁止hostPath卷、限制宿主机端口、设定AppArmor、SElinux、Seccomp、Sysctls等。
下面演示设定Baseline策略。
违反Baseline策略存在的风险:
- 特权容器可以看到宿主机设备
- 挂载procfs后可以看到宿主机进程,打破进程隔离
- 可以打破网络隔离
- 挂载运行时socket后可以不受限制的与运行时通信
等等以上风险都可能导致容器逃逸。
创建名为my-baseline-namespace的namespace,并设定enforce和warn两种模式都对应Baseline等级的Pod安全标准策略:
资源清单:
my-baseline-namespace.yamlapiVersion: v1 # 命名空间的 API 版本(固定为 v1) kind: Namespace # 资源类型:命名空间(用于隔离集群资源) metadata: name: my-baseline-namespace # 命名空间名称,Pod 将在此命名空间内运行 labels: # 核心:通过标签配置 Pod 安全策略(PSA 规则) # 强制实施 Baseline 级别的安全标准,所有在该命名空间创建的 Pod 必须符合此标准,否则会被拒绝创建。 # Baseline 标准核心约束(Kubernetes 官方定义): # - 禁止特权容器(privileged: true)。 # - 禁止已知的特权升级路径(如 allowPrivilegeEscalation: true 且 runAsUser: 0)。 # - 允许默认的(相对宽松的)Pod 配置(如允许使用主机网络 hostNetwork、主机 PID hostPID、主机 IPC hostIPC 等,这也是与更严格的 Restricted 级别的主要区别) pod-security.kubernetes.io/enforce: baseline # 指定 enforce 规则所使用的 Kubernetes 版本(此处为 v1.29), 这确保了 PSA 规则仅在指定的 Kubernetes 版本下生效,避免与未来版本的 Kubernetes 发生冲突。 pod-security.kubernetes.io/enforce-version: v1.29 # 当 Pod 不符合 Baseline 标准时,不阻止创建,但会生成警告信息(通过 API 响应或事件日志)。 pod-security.kubernetes.io/warn: baseline # 指定 warn 规则所使用的 Kubernetes 版本,与 enforce-version 保持一致(v1.29),确保警告规则与强制规则基于相同的标准定义 pod-security.kubernetes.io/warn-version: v1.29 # 当同时指定 enforce: baseline 和 warn: baseline 时,Pod 创建流程如下: # - 先检查 enforce 规则: # 若 Pod 完全符合 baseline 标准 → 允许创建,进入下一步。 # 若 Pod 违反 baseline 核心约束(如特权容器、特权升级等)→ 直接拒绝创建,流程终止。 # - 再检查 warn 规则(仅当 enforce 允许创建时): # 若 Pod 存在潜在风险(如使用了不推荐但未被 enforce 禁止的配置)→ 生成警告信息(如 Warning: Pod violates PodSecurity "baseline:v1.29")。 # 若 Pod 完全符合 baseline 标准 → 无警告,Pod 正常运行。执行资源清单:
# 执行资源清单 $ kubectl apply -f my-baseline-namespace.yaml # 查看名称空间 $ kubectl get ns NAME STATUS AGE kube-node-lease Active 40d kube-public Active 40d kube-system Active 40d my-baseline-namespace Active 4s network Active 37d创建pod
创建一个违反baseline策略的pod
资源清单:
fail-hostnamespaces.yamlapiVersion: apps/v1 kind: Deployment metadata: namespace: my-baseline-namespace name: fail-hostnamespaces spec: selector: matchLabels: app: fail-hostnamespaces template: metadata: labels: app: fail-hostnamespaces spec: hostPID: true # 与主机共享PID containers: - name: nginx image: nginx:1.29.0 imagePullPolicy: IfNotPresent securityContext: privileged: true # 启用特权模式执行资源清单
# 提示 容器创建异常 $ kubectl apply -f fail-hostnamespaces.yaml Warning: would violate PodSecurity "baseline:v1.29": host namespaces (hostPID=true), privileged (container "nginx" must not set securityContext.privileged=true) deployment.apps/fail-hostnamespaces created # 只有Deploy,Pod创建失败 $ kubectl get deployment -n my-baseline-namespace NAME READY UP-TO-DATE AVAILABLE AGE fail-hostnamespaces 0/1 0 0 16s创建不违反 baseline 策略的 pod,设定 Pod 的 hostPID=false,securityContext.privileged=false
资源清单:
success-hostnamespaces.yamlapiVersion: apps/v1 kind: Deployment metadata: namespace: my-baseline-namespace name: success-hostnamespaces spec: selector: matchLabels: app: fail-hostnamespaces template: metadata: labels: app: fail-hostnamespaces spec: hostPID: false # 不与主机共享PID containers: - name: nginx image: nginx:1.29.0 imagePullPolicy: IfNotPresent securityContext: privileged: false # 禁用特权模式执行资源清单
# 创建Pod $ kubectl apply -f success-hostnamespaces.yaml # Pod成功启动 $ kubectl get pods -n my-baseline-namespace NAME READY STATUS RESTARTS AGE success-hostnamespaces-759ccb9dcd-x9cp6 1/1 Running 0 12s
4.2 Restricted策略
Restricted 策略目标是实施当前保护 Pod 的最佳实践,在官方介绍中此策略主要针对运维人员和安全性很重要的应用开发人员,以及不太被信任的用户。该策略包含所有的 baseline 策略的内容,额外增加: 限制可以通过 PersistentVolumes 定义的非核心卷类型、禁止(通过 SetUID 或 SetGID 文件模式)获得特权提升、必须要求容器以非 root 用户运行、Containers 不可以将 runAsUser 设置为 0、 容器组必须弃用 ALL capabilities 并且只允许添加 NET_BIND_SERVICE 能力。
restricted 策略进一步的限制在容器内获取 root 权限,linux内核功能。例如针对 kubernetes 网络的中间人攻击需要拥有Linux系统的 CAP_NET_RAW 权限来发送ARP包。
创建名为 my-restricted-namespace 的 namespace,并设定 enforce 和 warn 两种模式都对应 Restricted 等级的 Pod 安全标准策略:
资源清单:
my-restricted-namespace.yamlapiVersion: v1 # 命名空间的 API 版本(固定为 v1) kind: Namespace # 资源类型:命名空间(用于隔离集群资源) metadata: name: my-restricted-namespace # 命名空间名称,Pod 将在此命名空间内运行 labels: # 核心:通过标签配置 Pod 安全策略(PSA 规则) # 强制实施 Baseline 级别的安全标准,所有在该命名空间创建的 Pod 必须符合此标准,否则会被拒绝创建。 pod-security.kubernetes.io/enforce: restricted # 指定 enforce 规则所使用的 Kubernetes 版本(此处为 v1.29), 这确保了 PSA 规则仅在指定的 Kubernetes 版本下生效,避免与未来版本的 Kubernetes 发生冲突。 pod-security.kubernetes.io/enforce-version: v1.29 # 当 Pod 不符合 Restricted 标准时,不阻止创建,但会生成警告信息(通过 API 响应或事件日志)。 pod-security.kubernetes.io/warn: restricted # 指定 warn 规则所使用的 Kubernetes 版本,与 enforce-version 保持一致(v1.29),确保警告规则与强制规则基于相同的标准定义 pod-security.kubernetes.io/warn-version: v1.29执行资源清单
# 创建名称空间 $ kubectl apply -f my-restricted-namespace.yaml namespace/my-restricted-namespace created # 查看 $ kubectl get ns | grep restricted my-restricted-namespace Active 12s创建pod
创建一个违反 Restricted 策略的 pod
资源清单:
fail-restricted-pod.yamlapiVersion: apps/v1 kind: Deployment metadata: namespace: my-restricted-namespace name: fail-restricted spec: selector: matchLabels: app: fail-restricted template: metadata: labels: app: fail-restricted spec: hostPID: true # 与主机共享PID containers: - name: alpine image: alpine:3.22.1 imagePullPolicy: IfNotPresent command: # 容器启动命令 - /bin/sleep - "3600" securityContext: privileged: true # 启用特权模式执行资源清单
# 执行资源清单,提示异常 $ kubectl apply -f fail-restricted-pod.yaml Warning: would violate PodSecurity "restricted:v1.29": host namespaces (hostPID=true), privileged (container "alpine" must not set securityContext.privileged=true), allowPrivilegeEscalation != false (container "alpine" must set securityContext.allowPrivilegeEscalation=false), unrestricted capabilities (container "alpine" must set securityContext.capabilities.drop=["ALL"]), runAsNonRoot != true (pod or container "alpine" must set securityContext.runAsNonRoot=true), seccompProfile (pod or container "alpine" must set securityContext.seccompProfile.type to "RuntimeDefault" or "Localhost") deployment.apps/fail-restricted created # 查看 Deploy,Pod未启动 $ kubectl get deployment -n my-restricted-namespace NAME READY UP-TO-DATE AVAILABLE AGE fail-restricted 0/1 0 0 53s $ kubectl get pods -n my-restricted-namespace No resources found in my-restricted-namespace namespace.创建不违反 Restricted 策略的 pod,设定 Pod 的 securityContext.runAsNonRoot=true,Drop 所有 linux 能力。
资源清单:
success-restricted-pod.yamlapiVersion: apps/v1 kind: Deployment metadata: namespace: my-restricted-namespace name: success-restricted spec: selector: matchLabels: app: success-restricted template: metadata: labels: app: success-restricted spec: hostPID: false # 不与主机共享PID containers: - name: nginx-nonroot image: nginx-nonroot:1.0 imagePullPolicy: IfNotPresent # 容器级别的安全上下文 securityContext: # 以非root启动 runAsNonRoot: true # 运行容器的用户ID runAsUser: 101 # 不允许权限提升 allowPrivilegeEscalation: false # 禁用所有能力 capabilities: drop: - ALL # Pod级别的安全上下文 securityContext: # 不允许以root启动 runAsNonRoot: true # 不允许使用默认的seccomp profile seccompProfile: type: RuntimeDefault执行资源清单
# 执行资源清单,创建Pod $ kubectl apply -f success-restricted-pod.yaml deployment.apps/success-restricted created # 查看Pod 已成功运行 $ kubectl get deployment -n my-restricted-namespace NAME READY UP-TO-DATE AVAILABLE AGE success-restricted 1/1 1 1 28s
四、pod security admission当前局限性
如果你的集群中已经配置PodSecurityPolicy,考虑把它们迁移到pod security admission是需要一定的工作量的。
首先需要考虑当前的pod security admission是否适合你的集群,目前它旨在满足开箱即用的最常见的安全需求,与PSP相比它存在以下差异:
- pod security admission 只是对 pod 进行安全标准的检查,不支持对 pod 进行修改,不能为 pod 设置默认的安全配置。
- pod security admission 只支持官方定义的三种安全标准策略,不支持灵活的自定义安全标准策略。这使得不能完全将 PSP 规则迁移到 pod security admission,需要进行具体的安全规则考量。
- pod security admission 不像 PSP 一样可以与具体的用户进行绑定,只支持豁免特定的用户或者 RuntimeClass 及 namespace。
参考链接
https://support.huaweicloud.com/usermanual-cce/cce_10_0402.html
https://www.cnblogs.com/zhangmingcheng/p/17640118.html
https://www.cnblogs.com/bocloud/p/16107335.html
https://waynerv.com/posts/enable-pod-security-policy-for-cluster/
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 george_95@126.com